Google Cloud Platform + AI Fundamentals - Universidad Austral
Material completo del curso de GCP + AI Fundamentals, Universidad Austral, año 2026
Sobre este repositorio
Este repositorio contiene el material completo del curso GCP + AI Fundamentals de la Universidad Austral, cursado durante el año 2026. El contenido está organizado en formato de libro digital utilizando mdBook, facilitando el estudio y la comprensión de los servicios y arquitecturas de Google Cloud Platform, y los servicios de AI que ofrece.
Criterios de evaluación
- Para aprobar la materia es necesario tener todos los laboratorios aprobados.
- Algunos van a servir como checkpoint
- Parcial teórico multiple choice al final de la materia
- Es promocionable si te sacas 7 o más
Contenido
Clases Teórico-Prácticas
El curso incluye 16 clases que cubren los aspectos fundamentales de GCP:
- Clase 1: Introducción a la computación en la nube y AWS
- Clase 2:
- Clase 3:
- Clase 4:
- Clase 5:
- Clase 6:
- Clase 7:
- Clase 8:
- Clase 9:
- Clase 10:
- Clase 11:
- Clase 12:
- Clase 13:
- Clase 14:
Recursos Adicionales
Labs y prácticas
- Labs documentados:
- Prácticas Terraform:
Estructura del repositorio
aws/
├── book/ # Carpeta generada con el libro compilado
├── src/ # Contenido del curso
│ ├── SUMMARY.md # Índice del libro
│ ├── Clase 1.md # Introducción a la nube
│ ├── images/ # Imágenes extraídas de las presentaciones
│ ├── presentations/ # PDFs originales de las presentaciones
│ └── examples/ # Ejemplos de código
├── book.toml # Configuración de mdBook
└── README.md # Este archivo
Cómo usar este repositorio
Para estudiar
-
Visualizar el libro: Accede al contenido en formato web ejecutando:
mdbook serveLuego abre
http://localhost:3000en tu navegador -
Leer offline: Navega directamente por los archivos
.mden el directoriosrc/ -
Orden recomendado: Sigue la secuencia de clases para un aprendizaje progresivo
Para desarrolladores
-
Requisitos previos: Instalar mdBook
cargo install mdbook -
Generar el libro:
mdbook build
Para contribuir
- Si encontrás errores o mejoras, no dudes en crear un issue o pull request
- Las correcciones y ampliaciones son bienvenidas
Temas principales
Notas importantes
- Este material contiene las presentaciones del curso transcriptas a formato Markdown
- El contenido está actualizado con las prácticas y servicios de GCP vigentes en 2026
- Los PDFs originales se mantienen en
src/presentations/para referencia - Compatible con mdBook para una experiencia de lectura optimizada
Docentes: Rodrigo Pazos, Mora Villa Abrille
Materia: GCP + AI Fundamentals
Universidad: Universidad Austral
Año: 2026
Introducción
Regiones y Zonas
- Los servidores de GCP se manejan por Regiones y Zonas.
- Las regiones se manejan a nivel ciudad. Existen data centers dentro de estas.
- Por el SLA que firmó GCP, en cada región tiene que haber al menos 3 data centers para los servicios ofrecidos: 1 para ofrecer el servicio y 2 de respaldo/réplica
- Las zonas representan un data center concreto; no son todas iguales.
- Difieren a nivel acceso y a nivel latencia
- [Completar]
- Existe lo que se llaman Points of Presence (PoP), que son lugares donde ya hay datos guardados para poder distribuirlos mejor.
- No todos los servidores son iguales: el costo de mantenimiento claramente difiere según la zona geográfica.
- Por lo general, EE.UU es mucho más barato; hasta 10 veces menos que Brasil
- No tiene sentido, estando en Argentina, pagar un servicio en Europa, porque no tenemos un cable físico de fibra que vaya directo; entonces tiene que hacer el salto con latencia agregada a EE.UU o a la región más cercana.
Van a haber más concentración de recursos en los lugares donde más consumo haya, claramente. Por eso hay tantos PoP en EE.UU y en Europa.
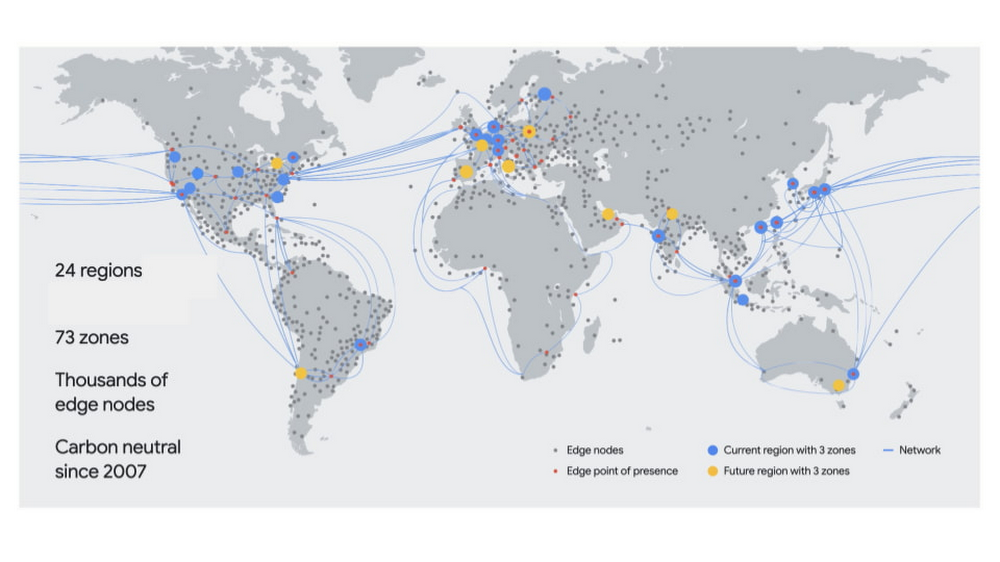
Existen también servicios (principalmente los relacionados al almacenamiento) que pueden ser multi-región (replicándolos en varias regiones), pero incurre en costos extra.
Billing
- Se crea una organización por empresa, que administra todos los departamentos, con fines de gobernanza (acceso, monitoreo, aplicación de políticas)
- Puedo tener el depto. de contabilidad, de ingeniería, cada uno con sus carpetas o folders
- Dentro de la folder, puedo tener proyectos
- Puedo tener el depto. de contabilidad, de ingeniería, cada uno con sus carpetas o folders
- A cada proyecto se le asignan recursos por los que se le va a cobrar a la Billing Account
- Una org puede tener B.A y c/u puede tener proyectos asignados, que pueden a diferentes folders
Formas de interactuar con GCP
- Cloud Platform: interfaz web, que te deja hacer de todo
- Crear y asignar recursos
- Administrar proyectos
- Monitorear uso y controlar costos
- Dentro de esto, existe
Cloud Shell, que es una terminal configurada con todo lo necesario para permitirnos usar el Cloud SDK
- Cloud SDK: nos permite interactuar con la plataforma con cualquier terminal/lenguaje (con sus respectivos clientes)

- En el caso de los lenguajes, wrappean los llamados a las APIs a través de métodos de los clientes
- Cloud APIs: todos los servicios exponen una API que permite que nuestros servicios use la plataforma, incluso si el lenguaje particular no posee un SDK que la wrappee
- Cloud MobileApp: es más que nada para monitoreo y control
Recursos de cómputo

- De derecha a izquierda vamos más desde IaaS hasta PaaS
- También crece el nivel de abstracción que se nos ofrece para interactuar con dichos recursos
Compute Engine
- Alternativa de GCP a EC2 de Amazon o las VM de Azure
- Ofrece máquinas virtuales completamente configurables, con SLAs y precios acordes al mercado
- Se organizan en familias, series y tipos concretos para que sea lo ma2s fácil posible elegir la configuración que se adapte a nuestras necesidades
- Una E2-medium es un tipo concreto
- La familia es General-Purpose
Familias
[Insertar cuadro]
- Storage-optimized: la uso para workloads pesados de almacenamiento
- Guardado de
- Memory-optimized: hasta 12TB de RAM. La uso para trabajos pesados en memoria
- Compute-optimized: tienen un CPU característico y potente. La uso para trabajos de procesamiento pesados.
- Accelerator-optimized: tengo acceso a GPUs de todo tipo.
- Un uso actual muy latente es AI/ML
- General-purpose: te dan buen valor por lo que estás pagando, pero no les pidas mucho
- No son para grandes servidores. Sirven para "iniciar" un negocio
Preguntas
- Diferencias entre N2 y N4, y para qué elegimos c/u
- Qué significa que una máquina tenga en su nombre -lssd? Y qué representan otras versiones de esta variación?
- Tienen un SSD físico local asociado. Si pierdo la máquina, pierdo el disco. No están en rack, por ende no se persiste necesariamente.
- Mover memoria virtual a estos discos es bastante generoso
- Sus variaciones son: normal, standard y high.
- Qué significa que una serie termine en A o en D? Qué implica eso?
- Cambia la arquitectura del procesador
- D es AMD (x86) y A es ARM. Si no tiene modificador, viene un Intel (x86)
- Con ARM se reduce la compatibilidad con ciertos programas, además de que baja el consumo.
- x86 es más barato
- Cambia la arquitectura del procesador
Consumo
- GCP te cobra el CPU cuando la maquina está RUNNING o en PENDING_STOP
- También te cobra por la memoria cuando la máquina está RUNNING, en PENDING_STOP, SUSPENDING o SUSPEND
- Los recursos adjuntables (attachable resources) sobreviven a la máquina si pasa a TERMINATED y nos siguen cobrando por su uso (si corresponde). No puedo dettachear la CPU ni la RAM.
- Ejemplos de attachables:
- Interfaz de Red
- GPU
- Disco (SALVO el
lssd, ya que no es dettachable. No puedo mover un SSD entre máquinas)
- Ejemplos de attachables:
Modelos de aprovisionamiento
- Estándar: reservo la máquina, me dan los recursos y me cobran según el estado de la máquina. Yo lo administro, y puedo determinar cuándo la freno/arranco.
- Spot: te las pueden sacar en cualquier momento con previo aviso, dependiendo de la disponibilidad de los recursos de GCP. "Dame lo que tengas barato y disponible".
- Suelen ser entre 40-50% más barato que las estándar. En el mejor de los casos llega a 92%
- No podés controlar cuándo se paran ni cuándo se eliminan, pero podés recuperar la configuración y el estado de la máquina.
- Se usa bastante para procesos que pueden persistir el estado
- Flex-start: la inversa de Spot, "se levanta cuando puede". Tiene un tiempo máximo de 2hs para levantar el recurso. Es bastante más barata que las estándar.
- Tenés control sobre la máquina.
- Suele ser trabajo de batch-processing, porque podés albergar la máquina por un máximo de 7 días
- Reservation-bound: es para cuando vos sabés que vas a tener un workload por un tiempo prolongado, entonces lo reservás con antelación.
No todas las máquinas pueden acceder a todos los modelos de provisioning
Managed Instance Groups (MIGs)
Son análogos a los grupos de Auto-Scaling de AWS. Escalás horizontalmente en función del consumo, agregando máquinas de manera automática.
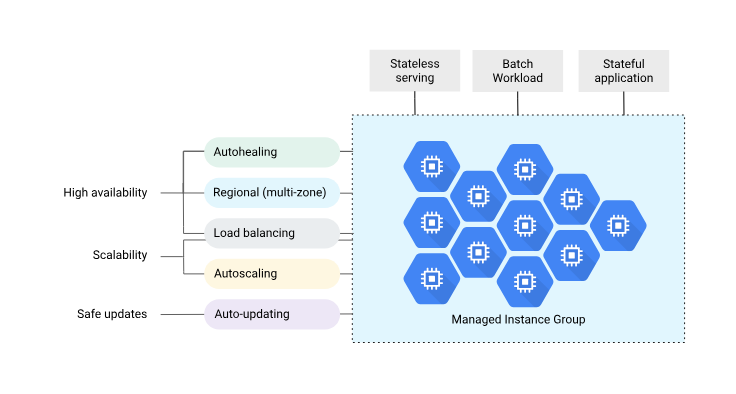
- Ante cierto de uso de CPU o de memoria, levanto una nueva instancia.
- Se define un mínimo y un máximo de máquinas a tener en el MIG
Son máquinas virtuales administradas como un conjunto, siendo todas idénticas. Ofrece:
- Alta disponibilidad: nos ofrece
automatic repairsbasados en la salud de la VM y en la salud de la aplicación. Además, nos da soporte regional para el deployment de las VMs, de forma de que si falla una zona, nuestro servicio sigue funcionando. Con esta estructura podemos usar un load balancer y distribuir la demanda. - Escalabilidad automática: ante ciertos escenarios, el sistema puede levantar instancias nuevas para responder a picos de demanda
- Automatic Updates: podemos hacer
rolloutsde diferentes versiones de nuestra aplicación
Recursos de Cómputo - Continuación
Las VMs y los MIGs toman bastante tiempo...
- Cuando creamos una Vm sen casi todos los casos el provisioning se hace según el mejor esfuerzo (en unga unga, cuando pueda). Configurar y encender la VM también toma tiempo
- Un MIG responde a subas y bajas de demanda con una ventana de por lo menos 10 mins. entre lo que se conoce como el initialization process y el stabilization process
- Por cierta cantidad de tiempo (desde que creo la máquina a partir de la regla de auto-scaling hasta que efectivamente está corriendo), no miro el consumo de recursos para decidir si levanto una instancia nueva
- Puedo estar inicializando la máquina, clonando un repo (según la config), instalando todas las dependencias, ejecutando algún proceso que consuma mucha CPU, etc.
- En esos 10 minutos entre inicialización y estabilización, me cobran ().
- El proceso de inicialización puede tener una duración configurable
- Si . Es decir, no tengo tiempo de estabilización
- Por cierta cantidad de tiempo (desde que creo la máquina a partir de la regla de auto-scaling hasta que efectivamente está corriendo), no miro el consumo de recursos para decidir si levanto una instancia nueva
- Puede haber un caso extremo en donde tengo un servicio que responde una request cada 10 mins.
- En este caso, termino teniendo un MIG o un server dedicado para no hacer nada la mayor parte del tiempo. Es decir, terminás teniendo infraestructura ociosa
No existe el MIG sin instancias. No podés configurar
Para evitar estos problemas de infra ociosa, podemos trasladarnos a una solución serverless.
App Engine 
Es un framework serverless donde montamos nuestro código (con una estructura particular). Nos perdemos ciertos aspectos de configurabilidad (como interactuar con el S.O de la máquina sobre la que está montado nuestro servicio serverless), además de que estamos limitados a ciertos lenguajes.
Es un PaaS, no tengo ni idea de la infraestructura como tal, me abstraigo de muchas de las configuraciones necesarias. A partir de ahora, nos cobran sólo por tiempo de ejecución. Nos administran sólo por tiempo de ejecución.
Cloud Run Functions 
Esta es la solución FaaS (Function as a Service), que también es serverless.
- Corre ante eventos concretos, sobre Cloud Run Service.
- Funcionan con
Functions Framework, un SDK disponible para algunos lenguajes y una cierta estructura (ej: unmain.pyy unrequirements.txten)
- La primera generación era más limitada (límites de vCPU, RAM y timeout de ejecución)
- El timeout era de aprox. 15 minutos.
- Tenían límites de concurrencia
- Las de 2da gen son mucho más óptimas
Cloud Run Service 
- Puedo publicar y compartir imágenes (artefactos) que contienen la config del O.S, alas dependencias y el contexto necesario disponible.
- GCP crea contenedores en una fracción del tiempo porque se ahorra los pasos de provisioning y la inicialización es mucho menos compleja
- Obvio que no todas las imágenes son iguales y GCP tiene mejores prácticas
Ventajas
El container tarda muchísimo menos en levantarse que las VM, por cómo funcionan los contenedores en sí.
- La ventaja de usar containers es la portabilidad/inter-operabilidad: me abstraigo del lenguaje y del ambiente.
- Mismo si mañana me quiero cambiar de Cloud Provider, y el otro también tiene un servicio de Container Running, me llevo mis imágenes y pum para casa
Límites
- El Build System de
tiene que tener acceso a mi imagen
- Las imágenes no pueden pesar más de 10GB
- Hay un límite de consumo de recursos de los containers en ejecución
- Pasado este límite, te cobran
- Si tarda más de en levantarse, no puedo correr el container
- No se pueden usar imágenes basadas sobre
. Sí o sí tiene que ser a partir de alguna distro de
Cobro
Request-based billing
Te cobran por:
- Cantidad de requests
- En los últimos 2 me cobran por el tiempo de inactividad. En cuanto a la CPU, es 10 veces menos que el tiempo de actividad (claramente la CPU es más cara)
Instance-based billing
Existe también el billing basado en instancias, que también te cobra por los últimos 2 anteriores, pero se le agrega el tipo de GPU usado, y su uso por unidad de tiempo.
Almacenamiento
Aclaración respecto del Lab: una Service Account es una cuenta de un usuario artificial que tiene permisos para realizar operaciones de manera automática sobre los distintos recursos de GCP. Operan como un proceso aparte.
Google ofrece una cantidad muy amplia de soluciones de almacenamiento en la nube, pero nos vamos a enfocar en 3 particulares:
- Cloud Storage
- Cloud SQL
- Cloud Firestore
Google File System: es un FS que SÓLO appendea. Es rapidísimo para escribir.
Cloud Storage (GCS) 
(2010)
Es un bucket, una solución object store, parecido a un network file system en la nube, casi "infinito". Usa una interfaz REST.
La diferencia clave con un file system es que los tiempos de lectura a esa escala son incompatibles con este: en un file system real es imposible tener una lectura de esa cantidad de archivos.
En sí, hacen una serie de operaciones sobre los archivos que guardamos:
- Replicación
- Partición y reconstrucción
- Guarda metadata particular del archivo
La interfaz que le dan al usuario la hace ver similar a un FS.
Tiene una durabilidad altísima (11 nueves), haciendo casi imposible que un archivo se pierda a lo largo del tiempo. Se logra justamente con mecanismos de reconstrucción (si mi archivo se rompe o pierde, lo puedo recuperar), replicación geográfica de los datos (al menso 2 zonas, con posibilidad de multiregión) y validaciones constantes de los datos.
Está construido sobre Colossus, sucesor de GFS, permitiendo capacidad infinita. Es administrado por Spanner, garantizando consistencia fuerte de la metadata.
Por el cliente, yo interactúo con la metadata del archivo, no con el archivo en sí. El Blob es todo lo que conoce
Pricing
[Insertar foto]
- Region no te cobra el
outbound data transferporque lees datos dentro de la misma región. - Multi-región es más caro que región, pero más barato que dual-region, porque Google no te deja elegir dónde guardarlo
- Justamente por esto es que tanto acá como en dual-region te cobran por
outbound data transfer, porque te movés afuera de la región - Te cobran la replicación por escribir un archivo
- Justamente por esto es que tanto acá como en dual-region te cobran por
- Elijo zona porque tengo muy poca latencia y muchísimo ancho de banda.
- Este es el más caro justamente por esto.
Tipos de buckets
- Rapid buckets: el zonal, funciona a los piques. Se usa para AI/ML, análisis de datos, etc.
- Standard storage: es ideal para lectura frecuente de un conjunto de archivos.
- Nearline, Coldline, Storage: en este orden, el costo de almacenamiento es cada vez más barato
- El costo de escritura es caro de manera creciente, según el orden anterior
- El compromiso del tiempo de vida es también creciente (30, 90 y 365 días, respectivamente)
Cloud SQL 
(2015)
- Es un servicio de bases de datos relacionales. No lo administrás vos, sino que directamente lo usás.
- Maneja por sí solo:
- Updates
- Parches
- Vertical Scaling
- Auto-resizing del disco on-the-fly
- Por lo general, tiene una disponibilidad alta por el uso de 2 instancias (una primaria y otra standby), una en cada zona.
- Si falla la primaria, la standby la reemplaza. Se van replicando entre sí y cuando la primaria está disponible la vuelve a reemplazar.
- Son 2 discos a nivel zonal, 1 a nivel regional.
- Tiene chequeos automáticos (a nivel Persistent Disk) para revisar qué tan sincronizadas están.
- Tiene backups automatizados periódicos, pudiendo recuperarnos en un click de un
DELETE FROMerróneo. Son incrementales. - Podés asignar réplicas de lectura para alivianar la carga de la instancia primaria.
Firestore 
(2017)
- BD NoSQL orientada a documentos
- Los documentos son JSON con un encodeo binario más eficiente que el JSON común, que pueden pesar hasta 1 MB
- 2 modos de operación: Native y Datastore.
- Native te permite usarlo como BaaS, con límites de 10k escrituras/segundo
- Datastore se usa cuando tenemos un backend que interactúa con nuestra instancia. Sin límites ni features de BaaS
- Solo nos deja hacer queries si tenemos índices para hacerla. El índice de un solo field lo hace automático, pero el complejo hay que armarlo manual
- Es serverless, no te cobran por nada que no sea read/write ni almacenamiento. Las escrituras consideran el mantenimiento de los índices
- Hay costo por GiB
- Los datos se organizan en splits.
- Split es una implementación de sharding pero completamente administrado por Firestore. Nosotros tenemos que elegir la sharding key, y Firestore se encarga de manejar los splits por tamaño o por frecuencia de lectura, además de juntar los datos que se suelen consultar juntos en los mismos splits
- No hay que usar keys secuenciales porque sino corremos el riesgo de sobrecargar nodos
- Autobalancea la carga en un mismo shard, creando subparticiones
- Nos permite escalar prácticamente de forma infinita sin degradación de performance.
- Split es una implementación de sharding pero completamente administrado por Firestore. Nosotros tenemos que elegir la sharding key, y Firestore se encarga de manejar los splits por tamaño o por frecuencia de lectura, además de juntar los datos que se suelen consultar juntos en los mismos splits
Sharding: particionar datos a partir de una clave.
Cloud Shell
Es un recurso análogo al CLI de AWS. Básicamente te permite interactuar con todos los recursos de GCP pero desde una terminal.
Prerrequisitos
- Tener, justamente, la herramienta instalada en tu sistema. Si no la tenés, buscala acá
Ejemplos
He aquí algunos ejemplos de lo que se puede hacer:
Verificar la cuenta activa
gcloud auth list
Listar los proyectos existentes a los cuales la cuenta tiene acceso
gcloud config list project
Setear la región default
gcloud config set compute/region <REGION>
Crear una instancia de una VM en una zona particular
gcloud compute instances create gcelab2 --machine-type e2-medium --zone=$ZONE
- Notar que se crea con el nombre
gcelab2y es de tipoe2-medium
Conectarte por SSH a una instancia ya creada
gcloud compute ssh gcelab2 --zone=<ZONE>
- Hay que pasarle la zona por parámetro
Crear un cluster de máquinas y asignarlas a una Target Pool
Vamos a crear máquinas con los nombres www1, www2 y www3.
gcloud compute instances create www1 \
--zone=$ZONE \
--tags=network-lb-tag \
--machine-type=e2-small \
--image-family=debian-11 \
--image-project=debian-cloud \
--metadata=startup-script='#!/bin/bash
apt-get update
apt-get install apache2 -y
service apache2 restart
echo "
<h3>Web Server: www1</h3>" | tee /var/www/html/index.html'
gcloud compute instances create www2 \
--zone=$ZONE \
--tags=network-lb-tag \
--machine-type=e2-small \
--image-family=debian-11 \
--image-project=debian-cloud \
--metadata=startup-script='#!/bin/bash
apt-get update
apt-get install apache2 -y
service apache2 restart
echo "
<h3>Web Server: www2</h3>" | tee /var/www/html/index.html'
gcloud compute instances create www3 \
--zone=$ZONE \
--tags=network-lb-tag \
--machine-type=e2-small \
--image-family=debian-11 \
--image-project=debian-cloud \
--metadata=startup-script='#!/bin/bash
apt-get update
apt-get install apache2 -y
service apache2 restart
echo "
<h3>Web Server: www3</h3>" | tee /var/www/html/index.html'
Para poder usarlas, tenemos que crear una regla de firewall para poder permitir el tráfico hacia estas máquinas:
gcloud compute firewall-rules create www-firewall-network-lb \
--target-tags network-lb-tag --allow tcp:80
Ahora, necesitamos crear una target pool y asignar esas instancias para que el NLB pueda accederlas
- Crear la target pool
gcloud compute target-pools create www-pool \
--region Region --http-health-check basic-check
- Asignar las instancias a esa pool
gcloud compute target-pools add-instances www-pool \
--instances www1,www2,www3
Por último, para poder interactuar con esas instancias a través del NLB, necesitamos agregar una forwarding rule:
gcloud compute forwarding-rules create www-rule \
--region Region \
--ports 80 \
--address network-lb-ip-1 \
--target-pool www-pool
¿Por qué elijo un Cloud Provider sobre otro?
Se elige uno sobre otro dependiendo de lo que quieras hacer:
- AWS es bastante más generalista. Tiene una oferta más amplia de recursos
- GCP es más orientado a datos (análisis, ML, etc.)
Uno elige profundizar más en una que en otra por ya estar ahí y por la portabilidad que ofrece.
Cuanto más me caso con un proveedor, más me hundo en él, y más costoso es salir
Hay costos de egreso e ingreso al pasar datos entre nubes.
Set Up a NLB (Network Load Balancer)
El Lab trata de crear un cluster de máquinas e2-small y ponerlas detrás de un NLB para poder redirigr el tráfico entre ellas.
Para ello, hay que seguir una serie de pasos, detallados en el subitem Crear un cluster de máquinas y asignarlas a una Target Pool del archivo de Cloud Shell.
Aparece el concepto de Forwarding Rule, que entiendo que son las reglas de mappeo para redirigir tráfico. En el caso del lab, mappea el puerto 80 de la IP del NLB hacia la pool de instancias con el argumento target-pool.
Esta pool de instancias sería el cluster de máquinas entre el cual queremos distribuir el tráfico.
Los Load Balancers no se crean como un componente per se, sino que son un conjunto de 2 componentes.
Recursos identificados
- APIs/servicios involucrados:
Compute Engine,Cloud NAT,Cloud Router,Cloud Load Balancing. - Red y seguridad:
- regla de firewall para health checks (
130.211.0.0/22,35.191.0.0/16). - red
default.
- regla de firewall para health checks (
- Cómputo e imágenes:
- VM base
webserver. - imagen custom
mywebserver. - instance template
mywebserver-template. - managed instance groups multi-región (
us-central1,europe-west1) con autoscaling.
- VM base
- Health checks y balanceo:
- health check
http-health-check. - Application Load Balancer HTTP global (IPv4/IPv6) con backend services sobre MIG.
- health check
- Testing:
- verificación de disponibilidad con
curl. - stress test con
ab(ApacheBench) desde VMstress-test.
- verificación de disponibilidad con
Comandos ejecutados
Crear firewall rule para health checks
Permite que los health checks del load balancer lleguen a las VMs backend por tcp:80.
gcloud compute --project=qwiklabs-gcp-04-1059d35c6e27 firewall-rules create fw-allow-health-checks --direction=INGRESS --priority=1000 --network=default --action=ALLOW --rules=tcp:80 --source-ranges=130.211.0.0/22,35.191.0.0/16 --target-tags=allow-health-checks
Actualizar paquetes en la VM webserver
Prepara la VM base antes de instalar Apache.
sudo apt-get update
Iniciar Apache en la VM webserver
Levanta el servicio HTTP para validar la imagen base.
sudo service apache2 start
Verificar respuesta local de Apache
Confirma que el servidor web responde en localhost.
curl localhost
Habilitar Apache al boot
Deja Apache habilitado para que inicie automáticamente.
sudo update-rc.d apache2 enable
Crear imagen custom desde disco de la VM
Genera mywebserver para usarla en el instance template.
gcloud compute images create mywebserver --project=qwiklabs-gcp-04-1059d35c6e27 --source-disk=webserver --source-disk-zone=us-central1-a --storage-location=us
Crear instance template para los MIG
Define configuración homogénea de las instancias backend sin IP pública.
gcloud compute instance-templates create mywebserver-template --project=qwiklabs-gcp-04-1059d35c6e27 --machine-type=f1-micro --network-interface=network=default,no-address --metadata=enable-oslogin=true --maintenance-policy=MIGRATE --provisioning-model=STANDARD --service-account=425659184878-compute@developer.gserviceaccount.com --scopes=https://www.googleapis.com/auth/devstorage.read_only,https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring.write,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly,https://www.googleapis.com/auth/trace.append --tags=allow-health-checks --create-disk=auto-delete=yes,boot=yes,device-name=mywebserver-template,image=projects/qwiklabs-gcp-04-1059d35c6e27/global/images/mywebserver,mode=rw,size=10,type=pd-balanced --no-shielded-secure-boot --shielded-vtpm --shielded-integrity-monitoring --reservation-affinity=any
Crear health check TCP para los MIG
Define el check usado para determinar backends saludables.
gcloud beta compute health-checks create tcp http-health-check --project=qwiklabs-gcp-04-1059d35c6e27 --port=80 --proxy-header=NONE --no-enable-logging --check-interval=5 --timeout=5 --unhealthy-threshold=2 --healthy-threshold=2
Definir la IP del Load Balancer para pruebas
Guarda la IP pública del LB en una variable de entorno.
LB_IP=34.111.70.232
Esperar hasta que el LB responda tráfico HTTP
Hace polling con curl hasta obtener respuesta válida.
while [ -z "$RESULT" ] ;
do
echo "Waiting for Load Balancer";
sleep 5;
RESULT=$(curl -m1 -s $LB_IP | grep Apache);
done
Definir variable de entorno con IP/URL del LB
Prepara la VM de stress test para enviar tráfico al balanceador.
export LB_IP=http://34.111.70.232/
Redefinir variable LB_IP en formato host
Normaliza la variable para usarla con ab.
export LB_IP=34.111.70.232
Verificar variable LB_IP
Confirma que la variable quedó seteada correctamente.
echo $LB_IP
Ejecutar stress test con ApacheBench
Simula alta carga para observar balanceo y autoscaling.
ab -n 500000 -c 1000 http://$LB_IP/
Recursos identificados
- Servicio principal:
Cloud Storage. - Recursos de storage:
- bucket principal (
BUCKET_NAME_1). - objetos (
setup.html,setup2.html,setup3.htmly versiones).
- bucket principal (
- Seguridad y acceso:
- ACLs de objeto (
private,AllUsers:R). - CSEK (Customer-supplied encryption keys) vía
.boto. - rotación de claves CSEK.
- ACLs de objeto (
- Gobierno del dato:
- lifecycle policy (delete por edad).
- versioning de bucket.
- Operaciones de datos:
- sincronización recursiva con
gsutil rsync.
- sincronización recursiva con
Comandos ejecutados
Definir nombre de bucket en variable
Se usa para reutilizar el nombre del bucket durante todo el lab.
export BUCKET_NAME_1=<enter bucket name 1 here>
Verificar variable del bucket
Se usa para confirmar que BUCKET_NAME_1 quedó bien seteada.
echo $BUCKET_NAME_1
Descargar archivo de muestra
Se usa para bajar setup.html y trabajar con objetos de prueba.
curl \
https://hadoop.apache.org/docs/current/\
hadoop-project-dist/hadoop-common/\
ClusterSetup.html > setup.html
Crear copias locales del archivo
Se usa para tener múltiples objetos para pruebas de cifrado/versionado.
cp setup.html setup2.html
cp setup.html setup3.html
Subir archivo al bucket
Se usa para cargar el primer objeto al bucket.
gcloud storage cp setup.html gs://$BUCKET_NAME_1/
Exportar ACL actual del objeto
Se usa para inspeccionar permisos actuales del objeto.
gsutil acl get gs://$BUCKET_NAME_1/setup.html > acl.txt
cat acl.txt
Forzar ACL privada en el objeto
Se usa para restringir acceso a modo privado y validar resultado.
gsutil acl set private gs://$BUCKET_NAME_1/setup.html
gsutil acl get gs://$BUCKET_NAME_1/setup.html > acl2.txt
cat acl2.txt
Hacer objeto público por ACL
Se usa para habilitar lectura pública del objeto.
gsutil acl ch -u AllUsers:R gs://$BUCKET_NAME_1/setup.html
gsutil acl get gs://$BUCKET_NAME_1/setup.html > acl3.txt
cat acl3.txt
Borrar archivo local
Se usa para validar recuperación desde bucket.
rm setup.html
Listar archivos locales
Se usa para verificar que setup.html fue eliminado.
ls
Recuperar objeto desde bucket
Se usa para copiar nuevamente setup.html al entorno local.
gcloud storage cp gs://$BUCKET_NAME_1/setup.html setup.html
Generar clave CSEK
Se usa para crear una clave AES-256 base64 para cifrado del lado cliente.
python3 -c 'import base64; import os; print(base64.encodebytes(os.urandom(32)))'
Abrir configuración gsutil (.boto)
Se usa para configurar encryption_key y/o decryption_key.
ls -al
nano .boto
Subir archivos cifrados con CSEK
Se usa para cargar objetos que queden cifrados con la clave configurada.
gsutil cp setup2.html gs://$BUCKET_NAME_1/
gsutil cp setup3.html gs://$BUCKET_NAME_1/
Borrar archivos locales de setup
Se usa para forzar nueva descarga y validar descifrado.
rm setup*
Descargar archivos setup desde bucket
Se usa para recuperar y validar acceso a objetos cifrados.
gsutil cp gs://$BUCKET_NAME_1/setup* ./
Mostrar contenido de archivos recuperados
Se usa para comprobar que los archivos se pudieron descifrar.
cat setup.html
cat setup2.html
cat setup3.html
Abrir .boto para rotación de claves
Se usa para mover clave vieja a decryption_key1 y preparar nueva clave.
nano .boto
Generar nueva clave CSEK para rotación
Se usa para actualizar encryption_key.
python3 -c 'import base64; import os; print(base64.encodebytes(os.urandom(32)))'
Reabrir .boto para setear la nueva clave
Se usa para pegar nueva encryption_key.
nano .boto
Reescribir objeto para rotar cifrado
Se usa para volver a cifrar setup2.html con la nueva clave.
gsutil rewrite -k gs://$BUCKET_NAME_1/setup2.html
Abrir .boto para desactivar decryption_key vieja
Se usa para simular cierre de rotación de claves.
nano .boto
Descargar objeto ya rotado
Se usa para validar que setup2.html sigue siendo legible.
gsutil cp gs://$BUCKET_NAME_1/setup2.html recover2.html
Intentar descargar objeto no rotado
Se usa para demostrar fallo esperado en objeto con clave vieja.
gsutil cp gs://$BUCKET_NAME_1/setup3.html recover3.html
Ver lifecycle policy actual
Se usa para inspeccionar la configuración vigente del bucket.
gsutil lifecycle get gs://$BUCKET_NAME_1
Crear archivo de policy lifecycle
Se usa para definir reglas de borrado automático por edad.
nano life.json
Aplicar lifecycle policy al bucket
Se usa para activar la política definida en life.json.
gsutil lifecycle set life.json gs://$BUCKET_NAME_1
Verificar lifecycle policy aplicada
Se usa para confirmar que la policy quedó activa.
gsutil lifecycle get gs://$BUCKET_NAME_1
Consultar estado de versioning
Se usa para verificar si el bucket tiene versionado habilitado.
gsutil versioning get gs://$BUCKET_NAME_1
Habilitar versioning en bucket
Se usa para conservar versiones históricas de objetos.
gsutil versioning set on gs://$BUCKET_NAME_1
Revalidar versioning
Se usa para confirmar que el versionado quedó encendido.
gsutil versioning get gs://$BUCKET_NAME_1
Revisar tamaño del archivo actual
Se usa como referencia antes de crear nuevas versiones.
ls -al setup.html
Editar archivo para cambiar contenido
Se usa para generar una nueva versión del objeto.
nano setup.html
Subir versión nueva del objeto
Se usa para crear una versión adicional en el bucket.
gcloud storage cp -v setup.html gs://$BUCKET_NAME_1
Editar nuevamente archivo para otra versión
Se usa para producir una tercera variante del objeto.
nano setup.html
Subir otra versión del objeto
Se usa para tener varias versiones recuperables.
gcloud storage cp -v setup.html gs://$BUCKET_NAME_1
Listar todas las versiones del objeto
Se usa para obtener el VERSION_NAME histórico.
gcloud storage ls -a gs://$BUCKET_NAME_1/setup.html
Guardar versión objetivo en variable
Se usa para facilitar la descarga de una versión específica.
export VERSION_NAME=<Enter VERSION name here>
Verificar VERSION_NAME
Se usa para confirmar que la variable contiene el path versionado completo.
echo $VERSION_NAME
Recuperar versión histórica del objeto
Se usa para restaurar una versión antigua en recovered.txt.
gcloud storage cp $VERSION_NAME recovered.txt
Comparar tamaños entre versión actual y recuperada
Se usa para verificar que se recuperó contenido anterior.
ls -al setup.html
ls -al recovered.txt
Crear estructura de directorios de prueba
Se usa para preparar un escenario de sincronización recursiva.
mkdir firstlevel
mkdir ./firstlevel/secondlevel
cp setup.html firstlevel
cp setup.html firstlevel/secondlevel
Sincronizar directorio local al bucket
Se usa para copiar recursivamente estructura y archivos.
gsutil rsync -r ./firstlevel gs://$BUCKET_NAME_1/firstlevel
Listado recursivo de objetos sincronizados
Se usa para comparar estructura en bucket vs local.
gcloud storage ls -r gs://$BUCKET_NAME_1/firstlevel
Salir de Cloud Shell
Se usa para terminar la sesión del lab.
exit
Recursos identificados
- Servicio principal:
Cloud SQL(instancia MySQLwordpress-db). - Red y conectividad:
- conexión por proxy (
cloud_sql_proxy) sobre127.0.0.1:3306. - conexión por
Private IP(internal IP de Cloud SQL).
- conexión por proxy (
- Compute Engine:
- VM
wordpress-proxy. - VM
wordpress-private-ip.
- VM
- Base de datos:
- DB
wordpress.
- DB
- Aplicación:
- WordPress conectado a Cloud SQL por dos métodos (proxy e internal IP).
Comandos ejecutados
Descargar Cloud SQL Auth Proxy y dar permisos de ejecución
Se usa para instalar el binario del proxy en la VM wordpress-proxy.
wget https://dl.google.com/cloudsql/cloud_sql_proxy.linux.amd64 -O cloud_sql_proxy && chmod +x cloud_sql_proxy
Guardar el connection name de Cloud SQL en variable
Se usa para reutilizar el identificador de instancia en los comandos del proxy.
export SQL_CONNECTION=[SQL_CONNECTION_NAME]
Verificar la variable SQL_CONNECTION
Se usa para confirmar que la variable quedó correctamente seteada.
echo $SQL_CONNECTION
Iniciar Cloud SQL Proxy en background
Se usa para abrir un túnel local seguro hacia la instancia Cloud SQL.
./cloud_sql_proxy -instances=$SQL_CONNECTION=tcp:3306 &
Obtener external IP de la VM desde metadata server
Se usa para abrir WordPress en el navegador y completar configuración inicial.
curl -H "Metadata-Flavor: Google" http://169.254.169.254/computeMetadata/v1/instance/network-interfaces/0/access-configs/0/external-ip && echo
Recursos identificados
- APIs:
artifactregistry.googleapis.com,cloudfunctions.googleapis.com,cloudbuild.googleapis.com,eventarc.googleapis.com,run.googleapis.com,logging.googleapis.com,pubsub.googleapis.com. - Cloud Run Functions (gen2):
nodejs-http-function(HTTP)nodejs-storage-function(evento de Cloud Storage)gce-vm-labeler(evento de Cloud Audit Logs)hello-world-colored(HTTP con variable de entorno)slow-function(HTTP, prueba de cold start)slow-concurrent-function(HTTP, min instances y concurrencia)
- Cloud Storage bucket para eventos:
gcf-gen2-storage-<PROJECT_ID>. - IAM bindings:
roles/pubsub.publisherpara la Cloud Storage service account.roles/eventarc.eventReceiverpara la Compute Engine default service account.
- Compute Engine VM de prueba:
instance-1(creacion y borrado para test de Audit Logs). - Cloud Run service revisions (via consola) para pruebas de color, min instances y concurrencia.
Comandos ejecutados
Verificar la cuenta activa en Cloud Shell
Se usa para confirmar con que identidad estas autenticado.
gcloud auth list
Verificar el proyecto activo
Se usa para validar el PROJECT_ID que usara gcloud.
gcloud config list project
Habilitar APIs necesarias del lab
Se usa para activar servicios base de Cloud Run Functions, build, eventos y logs.
gcloud services enable \
artifactregistry.googleapis.com \
cloudfunctions.googleapis.com \
cloudbuild.googleapis.com \
eventarc.googleapis.com \
run.googleapis.com \
logging.googleapis.com \
pubsub.googleapis.com
Habilitar Gemini for Google Cloud API
Se usa para permitir Gemini Code Assist en el entorno del lab.
gcloud services enable cloudaicompanion.googleapis.com
Crear carpeta base de la funcion HTTP
Se usa para inicializar el directorio de trabajo y entrar en el.
mkdir ~/hello-http && cd $_
Crear archivo de codigo de la funcion HTTP
Se usa para crear index.js.
touch index.js
Crear manifiesto de dependencias de la funcion HTTP
Se usa para crear package.json.
touch package.json
Desplegar funcion HTTP en Cloud Run Functions (gen2)
Se usa para publicar la funcion nodejs-http-function.
gcloud functions deploy nodejs-http-function \
--gen2 \
--runtime nodejs22 \
--entry-point helloWorld \
--source . \
--region {{{project_0.default_region|Region}}} \
--trigger-http \
--timeout 600s \
--max-instances 1
Probar la funcion HTTP desplegada
Se usa para invocar la funcion y validar la respuesta.
gcloud functions call nodejs-http-function \
--gen2 \
--region {{{project_0.default_region|Region}}}
Obtener el numero de proyecto
Se usa para guardar el PROJECT_NUMBER en una variable.
PROJECT_NUMBER=$(gcloud projects list --filter="project_id:{{{ project_0.project_id | PROJECT_ID }}}" --format='value(project_number)')
Obtener service account de Cloud Storage para KMS
Se usa para guardar la cuenta de servicio requerida en una variable.
SERVICE_ACCOUNT=$(gsutil kms serviceaccount -p $PROJECT_NUMBER)
Asignar rol pubsub.publisher a Cloud Storage
Se usa para permitir que eventos de Cloud Storage publiquen en Pub/Sub.
gcloud projects add-iam-policy-binding {{{ project_0.project_id | PROJECT_ID }}} \
--member serviceAccount:$SERVICE_ACCOUNT \
--role roles/pubsub.publisher
Crear carpeta base de la funcion de Cloud Storage
Se usa para inicializar el directorio de trabajo y entrar en el.
mkdir ~/hello-storage && cd $_
Crear archivo de codigo de la funcion de Cloud Storage
Se usa para crear index.js.
touch index.js
Crear manifiesto de dependencias de la funcion de Cloud Storage
Se usa para crear package.json.
touch package.json
Definir nombre del bucket en variable
Se usa para reutilizar el bucket en comandos posteriores.
BUCKET="gs://gcf-gen2-storage-{{{ project_0.project_id | PROJECT_ID }}}"
Crear bucket de Cloud Storage
Se usa para generar eventos que disparen la funcion.
gsutil mb -l {{{project_0.default_region|Region}}} $BUCKET
Desplegar funcion disparada por bucket
Se usa para publicar nodejs-storage-function con trigger de Cloud Storage.
gcloud functions deploy nodejs-storage-function \
--gen2 \
--runtime nodejs22 \
--entry-point helloStorage \
--source . \
--region {{{project_0.default_region|Region}}} \
--trigger-bucket $BUCKET \
--trigger-location {{{project_0.default_region|Region}}} \
--max-instances 1
Crear archivo de prueba local
Se usa para tener un objeto a subir al bucket.
echo "Hello World" > random.txt
Subir archivo al bucket
Se usa para disparar el evento de Cloud Storage.
gsutil cp random.txt $BUCKET/random.txt
Leer logs de la funcion de Cloud Storage
Se usa para confirmar que la funcion recibio el CloudEvent.
gcloud functions logs read nodejs-storage-function \
--region {{{project_0.default_region|Region}}} \
--gen2 \
--limit=100 \
--format "value(log)"
Asignar rol eventarc.eventReceiver a Compute Engine default SA
Se usa para habilitar recepcion de eventos de Audit Logs via Eventarc.
gcloud projects add-iam-policy-binding {{{ project_0.project_id | PROJECT_ID }}} \
--member serviceAccount:$PROJECT_NUMBER-compute@developer.gserviceaccount.com \
--role roles/eventarc.eventReceiver
Ir al home de Cloud Shell
Se usa para posicionarse donde se clonara el repositorio.
cd ~
Clonar repositorio de ejemplo de Eventarc
Se usa para obtener el codigo de gce-vm-labeler.
git clone https://github.com/GoogleCloudPlatform/eventarc-samples.git
Entrar al directorio del ejemplo nodejs
Se usa para desplegar desde el path correcto.
cd ~/eventarc-samples/gce-vm-labeler/gcf/nodejs
Desplegar funcion basada en Cloud Audit Logs
Se usa para etiquetar VMs creadas segun filtros de evento.
gcloud functions deploy gce-vm-labeler \
--gen2 \
--runtime nodejs22 \
--entry-point labelVmCreation \
--source . \
--region {{{project_0.default_region|Region}}} \
--trigger-event-filters="type=google.cloud.audit.log.v1.written,serviceName=compute.googleapis.com,methodName=beta.compute.instances.insert" \
--trigger-location {{{project_0.default_region|Region}}} \
--max-instances 1
Describir VM para verificar etiqueta creator
Se usa para comprobar que la funcion aplico labels.
gcloud compute instances describe instance-1 --zone {{{project_0.default_zone | "Zone"}}}
Eliminar VM de prueba
Se usa para limpieza de recursos.
gcloud compute instances delete instance-1 --zone {{{project_0.default_zone | "Zone"}}}
Crear carpeta base para funcion con revisiones
Se usa para preparar proyecto Python.
mkdir ~/hello-world-colored && cd $_
Crear codigo de funcion Python
Se usa para crear main.py.
touch main.py
Crear archivo de dependencias Python
Se usa para crear requirements.txt.
touch requirements.txt
Definir variable de color inicial
Se usa para pasarla como env var en el deploy.
COLOR=orange
Desplegar revision inicial de funcion coloreada
Se usa para publicar hello-world-colored con color naranja.
gcloud functions deploy hello-world-colored \
--gen2 \
--runtime python311 \
--entry-point hello_world \
--source . \
--region {{{project_0.default_region|Region}}} \
--trigger-http \
--allow-unauthenticated \
--update-env-vars COLOR=$COLOR \
--max-instances 1
Crear carpeta base para prueba de cold start
Se usa para preparar proyecto Go.
mkdir ~/min-instances && cd $_
Crear codigo de funcion Go
Se usa para crear main.go.
touch main.go
Crear modulo Go
Se usa para crear go.mod.
touch go.mod
Desplegar funcion lenta sin min instances
Se usa para observar cold start inicial.
gcloud functions deploy slow-function \
--gen2 \
--runtime go123 \
--entry-point HelloWorld \
--source . \
--region {{{project_0.default_region|Region}}} \
--trigger-http \
--allow-unauthenticated \
--max-instances 4
Primera invocacion de la funcion lenta
Se usa para medir latencia con cold start.
gcloud functions call slow-function \
--gen2 \
--region {{{project_0.default_region|Region}}}
Segunda invocacion de la funcion lenta
Se usa para comparar latencia posterior al warm-up.
gcloud functions call slow-function \
--gen2 \
--region {{{project_0.default_region|Region}}}
Instalar herramienta de carga hey
Se usa para enviar requests concurrentes.
sudo apt install hey
Obtener URL de la funcion lenta
Se usa para guardarla en SLOW_URL.
SLOW_URL=$(gcloud functions describe slow-function --region {{{project_0.default_region|Region}}} --gen2 --format="value(serviceConfig.uri)")
Ejecutar prueba de concurrencia sin ajuste de concurrency
Se usa para observar tiempos altos por escalado/cold start.
hey -n 10 -c 10 $SLOW_URL
Eliminar servicio slow-function
Se usa para limpiar antes del siguiente despliegue.
gcloud run services delete slow-function --region {{{project_0.default_region | "Region"}}}
Desplegar funcion con min instances para prueba de concurrency
Se usa para publicar slow-concurrent-function.
gcloud functions deploy slow-concurrent-function \
--gen2 \
--runtime go123 \
--entry-point HelloWorld \
--source . \
--region {{{project_0.default_region|Region}}} \
--trigger-http \
--allow-unauthenticated \
--min-instances 1 \
--max-instances 4
Obtener URL de la funcion concurrente
Se usa para guardarla en SLOW_CONCURRENT_URL.
SLOW_CONCURRENT_URL=$(gcloud functions describe slow-concurrent-function --region {{{project_0.default_region|Region}}} --gen2 --format="value(serviceConfig.uri)")
Ejecutar prueba de concurrencia con servicio ajustado
Se usa para validar mejora de tiempos con concurrencia alta.
hey -n 10 -c 10 $SLOW_CONCURRENT_URL
Recursos identificados
- APIs:
run.googleapis.com(y uso depubsub.googleapis.comen operaciones de Pub/Sub). - Cloud Run services:
store-service(público),order-service(privado). - Pub/Sub: topic
ORDER_PLACED, subscription pushorder-service-sub. - IAM service account:
pubsub-cloud-run-invoker. - IAM bindings:
roles/run.invokersobreorder-servicepara la service account invocadora.roles/iam.serviceAccountTokenCreatorpara la Pub/Sub service agent del proyecto.
- Integración push autenticada Pub/Sub -> Cloud Run con
--push-auth-service-account.
Comandos ejecutados
Verificar la cuenta activa en Cloud Shell
Se usa para confirmar con que identidad estas autenticado.
gcloud auth list
Verificar el proyecto activo
Se usa para validar el PROJECT_ID que usara gcloud.
gcloud config list project
Habilitar la API de Cloud Run
Se usa para poder desplegar servicios en Cloud Run.
gcloud services enable run.googleapis.com
Definir region en variable de entorno
Se usa para reutilizar la misma region en todo el lab.
LOCATION={{{project_0.default_region|REGION}}}
Configurar region por defecto de gcloud
Se usa para evitar pasar la region manualmente en cada comando.
gcloud config set compute/region $LOCATION
Desplegar servicio publico store-service
Se usa para publicar el productor accesible sin autenticacion.
gcloud run deploy store-service \
--image gcr.io/qwiklabs-resources/gsp724-store-service \
--region $LOCATION \
--allow-unauthenticated
Desplegar servicio privado order-service
Se usa para publicar el consumidor solo para cuentas autenticadas.
gcloud run deploy order-service \
--image gcr.io/qwiklabs-resources/gsp724-order-service \
--region $LOCATION \
--no-allow-unauthenticated
Crear topic de Pub/Sub
Se usa para recibir eventos de ordenes creadas.
gcloud pubsub topics create ORDER_PLACED
Crear service account invocadora
Se usa para que Pub/Sub pueda invocar order-service.
gcloud iam service-accounts create pubsub-cloud-run-invoker \
--display-name "Order Initiator"
Listar service account creada
Se usa para confirmar que la cuenta existe.
gcloud iam service-accounts list --filter="Order Initiator"
Asignar rol Cloud Run Invoker al service account
Se usa para permitir invocar order-service.
gcloud run services add-iam-policy-binding order-service \
--region $LOCATION \
--member=serviceAccount:pubsub-cloud-run-invoker@$GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.com \
--role=roles/run.invoker \
--platform managed
Obtener numero de proyecto
Se usa para guardarlo en la variable PROJECT_NUMBER.
PROJECT_NUMBER=$(gcloud projects list \
--filter="qwiklabs-gcp" \
--format='value(PROJECT_NUMBER)')
Permitir creacion de tokens para Pub/Sub
Se usa para que la service account administrada de Pub/Sub firme tokens.
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \
--member=serviceAccount:service-$PROJECT_NUMBER@gcp-sa-pubsub.iam.gserviceaccount.com \
--role=roles/iam.serviceAccountTokenCreator
Obtener URL de order-service
Se usa para guardarla en ORDER_SERVICE_URL.
ORDER_SERVICE_URL=$(gcloud run services describe order-service \
--region $LOCATION \
--format="value(status.address.url)")
Crear suscripcion push hacia order-service
Se usa para conectar el topic con el endpoint privado usando autenticacion.
gcloud pubsub subscriptions create order-service-sub \
--topic ORDER_PLACED \
--push-endpoint=$ORDER_SERVICE_URL \
--push-auth-service-account=pubsub-cloud-run-invoker@$GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.com
Obtener URL de store-service
Se usa para guardarla en STORE_SERVICE_URL.
STORE_SERVICE_URL=$(gcloud run services describe store-service \
--region $LOCATION \
--format="value(status.address.url)")
Enviar payload de prueba al productor
Se usa para publicar una orden y validar el flujo completo.
curl -X POST -H "Content-Type: application/json" -d @test.json $STORE_SERVICE_URL
Prácticas de infraestructura (src/examples)
En esta carpeta vas a encontrar prácticas de infraestructura pensadas para acompañar los labs del curso, con foco en Terraform y buenas prácticas (variables reutilizables, outputs, estructura clara por caso de uso, etc.).
Qué incluye hoy
cloud-run/cloud-run-functions-qwik-start/- Ejemplo Terraform basado en el lab Cloud Run Functions Qwik Start.
- Cubre APIs, Cloud Run Functions (gen2), triggers y recursos asociados.
cloud-run/pubsub-with-cloud-run/- Ejemplo Terraform basado en el lab Cloud Pub Sub With Cloud Run.
- Cubre servicios Cloud Run, topic/subscription de Pub/Sub, service account e IAM.
load-balancer/create-nlb/- Ejemplo Terraform para crear un Network Load Balancer.
load-balancer/application-load-balancer/- Ejemplo Terraform para un Application Load Balancer con autoscaling (MIG + autoscaler).
storage/buckets/- Ejemplo Terraform basado en el lab Cloud Storage (versioning, lifecycle y objetos de muestra).
storage/cloud-sql/- Ejemplo Terraform basado en el lab Implementing Cloud SQL (Cloud SQL, peering privado y VMs de demo).
virtual-machines/create-vm/- Ejemplo Terraform para crear una VM en Compute Engine.
Cómo usar estas prácticas
- Entrá a la carpeta del ejemplo que quieras.
- Inicializá Terraform con
terraform init. - Definí variables (por ejemplo en
terraform.tfvars). - Revisá cambios con
terraform plan. - Aplicá con
terraform apply.
Recomendaciones
- No hardcodear
project_id, región o nombres sensibles: usá variables. - Usar
terraform fmty, si podés,terraform validateantes de aplicar. - Si estás probando en un proyecto temporal, al terminar corré
terraform destroy.
Carpeta remota en GitHub
Terraform Example: Application Load Balancer with Autoscaling
Este ejemplo implementa una versión Terraform del lab Application Load Balancer with Autoscaling.
Qué crea
- Firewall rule para health checks.
- Cloud Router + Cloud NAT en las regiones de backend.
- Instance template para servidores web.
- 2 Managed Instance Groups (uno en
us-central1y otro eneurope-west1). - Autoscaler para cada MIG.
- Application Load Balancer HTTP global (
EXTERNAL_MANAGED) con:- backend service
- URL map
- target HTTP proxy
- forwarding rule IPv4
- forwarding rule IPv6 opcional
Uso rápido
- Inicializá:
terraform init
- Definí variables en
terraform.tfvars:
project_id = "tu-project-id"
default_region = "us-central1"
network_name = "default"
- Plan y apply:
terraform plan
terraform apply
Notas
- El lab original usa una imagen custom (
mywebserver). Este ejemplo usa una imagen Debian por defecto + startup script. - Si querés replicar más fielmente el lab, podés cambiar
instance_imagepor tu imagen custom.
Terraform Example: Cloud Storage Lab
Este ejemplo implementa una práctica Terraform basada en el lab Cloud Storage.
Qué crea
- Bucket de Cloud Storage con nombre único global.
- Versioning habilitable (
enable_versioning). - Lifecycle rule para borrar objetos por edad (
lifecycle_delete_age_days). - Objetos de ejemplo (
setup.html,setup2.html,setup3.html) opcionales. - Opción de acceso público de lectura por IAM (
make_sample_public).
Uso rápido
- Inicializá:
terraform init
- Definí variables en
terraform.tfvars:
project_id = "tu-project-id"
region = "us-central1"
bucket_name_prefix = "cloud-storage-lab"
enable_versioning = true
lifecycle_delete_age_days = 31
upload_sample_objects = true
make_sample_public = false
- Plan y apply:
terraform plan
terraform apply
Notas
- El lab original usa ACLs y CSEK operados manualmente con
gsutil+.boto. - Este ejemplo prioriza prácticas IaC estándar con IAM y configuración declarativa del bucket.
- Si necesitás reproducir CSEK manual exacto, conviene mantenerlo en un paso operativo fuera de Terraform.
Terraform Example: Cloud SQL
Este ejemplo implementa una práctica Terraform basada en el lab Implementing Cloud SQL.
Qué crea
- APIs necesarias:
compute,sqladmin,servicenetworking. - Peering privado para Cloud SQL (
google_service_networking_connection). - Instancia Cloud SQL MySQL (
wordpress-db) con:- Public IP habilitada.
- Private IP en la VPC seleccionada.
- Base de datos
wordpress. - 2 VMs de apoyo:
wordpress-proxywordpress-private-ip
- Firewall para exponer HTTP en las VMs de demo.
Uso rápido
- Inicializá:
terraform init
- Definí
terraform.tfvars:
project_id = "tu-project-id"
region = "us-central1"
zone = "us-central1-a"
network_name = "default"
sql_root_password = "cambiame-por-una-password-segura"
- Plan y apply:
terraform plan
terraform apply
Comandos útiles post-deploy
Con la salida sql_instance_connection_name, en wordpress-proxy podés correr:
wget https://dl.google.com/cloudsql/cloud_sql_proxy.linux.amd64 -O cloud_sql_proxy && chmod +x cloud_sql_proxy
export SQL_CONNECTION=<connection_name>
./cloud_sql_proxy -instances=$SQL_CONNECTION=tcp:3306 &
Notas
- Este ejemplo crea infraestructura base y conectividad; la instalación guiada de WordPress (UI) se hace manual como en el lab.
- El password root se maneja por variable sensible; no lo hardcodees en código versionado.