Información de la materia
Docentes:
- Mariano Benitez
- Rodolfo Sumoza
- Tomás Najún
- Rodrigo Pazos
- David Túa
Hay parte práctica y parte teórica. La idea es llevar la práctica al día (?).
¿De qué vamos a hablar?
Programas interconectados en la red
Para qué se comunican? Es necesario?
- Por disponibilidad
- Por escalabilidad
- Si un programa se vuelve muy pesado y consume muchos recursos, va a ser necesario volverlo distribuido.
- Por ubicación geográfica
¿Para qué armar una red?
Si es más fácil hacer todo en la misma compu, ¿para qué me voy a gastar en hacer una red?
Esencialmente, por 2 motivos:
-
Por diseño/definición es distribuido
- Red de bancos
- Sensores / elementos de IoT
- Aplicaciones móviles Básicamente, cuando el problema es inherentemente distribuido, no hay chance de juntarlo. Este motivo se llamará "Descentralizado", el cual es necesario.
-
Porque no alcanza una sola computadora
- No me alcanza la memoria, CPU, etc.
- No se puede apagar nunca
- Tiene que ser muy rápido Básicamente, cuando tengo requerimientos que me obligan a usar más de una computadora. A esto le vamos a decir "Distribuido", el cual es un motivo suficiente.
¡Los sistemas distribuidos son complejos!
Cuando hay más cosas que se pueden romper, se agrega muchísima complejidad. Uno tiene que estar preparado para que las cosas se rompan.
Justamente, en un sistema distribuido es mucho más complejo porque tiene muchos componentes.
Te pueden pasar mil cosas
- Se rompe la computadora
- No se sabe con quién se tiene que comunicar
- No se ponen de acuerdo
- Se corta la comunicación
- Se pierden los bits
- Pueden venir intrusos
- Atacantes, por ejemplo
- Obvio, hay bugs en el código Entre otras cosas...
Si no se controlan estas cosas: ¿La gente podría confiar en el sistema? Si no se confía en el sistema, no sirve para nada.
El principal desafío de los sistemas distribuidos es hacerlos confiables.
Cómo sabemos todo esto?
- Del libro de Tanenbaum.
- Es un bodrio de leer, en la materia se tratan de bajar las ideas principales del mismo.
¿Qué pasa en un sistema distribuido?
- Hay procesos.
- Que se comunican.
- Que se coordinan entre sí.
- Que necesitan encontrarse.
- Que comparten información.
- Que se prenden, apagan y rompen.
- Que se defienden ante amenazas.
Enfoque de la materia
La realidad:
- Son una banda de temas y muy complejos y amplios
- Se puede ir en mucho detalle en cada punto (profundidad)
- Los problemas y las soluciones cambian todo el tiempo
- Pero las bases siguen siendo las mismas
- Se usa en el trabajo de todo ingeniero de software
Entonces como ingenieros, ¿qué es lo importante?
- Tener un conocimiento de las bases que forman un sistema distribuido
- Analizar un sistema y reconocer sus capacidades y limitaciones
- Proponer soluciones en forma objetiva y clara
Un buen diseño de un sistema distribuido (qué pasa cuando se rompe, cómo encaro temas de escalabilidad, etc.) logra que no tengas que hacer cambios de arquitectura grandes en caso de la necesidad de un cambio.
¿Qué se llevan al final de la materia?
- Conocimientos de los aspectos de los sistemas distribuidos
- Entendimiento de las características y el impacto de cada aspecto
- Habilidades básicas para analizar y evaluar problemas y soluciones
¿Qué no se llevan?
- Conocimiento profundo de alguna solución (ej: Kubernetes)
¿Qué capacidades necesitan traer?
- Analizar información y situaciones complejas
- Presentar alternativas de forma objetiva
- Tener pensamiento crítico, en resumen.
Teoría (70% de la cursada)
- Foco en los conceptos
- Problemas y características
- Bajada a tierra del libro
Práctica (30% de la cursada)
- Foco en las habilidades
- Analizar situaciones
- Presentación de propuestas
De parte de que aprenden
- Lean los capítulos después de la clase
- Consultas en la siguiente
Evaluaciones
2 parciales, 11 de septiembre y 30 de octubre Recus: 6 y 11 de noviembre
2 TPs
- Entrega TP1: 18 de septiembre
- Entrega TP2: 6 de noviembre
Introducción
Objetivos funcionales
¿Vale la pena construir un sistema distribuido? ¿Para qué hago un sistema distribuido? Porque tengo que compartir información
Objetivos que merecen crear un sistema distribuido
-
Los principales:
- Ofrecer recursos/procesos a otros
- Transparencia en la distribución de procesos y recursos
- Interoperabilidad
- Confiabilidad
-
Otros aspectos influyentes
- Seguridad
- Escalabilidad
Por compartir recursos
Brindar acceso a recursos para que esté disponible para muchos usuarios.
En este contexto, casi que cualquier cosa que quiera compartir es un recurso:
- Archivos
- mensajes
- Impresoras
- Servicios
- etc.
Cuando necesito compartir recursos, se merece un sistema distribuido. Recurso es un concepto amplio que puede ser cosas o procesos de negocio.
Transparencia en el acceso
Necesitamos esconder la ubicación de los recursos de la gente que accede Pero hay varios aspectos para "esconder" o hacer transparente:
- El acceso (representaciones de datos, sistemas operativos)
- La ubicación (donde está ubicado: data center, uno o varios)
- Reubicación (si muevo el recurso mientras lo estoy accediendo)
- Si yo me muevo mientras que quiero acceder un recurso, debería de poder accederlo.
- Migración (si el recurso se mueve)
- Si el recurso se mueve y yo no.
- Replicación (si hay una o varias copias del mismo recurso)
- Concurrencia (si hay muchos usuarios accediendo al mismo recurso)
- Fallas (el recurso puede fallar y recuperarse sin afectar el uso)
Con esconder, nos referimos a que deberíamos de poder acceder al recurso a pesar de cualquiera de estas condiciones previamente mencionadas.
Content Encoding: cuando se le pide un HTML muy pesado a un server en el browser, no se manda en Plain Text, sino que se zippea (comprime) y se manda.
Apertura e interoperabilidad
Un sistema abierto es cuando los componentes pueden ser usados por otros sistemas, y/o cuando el sistema tiene componentes originados por otro lado.
Normalmente nos referimos a:
- Sistemas que adhieren a reglas (protocolos) estándar.
La idea es que "todos nos apeguemos al mismo contrato", y que hagas fácil para el resto poder interactuar con dicho sistema.
Confiabilidad
La confiabilidad de un sistema distribuido más compleja que uno centralizado:
¡Hay muchas más partes que pueden fallar!
Encima hay varios aspectos dentro de la confiabilidad:
- Disponibilidad
- Cuánto tiempo digo que voy a estar disponible
- Fiabilidad (reliability)
- Qué porcentaje del tiempo que digo que voy a estar disponible realmente estoy disponible
- Seguridad ante fallas (safety)
- Qué tan resiliente es el sistema, qué tanto soporta las fallas
- Mantenibilidad
Seguridad
Queremos proteger el sistema de usos indebidos (en un concepto amplio)
Los conceptos comunes de seguridad:
- Identificación (quién sos)
- Autenticación (sos quien decís ser)
- Autorización (hacés sólo lo que tenés permitido hacer)
Otros aspectos relacionados:
- Privacidad de la comunicación (que no escuchen nuestras conversaciones)

- Intercepción de la comunicación (que no se hagan pasar por otro)
Escalabilidad
Hay varias dimensiones relacionadas con la escalabilidad:
- En tamaño (cuántos usuarios o recursos acceden al sistema)
- Aumenta mucho el tráfico
- Puedo tener una Raspberry Pi con 124.000.000 intentos de conexión. No va a andar bien ni en pedo, tampoco escala.
- En geografía (si se accede al sistema desde distintas ubicaciones físicas)
- En administración (se puede administrar, aunque crezca)
Estrategias de escalamiento
- Mejorar la latencia: hacer eficiente la comunicación
- Es el tiempo "muerto" donde no se está procesando nada.
- Si bajo la latencia, puedo dedicarle más tiempo al procesamiento, justamente. Puedo acelerar la comunicación.
- Particionar y distribuir: llegar más rápido al dato.
- Tengo un F.S en la facultad. Si está en un sólo servidor, se van a encolar todas las requests que se hagan al server.
- Si particiono los F.S por apellido, puedo acceder más rápido a la información. Puedo paralelizar esos accesos.
- Replicar: Orphan black y sus derivadas
- Es tener copias idénticas del recurso. Puedo darle una copia a los de un lado, otra a los de otro, así no acaparo el ancho de banda principal.
- Es una copia fiel, a diferencia del cache, más "pull".
- Caching: casi un clon, pero de una forma más específica
- Tengo una sola fuente de información, pero tengo almacenamientos intermedios que le hacen de copia a los que me preguntan.
- El cache es una copia "volátil", más "push".
- Usar esto o una réplica cambia muchas cosas dentro de la arquitectura.
El arte de hacer un sistema distribuido es hacer un trade-off entre escalabilidad, costos y capacidades.
YAC de sistemas distribuidos
YAC = yet another classification
YAML = yet another markup language
- Computación de alta performance
- Cluster computing (están todos juntos)
- Grid computing (sistema descentralizado cooperando)
- Masivo, muchas computadoras.
- Sistemas de información distribuidos
- Este es el mundo empresarial de esos días
- Enterprise application integration
- Sistemas ubicuos (pervasive)
- IoT
- Sistemas para dispositivos móviles
Derribando mitos
Verdadero o falso:
- La red es confiable
- La red es segura
- La red es homogénea
- La topología de la red no cambia
- La latencia es cero
- El ancho de banda es infinito
- El costo de comunicación es cero
- Hay una sola administración
Spoiler: son todas falsas.
Arquitectura de software
La idea principal es conocer los patrones de arquitectura que podemos usar para conectar sus partes. Tenemos que preguntarnos cosas como:
- ¿Qué distribución funcional y técnica de componentes usamos?
- ¿Cómo conectamos las piezas de software?
La elección de la arquitectura define las características del sistema:
- Capacidades, restricciones y desempeño
- Estilo arquitectónico
Estilos arquitectónicos
Hay básicamente 3 estilos:
- Por capas
- Orientada a servicios
- Pub/Sub
Por capas
Siempre van de arriba para abajo. Ejemplo: Stack de comunicación TCP, la arquitectura que siguen todos los proyectos de Spring.
Aplicaciones por capas. Modelo de 3 capas (aplicación, procesos y datos).
Orientada a servicios
Separo componentes funcionales en vez de por nivel de abstracción.
Criterios/formas para distribuir:
- Objetos
- Componentes
- Recursos (REST)
Es necesario saber los contratos de los componentes disponibles para usar, para saber qué me ofrece. No tiene mucha ciencia:
- Tengo un servicio que me devuelve la ubicación geográfica de una IP
- Tengo otro que, luego de autenticarme, me devuelve mi saldo de Mercado Pago
- ... Compongo estos servicios para desarrollar mis funcionalidades.
Distinción importante entre arquitecturas:
- ¿Necesito algún "ware" en el "middle"?
- Se comunican las partes directamente sin intermediarios
Middleware sirve para enviar mensajes entre orígenes y destinatarios. Es un cacho de software que se para en el medio y hace de mediador entre cliente y servidor, por ejemplo. Es una pieza de software más para administrar.
| Acoplado temporalmente | Desacoplado temporalmente | |
|---|---|---|
| Acoplado x referencia | Comunicación directa online. • Llamada REST | Mailbox: • Te dejo el mensaje |
| Desacoplado x referencia | Eventos • Notificar algo y los que están escuchando hacen | Espacio compartido de datos • Digo algo y los que quieren lo toman y accionan |
Pub/Sub
Tenés un montón de soluciones: Apache Kafka, Redis, RabbitMQ, etc.
Es un diseño desacoplado. Requiere una pieza de software adicional como intermediario.
No requiere que productores y consumidores estén disponibles al mismo tiempo. La asincronía requiere cierta relajación de los requerimientos de performance.
La diferencia principal entre eventos y espacio compartido es la persistencia del mensaje.
Middleware
Mediar entre componentes vía interfaces. Modelos:
- Wrappers
- Interceptor
La diferencia radica en lo siguiente:
- El wrapper es una implementación distinta que encapsula una implementación ya existente, pero le agrego comportamiento.
- Ej: File System. Tengo que leer un archivo puntual. No sé si estoy leyendo un disco físico o uno en la nube. Con la implementación que ya tenía sólo podía leer discos físicos, pero con el Wrapper que implementaron en la última versión puedo leer discos en OneDrive (?).
- El interceptor se pone más abajo, casi a nivel de protocolo, y en lugar de hacer la llamada directa lo manda por detrás a otro servicio. Ataja la llamada en el medio y la reenvía.
- Ej: File System. No sé qué disco estoy leyendo para acceder a un archivo en particular porque me lo resuelve el Interceptor que opera en el medio.
Otra vuelta de la arquitectura por capas
Cliente - Servidor: el clásico / casi una reliquia. Multi capas - algo más común, siempre separamos un poco más.
Ejemplos
- NFS
- Network File System
- WWW (World-Wide-Web)
- Abajo de todo está TCP/IP.
Criterios de distribución
Distribución vertical y horizontal.
Vertical: tengo varios nodos que hacen lo mismo Horizontal: tengo un nodo que cumple distintas funciones
Cuando están desacoplados, ¿cómo encuentro al destinatario?
¿Qué función cumplen los nodos? ¿Son todos iguales?
Distribución estructurada vs. peer to peer.
Conclusiones
Hay un montón de opciones para distribuir los componentes. La forma determina problemas y soluciones. Elegir una forma adecuada para los requerimientos es fundamental.
Arquitectura del sistema = distribución física de procesos y conexiones
La de sistema es la más técnica. Arquitectura de software = estructura funcional y patrones de uso
Procesos
Procesos e hilos
Tanto procesos como threads son formas de ejecutar en paralelo distintas funciones del sistema (Obvio...¿no?)
Los thread nos permiten separar las operaciones lentas (como el I/O) para no entorpecer el funcionamiento general del sistema.
Es una decisión de arquitectura interna del programa como usar los threads para mejorar el rendimiento general.
Muchas veces confiamos en la plataforma para que nos resuelva el manejo de threads pero a veces es importante ajustarlo a nuestras necesidades.
Virtualización
La clásica (toda la compu)
Contenedores
- Un poco más liviano
- Docker, Kubernetes
Clientes en entornos virtuales
- La clásica terminal
- X Windows
- Escritorios remotos
La virtualización tiene, en cierto punto, un beneficio sobre la fiabilidad en runtime (?).
Clientes
El que representa a los usuarios.
Representan la interfaz de los clientes contra los servicios:
- Escritorios remotos
- Protocolos de acceso a servicios (NFS)
- Web Browser
- Progressive Web Apps
Servidores
El que atiende a todos los clientes. En la mayoría de los casos hay un patrón común:
- Reciben conexiones en puertos de red.
- Procesan pedidos y devuelven una respuesta.
Los threads que se ejecutan en un server describe la arquitectura de software como procesan los pedidos
Hay servers que mantienen estado de sus clientes:
- Stateful vs. Stateless
- Back For Front (BFF).
- Están tuneados para lo que necesitan para las aplicaciones móviles.
- Si los servicios de backend de abajo cambian, sólo cambia el Back For Front y no la implementación directa de la aplicación móvil.
Definir que vas a usar un BFF es una decisión de arquitectura de software.
Cómo se implementa el escalamiento del server HTTP o TCP:
- Balanceador de carga.
- Es un intermediario que tiene que existir casi siempre en este tipo de sistemas.
- Es un pasamano que intercepta el mensaje, se fija quién está disponible y se lo manda.
- Si se quiere hacer escalamiento, es necesario un balanceador de carga.
- Existen versiones físicas y de software.
Migración de código
Dentro de la virtualización.
¿Qué hay que tener en cuenta para permitir una migración?
- Soporte de la infraestructura
- Características de soporte (reinicios, notificaciones)
Escalado horizontal o vertical Ejemplos:
- VmWare
- Migra una máquina de un equipo al otro y vos no te enteraste.
- Kubernetes
- Si vos querés escalarlo, te baja el POD y te lo levanta en otro lado. Te hace un reinicio para este "autoescalado".
- Azure
- AWS
La virtualización y el escalamiento tienen sus chiches para cuando se quiera migrar la infraestructura.
Conclusiones
Los procesos son la base de cualquier infraestructura de software, aunque sean centralizados o distribuidos.
La arquitectura interna de los procesos con threads es fundamental para la arquitectura del sistema.
La mayoría de las veces, nuestros procesos corren en ambientes virtualizados, y la migración de código se hace de forma transparente.
Sin embargo, es importante entender cómo los cambios de base afectan los procesos en ejecución.
TP1
Están pensando en hacer un servicio que dada una IP te devuelva una ubicación, y otro servicio que dada una coordenada te devuelva un clima.
Escalándolo...
- Cientos de miles de personas tratando de usarlo.
Clase 2
Un sistema distribuido es uno que involucra varios dispositivos que se comunican a través de la red, y trabajan en conjunto con tal de lograr un objetivo en común.
¿Qué diferencia tiene respecto a un sistema paralelo/concurrente?
- Los distribuidos involucran diferentes dispositivos, mientras que los concurrentes son parte del mismo dispositivo.
- Los distribuidos están "un nivel por encima".
- Un sistema distribuido (SD), al contrario de un sistema paralelo (memoria compartida + clock único), tiene distintos clocks (ergo noción del tiempo). Más específicamente, cada nodo tiene su propio clock.
¿Qué problemas podemos llegar a tener?
- Saber quién llegó primero a realizar una solicitud.
- Un nodo puede tener un registro de un mensaje en tal hora, y que otro tenga el mismo, pero sin considerar la latencia que hay entre nodos por su distancia.
En SDs, siempre terminamos haciendo estimaciones en cuanto al tiempo, como en Análisis Numérico.
Un sistema distribuido puede ser...
- Centralizado: el control lo tiene un ente central.
- Depende organizativamente de una cierta toma de decisiones.
- Depende de quién toma la decisión, no cómo se toma a nivel de hardware.
- A pesar de haber varias instancias o un cluster de nodos, se puede dar el caso en el que tomen la decisión de manera autónoma, sin pedirle permiso a otros.
- Descentralizado: el control se distribuye entre varios nodos.
- Las decisiones las toman varios nodos.
- Surgen nuevos problemas, como qué esquema de votación se implementa.
Esta clasificación depende de:
- Donde guardo los datos
- Cómo se distribuye el control y gestión de los datos
- Ubicación de los nodos
La distribución del sistema siempre debe ser transparente. La forma de actuar con el sistema debe ser la misma, independientemente de dónde me encuentre.
Aclaraciones respecto de la clase pasada
Un servidor en Brasil suele ser más caro que en EE.UU, puesto que en USA abundan mucho más los servidores, además de que la energía es potencialmente más barata.
Es muy raro que existan servidores en América del Sur.
Si montamos un servicio en servers de Amazon en USA, va a andar bien a pesar de la lejanía. ¿Por qué? Hay cables directos que conectan Argentina con USA-East.
CAP
- Consistencia: si yo escribo A en un lugar, y lo leo desde otro lado, tengo que leer A, sin modificaciones.
- Disponibilidad: está estrictamente relacionada con la consistencia, puesto que quiero respuestas rápidas.
- En el caso de las bases no relacionales, empieza a haber un trade-off entre la C y la D. A veces puedo llegar a querer responder rápido en lugar de responder con lo último.
- Volviendo al caso de la clase pasada (caso símil Netflix), con las recomendaciones voy a tener un problema (hasta cierto punto), puesto que no siempre quiero lo último.
- En cambio, para casos como los pagos, voy a necesitar darle prioridad a la consistencia. No puedo darle un servicio al usuario hasta que sepa que pagó.
- Particionamiento: con algún criterio, elijo cómo distribuyo los valores que persisto en mis distintas instancias.
- Problema: se cae una instancia, pierdo disponibilidad
- Solución: replicar las instancias con un cierto criterio.
- Ej: tener 2 réplicas para cada instancia.
Comunicación
Para comunicar 2 procesos, es necesaria alguna interfaz que medie entre estos. Por lo general, usamos algún protocolo de comunicación (ej: HTTP).
¿Para qué lo estudiamos?
- Porque es el método por el que los procesos distribuidos comparten información, lo que lo vuelve una pieza indispensable para hacerlos funcionar, y de forma eficiente.
- Porque el tipo de comunicación está fuertemente relacionado a requerimientos funcionales y no funcionales. Son decisiones de arquitectura
Modelo OSI
- El modelo OSI es un marco conceptual que divide la comunicación de redes en 7 capas organizadas de forma jerárquica.
- Sirve para estandarizar cómo los sistemas se comunican entre sí a través del uso de protocolos
- Cada capa se encarga de proveer servicios específicos a la capa superior.
- Del lado del emisor cada capa suma su header con su metadata al mensaje original. La versión final es enviada a través de la capa física
- Del lado del receptor cada capa procesa la parte del header correspondiente, la quita del mensaje y envía el resto a la parte superior
- Es importante notar que el modelo OSI es un modelo de referencia y no un conjunto de protocolos concretos Decimos que es un modelo porque es una representación de cómo funciona y cómo se envía la información a través de los distintos protocolos de comunicación.
Problema del Modelo OSI
TCP/IP le rompió el orto, para simplificar, porque era mucho más simple de implementar y modelar que OSI.
OSI, por su parte, yacía con el problema de que, para cada capa, había que implementar un protocolo puntual, lo cual le agregaba complejidad, ya que debía "funcionar" con el resto de protocolos (el de la capa de arriba, el de la de abajo, y consigo mismo).
TCP/IP ganó la guerra
Para que sean prácticos (tanto OSI como TCP/IP), hay que prestar mucha atención a cada capa.
No solemos interactuar mucho con las capas debajo de la de aplicación.
Capa de Middleware
Tanenbaum y otros autores terminan diferenciando la capa de middleware: procesos que corresponden a la capa de aplicación pero proveen servicios generales a otros procesos
- DNS le permite a las aplicaciones encontrar direcciones de red asociados a nombres (domains)
- Autenticación y autorización, que permiten identificar y permitir o denegar acceso
- Mismo lo hacemos a nivel capa de aplicación casi siempre, cuando implementamos o usamos (ej: Auth0) Authentication Middlewares, que validan si un usuario está autenticado y/o autorizado para realizar cierta acción.
Todo lo que hace el middleware es proveer capas de abstracción.
Tipos de comunicación
- Sincrónica: envío un mensaje y espero la respuesta, quedándome bloqueado hasta que llegue.
- Ej: una conversación cara a cara, una llamada.
- Asincrónica: emito el mensaje y trabajo con otra cosa; la respuesta me va a llegar cuando me tenga que llegar.
- Ej: una conversación por WhatsApp.
- Transitoria: si el receptor o alguna parte del sistema de transmisión falla, el mensaje se pierde
- Persistente: el middleware va a garantizar que el mensaje llegue al receptor, aunque no esté activo en ese momento.
Vamos a empezar a usar combinaciones de estos tipos de comunicación
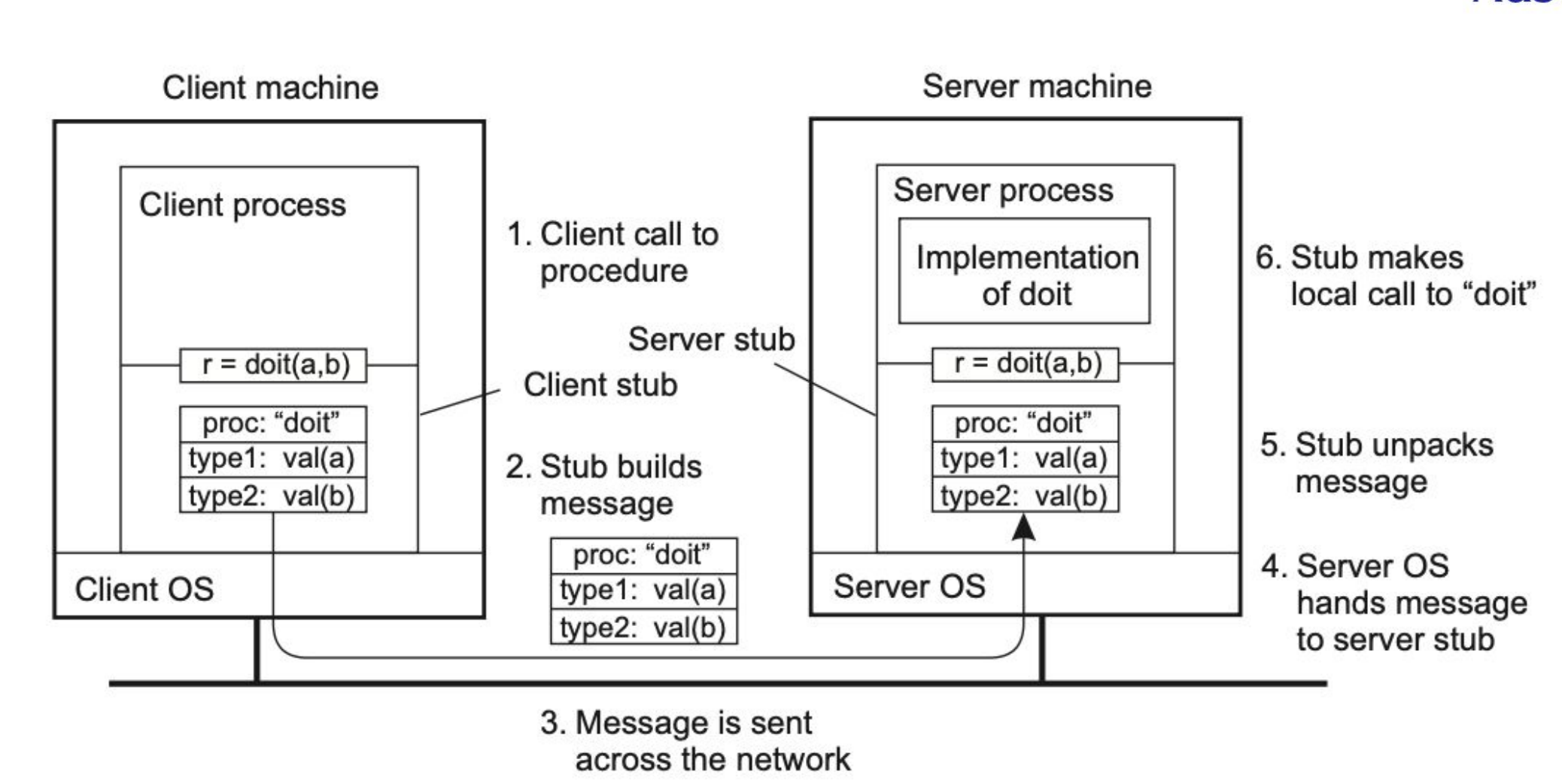
RPC
Refiere a Remote Procedure Call.
Anteriormente, las aplicaciones se programaban al punto de codear manualmente la forma de mandar mensajes. Es decir, leyendo el código, sabía perfectamente en qué momento se manda el mensaje, lo cual no era transparente.
Al presentar RPC, se planteó que la comunicación tiene que ser tan simple como llamar a un procedimiento de forma local, más allá de que se está ejecutando en otra máquina. La comunicación es totalmente transparente para el programador.
RPC es un modelo de comunicación que permite a un programa ejecutar procedimientos en otra máquina como si fuesen locales, cuya idea es esconder la complejidad de la red: yo llamo a la función sumar(2,3) desde mi notebook, y en lugar de correrlo localmente lo estoy corriendo en una Raspberry PI que tengo a 40 metros.
Procedimiento Función. Un procedimiento no devuelve un valor, es similar a una void function. Por eso RPC usa procedimientos.
Stub: código que, en principio, no cumple el problema que estamos resolviendo, pero tiene herramientas que te brindan formas de hacerlo. Se encarga de transformar parámetros pasados entre el cliente y el servidor durante un RPC.
El cliente y el servidor conocen un stub en particular, que sirven como una interfaz que los abstraen de la forma de comunicación.
En resumidas cuentas, es un "middleware" que funciona como capa de abstracción entre cliente y servidor para que el cliente pueda ejecutar un RPC sobre el servidor.
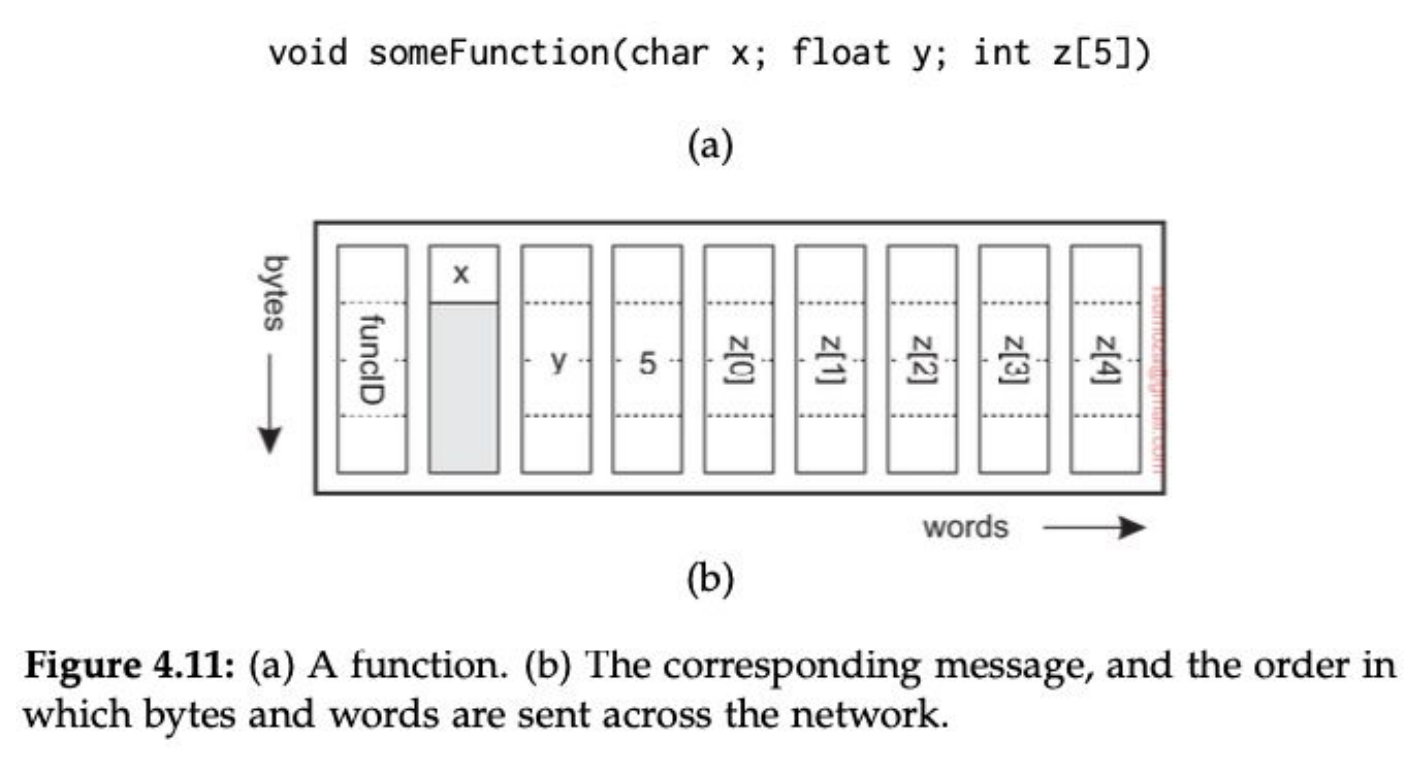
Parámetros
- Manejar parámetros en RPC no es trivial: codificar y decodificar los parámetros se llama marshalling (GO MENTIONED 🗣️🗣️) y unmarshalling.
- La idea es poder transformar información a formatos neutrales (bytes) que tanto el cliente como el server pueden interpretar de manera automática.
- Los problemas surgen cuando tratamos con punteros o colecciones: deberíamos enviar toda la colección o el objeto al que hace referencia el puntero al servidor. No es imposible pero tenemos que tener en cuenta que es costoso.
- Cuando tratamos con objetos muy complejos o colecciones anidadas el marshalling automático podría no estar disponible. Sería preferible manejarlo de manera manual.
- Estos problemas se alivian usando referencias globales.
¿Por qué no usamos JSON para sincronizar 2 stubs en RPC? Porque es súper ineficiente, si mando el JSON lo mando entero, no se comprime. Si bien existe RPC para JSON, es una cagada.
Referencias globales
Es una referencia que todos los miembros del sistema/programa conocen. En un sistema distribuido, que todos los servicios conozcan una referencia particular, se logra teniendo servicios/máquinas que estén dedicadas al pasaje de esa información o de esas referencias. Claramente, esto se hace cuando tenemos objetos relativamente pesados, si paso un int o un boolean por referencias globales usando RPC, soy un forro.
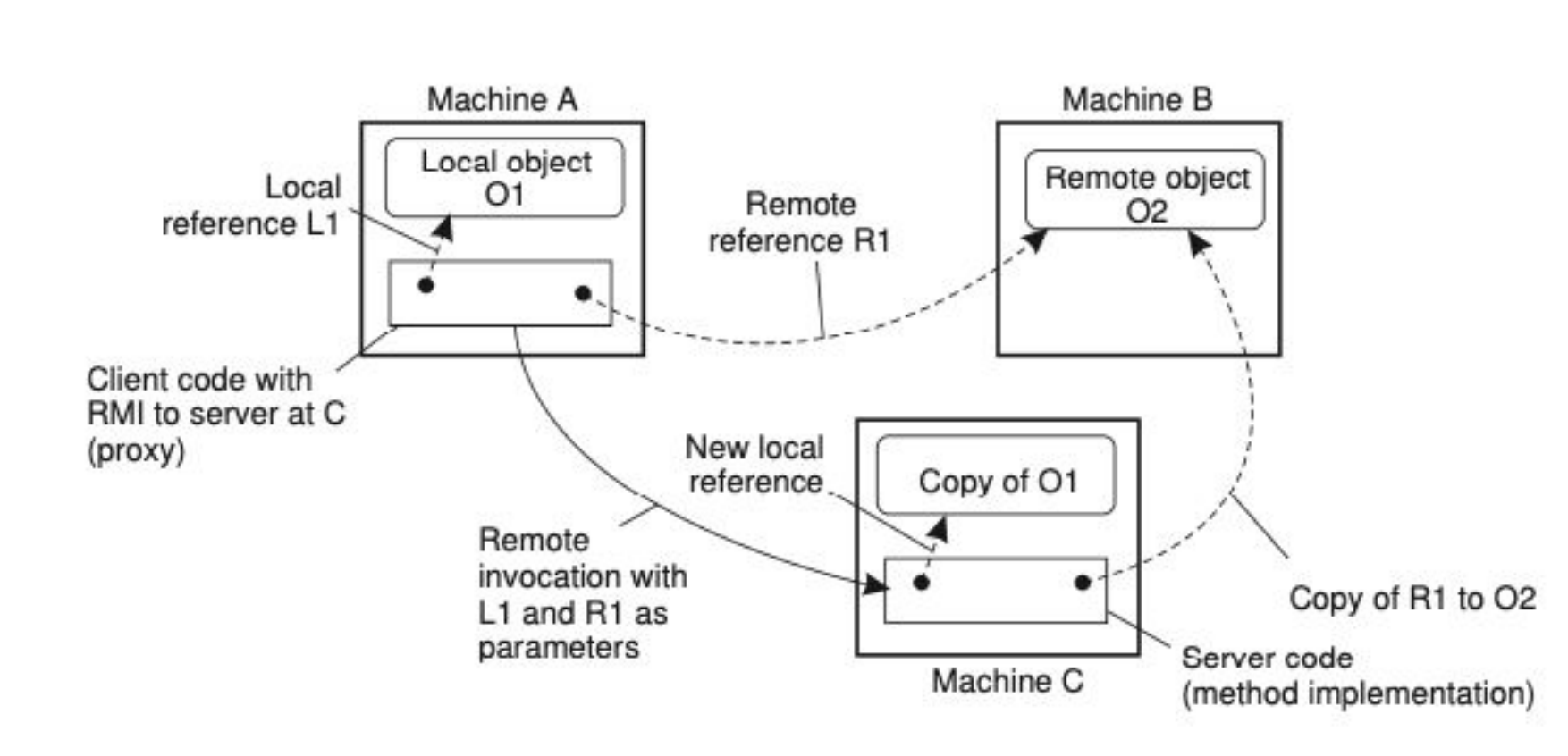
- Lo que se ve en la foto es lo siguiente:
- Machine
A– Objeto localO1- En la máquina
Aexiste un objeto localO1. - El cliente en
Atiene una referencia local (L1) para acceder a él directamente.
- En la máquina
- Machine
B– Objeto remotoO2- En la máquina
Bexiste un objeto remotoO2. - Machine
Atiene una referencia remota (R1) para invocar métodos sobreO2. - Esa referencia
R1es en realidad un proxy/stub que traduce las invocaciones locales en llamadas remotas aB.
- En la máquina
- Machine
C– Ejecución de un método remoto- El cliente en
Ainvoca un método remoto en MachineC, pasando como parámetros tantoL1(referencia a O1) comoR1(referencia aO2). - Machine
Crecibe esas referencias, y aquí ocurre lo importante:- Para
L1: en vez de pasar el objeto completo, se crea una copia deO1en MachineCcon una nueva referencia local. - Para
R1: en MachineCse crea una copia de la referencia remota aO2, de manera que desdeCse puede seguir invocando métodos sobre el objeto enB.
- Para
- El cliente en
- Machine
- En un sistema basado en objetos usar referencias es ideal
- Esto deja de ser eficiente cuando los objetos a los que hacemos referencia son pequeños (
ints,booleans)
Soporte
Si usamos RPC, el cliente y el servidor tienen que estar de acuerdo en el protocolo (formato de mensajes + procedimiento para manejar estructuras complejas). Para lograr eso, se puede especificar la interfaz y generar automáticamente los stubs. Otra alternativa es hacerlo parte del lenguaje.
Las diferentes herramientas de RPC lo hacen de manera automática.
¿Cómo armamos un sistema que use RPC?
Tenemos escenarios donde RPC es parte del lenguaje, lo cual sirve cuando los servicios están hechos con el mismo lenguaje. Un ejemplo en Java es RMI.
RPC es parte de la guía, lo vamos a tener que ver por nuestra cuenta.
Gran parte de los conocimientos los vamos a incorporar mejor de manera práctica.
Comunicación basada en mensajes
Los mensajes son finitos, en algún momento terminan, tienen un sentido (por esto un TcpStream de Rust no es un mensaje como tal, sino una cadena infinita de mensajes). En general tienen una interfaz que conocemos.
Los mensajes empiezan a ser relevantes en comunicación asíncrona, donde empiezan a surgir ciertas preguntas:
- ¿Qué pasa cuando el receptor no está activo en el momento en el que se genera la request?
- ¿Qué pasa cuando no queremos o necesitamos que la comunicación sea sincrónica?
- Excepto por algunas variaciones poco comunes, RPC no soporta estos casos. Y por eso necesitamos usar mensajes.
Necesitamos atajar estos problemas donde la comunicación falla, donde no sólo importa la transparencia de alto nivel.
Si la llamada falla en un HTTP Request, tengo que poder hacer un re-try.
Sockets
- Es posible armar una comunicación basada en mensajes usando los servicios que ofrece la capa de transporte. Es decir, fuera del middleware
- Son operaciones muy estandarizadas en diferentes interfaces, como los sockets que formaron parte de Berkeley Unix (BSD) y eventualmente fueron adoptados por POSIX
- Los sockets son abstracciones sobre el puerto que se usa para la comunicación
Tienen distintas operaciones:
Bind: asocia el socket a un puerto y host específicos.Listen: pone el socket en modo escucha para aceptar conexiones entrantes.Accept: acepta una conexión entrante y crea un nuevo socket para la comunicación.Connect: conecta el socket a un host y puerto remotos.Send: envía datos a través del socket.Recv: recibe datos del socket.Close: cierra el socket.
La implementación en Python tiene la particularidad de que escuchan de a N bytes. En el caso del ejemplo del slide, escucha de a 1024 bytes (1 kB). Va partiendo lo que va escuchando de a 1 kB, justamente.
Problemas de esta implementación:
- Tanto client como server se tienen que poner de acuerdo en muchas cosas:
- Host
- Port
- Protocolo de comunicación
- Tamaño del mensaje En resumen, no es nada transparente.
Soluciones a problemas de los sockets
ZeroMQ
- La implementación que vemos en clase es muy simple, y si queremos tener funcionalidades extras las tenemos que desarrollar nosotros, pero a modo explicativo ta güeno.
- Mejora las capacidades de los sistemas de comunicación basados en mensajes
- Simplifica y hace transparente los aspectos más concretos de las conexiones y nos permite tener un soporte para conexiones Many-to-One o One-to-Many
- Es asincrónico, pero basado en conexiones: esto implica que si el receptor no está activo para recibir los mensajes tiene que tener alguna forma de encolar los mensajes y enviarlos cuando pueda
- Ofrece tipos de socket que facilitan la programación de la comunicación. Estos tipos funcionan de a pares: REQ/REP, PUB/SUB, PUSH/PULL
Si tengo 2 procesos (P1, P2), y P1 le quiere mandar un mensaje a P2 pero P2 no está "despierto", P1 encola el mensaje (lo mantiene en memoria?) para mandarlo luego.
Si P2 quiere escuchar a P1 pero P1 muere, el mensaje que P1 le había mandado se pierde para siempre. De esta manera, a pesar de tener asincronismo, no tenemos consistencia.
ZeroMQ sigue teniendo el problema de tener que especificar dónde se quiere conectar, pero ta má güeno respecto a los sockets comunes.
- Socket default (TCP/IP)
from socket import *
class Server:
def run(self):
s = socket(AF_INET, SOCK_STREAM)
s.bind((HOST, PORT))
s.listen(1)
(conn, addr) = s.accept() # returns new socket and addr. client
while True: # forever
data = conn.recv(1024) # receive data from client
if not data: break # stop if client stopped
conn.send(data + b"*") # return sent data plus an "*"
conn.close() # close the connection
class Client:
def run(self):
s = socket(AF_INET, SOCK_STREAM)
s.connect((HOST, PORT)) # connect to server (block until accepted)
s.send(b"Hello, world") # send same data
data = s.recv(1024) # receive the response
print(data) # print what you received
s.send(b"") # tell the server to close
s.close() # close the connection
- Socket Req/Rep de ZeroMQ
import zmq
def server():
context = zmq.Context()
socket = context.socket(zmq.REP) # create reply socket
socket.bind("tcp://*:12345") # bind socket to address
while True:
message = socket.recv() # wait for incoming message
if not "STOP" in str(message): # if not to stop...
reply = str(message.decode()) + '*' # append "*" to message
socket.send(reply.encode()) # send it away (encoded)
else:
break # break out of loop and end
def client():
context = zmq.Context()
socket = context.socket(zmq.REQ) # create request socket
socket.connect("tcp://localhost:12345") # block until connected
socket.send(b"Hello world") # send message
message = socket.recv() # block until response
socket.send(b"STOP") # tell server to stop
print(message.decode()) # print result
- Socket Pub/Sub de ZeroMQ
import multiprocessing
import zmq, time
def server():
context = zmq.Context()
socket = context.socket(zmq.PUB) # create a publisher socket
socket.bind("tcp://*:12345") # bind socket to the address
while True:
time.sleep(5) # wait every 5 seconds
t = "TIME " + time.asctime()
socket.send(t.encode()) # publish the current time
def client():
context = zmq.Context()
socket = context.socket(zmq.SUB) # create a subscriber socket
socket.connect("tcp://localhost:12345") # connect to the server
socket.setsockopt(zmq.SUBSCRIBE, b"TIME") # subscribe to TIME messages
for i in range(5): # Five iterations
time_msg = socket.recv() # receive a message related to subscription
print(time_msg.decode()) # print the result
- Socket Push/Pull de ZeroMQ
def producer():
context = zmq.Context()
socket = context.socket(zmq.PUSH) # create a push socket
socket.bind("tcp://127.0.0.1:12345") # bind socket to address
while True:
workload = random.randint(1, 100) # compute workload
socket.send(pickle.dumps(workload)) # send workload to worker
time.sleep(workload / NWORKERS) # balance production by waiting
def worker(id):
context = zmq.Context()
socket = context.socket(zmq.PULL) # create a pull socket
socket.connect("tcp://localhost:12345") # connect to the producer
while True:
work = pickle.loads(socket.recv()) # receive work from a source
time.sleep(work) # pretend to work
REQ/REP es un modelo 1-1
El modelo PUSH/PULL lo que permite es distribuir los mensajes entre todos los "oyentes", y con que uno sólo lo escuche ta bien. ![]()
MPI
- Los sockets tienen 2 problemas: por un lado no hacen transparente la comunicación, sigue siendo necesario programar send y recv. Por otro, fueron diseñados para funcionar sobre TCP/IP, y no funcionaban sobre protocolos propietarios más eficientes y con soporte para funcionalidad más avanzada.
- Pero el hecho de que fueran propietarios traía un gran problema: los programas no eran portátiles. Solo funcionaban siempre y cuando el desarrollo fuese sobre la misma plataforma.
- En 1991 se empieza a desarrollar la Message Passing Interface, que ofrece operaciones estándar para el manejo de mensajes.
- Sin perder la eficiencia y escalabilidad que tenían los sistemas propietarios ofrece portabilidad y flexibilidad, soportando diferentes patrones de comunicación
Particularidades
- MPI está pensado para casos muy particulares
- Requiere que todos los procesos empiecen y terminen en simultáneo y todos sean creados bajo un mismo contexto que van a compartir para intercambiar mensajes. Es por esto que los detalles de comunicación son transparentes para el usuario.
- Funciona mejor en escenarios de baja latencia y amplio ancho de banda.
- Baja latencia en estos escenarios refiere a nanosegundos.
- Tiene optimizaciones para compartir mensajes por memoria, para ser más rápido que la interfaz TCP/IP incluso localmente. El entorno tiene que ser lo más homogéneo posible.
- No está adaptado para funcionar con tolerancia a fallos, si algo falla todo el sistema falla
[Ver ejemplo del repo de Rodri] Todos los procesos/nodos en MPI tienen un rango. Si el rango es 0, hablamos del nodo padre, que va a crear la data (generalmente).
MoM (Message Oriented Middleware)
Llegamos al tipo de middleware basado en mensajes más importante: los sistemas de encolado de mensajes que proveen mecanismos de comunicación persistente asíncrona La única garantía que nos dan estos sistemas es que el mensaje va a ser insertado en la queue de destino. Y nada más.
Para poder enviar un mensaje a una queue es necesario conocer la queue a la que me tengo que conectar.
Hay sistemas donde la queue la vamos a sacar y vamos a administrar la queue como un proceso aparte. El chiste es que los procesos se puedan morir y revivir sin perder consistencia.
- Si se muere el proceso de la queue en estos casos (pensando en queues que viven en memoria), se pierden los mensajes
- Puede darse el caso de la queue
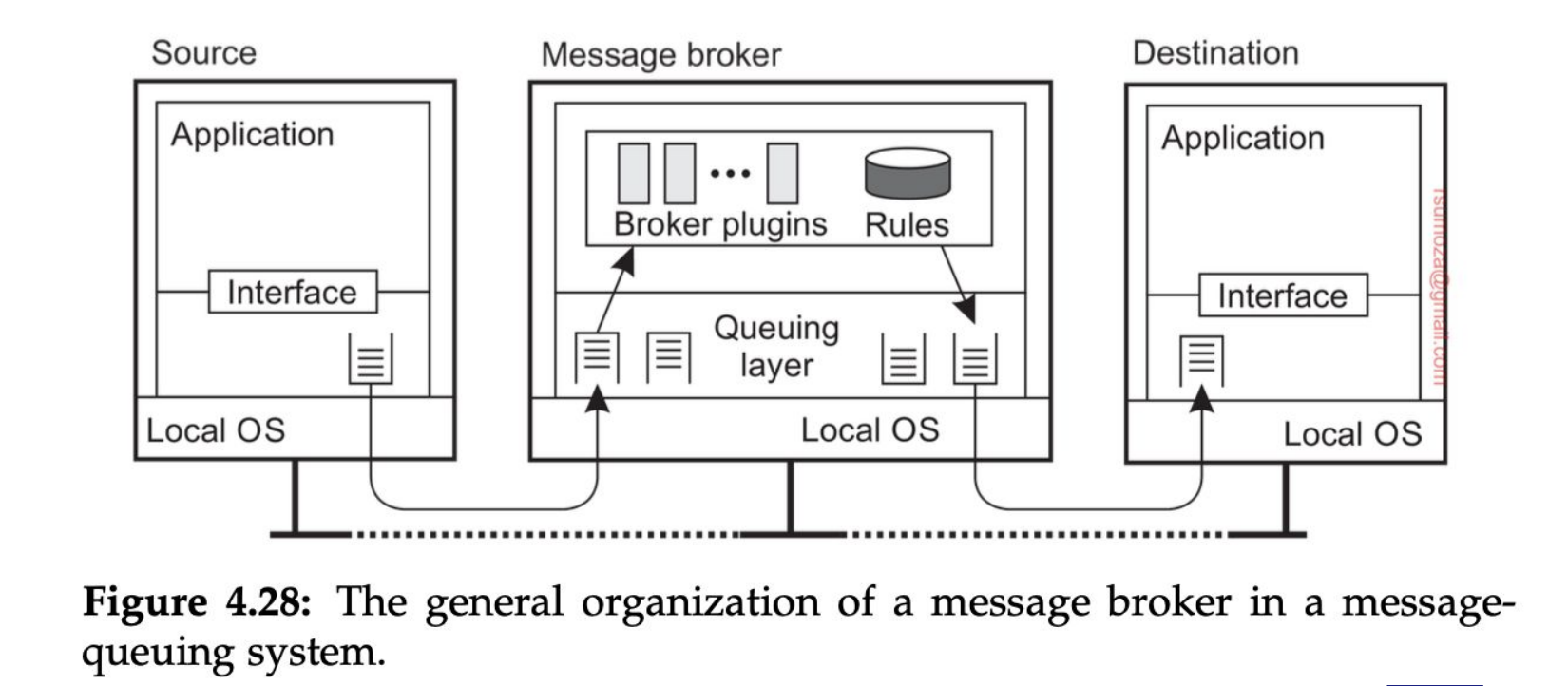
- Los brokers son, a grosso modo, intermediarios que operan entre los participantes de un proceso de comunicación, que "se fijan como hacer el pasamano de mensajes", hablando en criollo.
- Las distintas colas que maneja son por las diferentes prioridades que maneja el broker
- Está hecho para trabajar de manera modular, de modo que si un nuevo cliente quiere interactuar con algo desconocido para el broker, éste sólo debe "instalar el plugin" para manejar a este nuevo cliente
- Las reglas de negocio al cual pertenece el broker particular deben ser conocidas por este mismo, no debe ser agnóstico a estas.
Tiempo real: tiene que llegar en un orden correcto, pausado en el tiempo y en un momento específico en el tiempo. Es decir, debe respetar el orden y el tiempo que tardaría en la realidad, tiene que darse en los tiempos en los que yo espero percibir eso en la realidad.
Broadcasting
Consiste en mandarle un mensaje a todos los oyentes/disponibles.
Multicasting
Consiste en mandarle un mensaje a varios de los oyentes/disponibles, mas no necesariamente a todos.
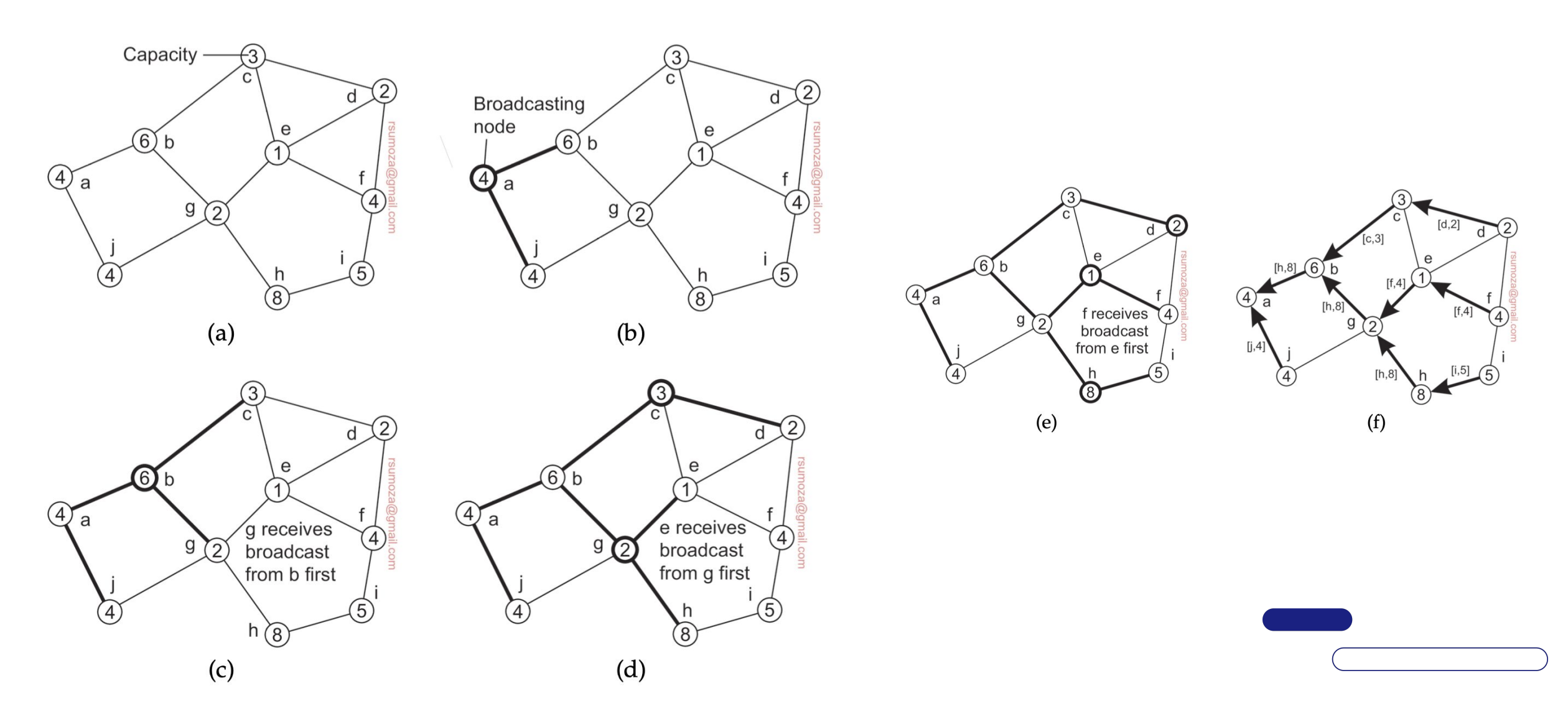
- La primera técnica que vamos a explorar es la de multicasting basado en árboles a nivel aplicación
- La distinción más relevante es que este árbol existe en la capa de aplicación y no la física. Es decir que tenemos una overlay network.
- ¿Cómo llegamos de A hasta C?
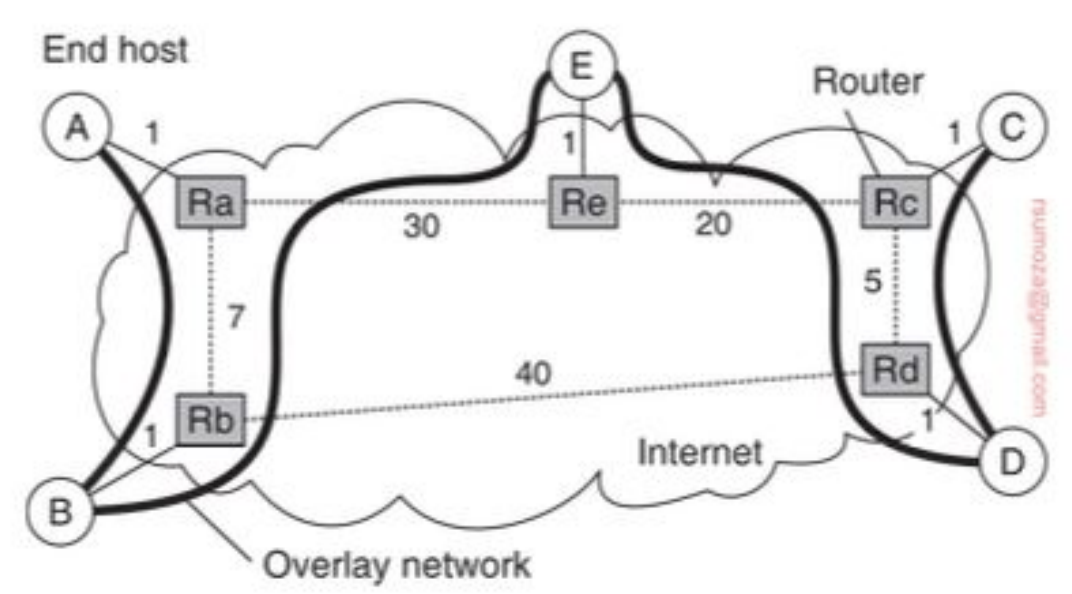
Métricas
Hay 3 métricas para medir la calidad del árbol: link stress, relative delay penalty (RDP) y tree cost.
Link Stress: cuántas veces un mismo paquete pasa por el mismo link físicoRDP: relación de demora entre seguir el camino de la red de aplicación y seguir el camino de la red física (aplicación/física) para llegar del nodo A al B. En general se promedian todos los RDP y se trata de minimizar ese valorTree Cost: es una métrica asociada al costo total del árbol. Para minimizarlo, es cuestión de encontrar un Minimal Spanning Tree (MST)
Particularidades
- Multicasting != broadcasting: cuando hago multicasting quiero enviar un mensaje a un conjunto de nodos, que no necesariamente son todos los nodos. Y obviamente quiero reducir la cantidad de nodos que procesan mensajes que no son para ellos.
- Una forma simple de resolver esto es tener multicast groups, sobre los que puedo hacer broadcasting. Son una overlay network sobre la overlay network original.
- Y para hacer broadcasting podemos usar el mecanismo de flooding: cada nodo envía el mensaje que recibió a todos sus vecinos, excepto al nodo que le envió el mensaje. También deberíamos evitar enviar mensajes que ya recibimos, lo cual requiere algún tipo de tracking.
- El mejor escenario es un grafo que sea un árbol (orden lineal de cantidad de mensajes), y el peor es un grafo completamente conectado (orden cuadrático).
- DISCRETE MATH MENTIONED 🗣️
Protocolos epidémicos
- Buscan propagar información rápidamente usando sólo información local
- Vamos a tener
- Nodos infectados (tienen el mensaje y lo van a compartir)
- Susceptible (no tiene el mensaje)
- Removidos (tiene el mensaje y no lo comparte)
- Y vamos a tener rondas, que son ventanas de tiempo en la que todos los nodos tomaron la iniciativa de intercambiar mensajes, una vez cada uno.
- Cada infectado elige a los próximos disponibles
- En estos casos, hablamos de modelos anti-entrópicos, ya que tienden al orden.
- Aquí cada nodo elige de forma random a otro vecino e intercambian updates.
- Una solución dentro de estos modelos es el de push/pull:
- Push no es una gran solución, porque conforme hay cada vez más infectados la probabilidad local de elegir un nodo susceptible es baja.
- Pull es más apropiado, porque conforme crece la cantidad de infectados los nodos susceptibles tienen más chances de elegir un nodo infectado.
- Push/Pull es la mejor solución y se puede demostrar empíricamente.
- Tenemos también algoritmos de gossiping o rumor spreading, los cuales funcionan de la siguiente manera: cuando el nodo P se contacta con el nodo Q para comunicarle un update y Q ya tenía ese update, con cierta probabilidad , P puede decidir volverse un nodo removido.
- Este método ta güeno para compartir información rápidamente pero no garantiza que todos los nodos van a recibir todas las actualizaciones. Para hacerla corta, es mucho más improbable saturar la red, puesto que puede pasar que no lleguemos a todos.
Certificados de distribución
- Para remover data tenemos que usar certificados de defunción de la data, de forma que si por alguna razón llega un update los nodos saben que tienen que ignorarlo.
- Los certificados pueden tener un timestamp que determina por cuánto tiempo tienen que almacenarse, de forma que los nodos solo los almacenen hasta un tiempo en el que se sabe que los mensajes viejos pueden seguir dando vuelta por el sistema
- Para garantizar un delete, algunos nodos van a mantener una lista de certificados permanente, de forma que si les llega un update sobre data que debería estar eliminada pueden volver a esparcir el certificado de defunción.
Coordinación
La idea es ordenar/orquestar 2 o más procesos para lograr un objetivo en común.
¿Por qué la estudiamos?
La coordinación es clave para determinar cuál es la verdad dentro del sistema.
Lo que necesitamos es que los nodos cooperen correctamente, tomando decisiones consistentes para evitar conflictos o errores. Ya tenemos comunicación, ahora necesitamos averiguar los mecanismos con los cuales vamos a llegar a la consistencia en algún punto.
Sincronización de relojes
- Las computadoras tienen varios circuitos dedicados a mantener el tiempo
- Tienen un cuarzo que soporta cierta tensión y oscila
- El circuito mide las oscilaciones del cuarzo y por cada una disminuye un contador predefinido
- Cuando el contador llega a cero, el reloj emite un tick
- Este tick es la unidad más chica de tiempo de la que disponemos.
- El cuarzo para estos relojes oscila a 32768 Hz
- Tienen una propiedad isoeléctrica por la cual se da la siguiente doble identidad:
- Aplico una transformación se genera un pulso eléctrico
- Tienen una propiedad isoeléctrica por la cual se da la siguiente doble identidad:
Los teléfonos coordinan sus relojes con un protocolo de coordinación llamado NTP.
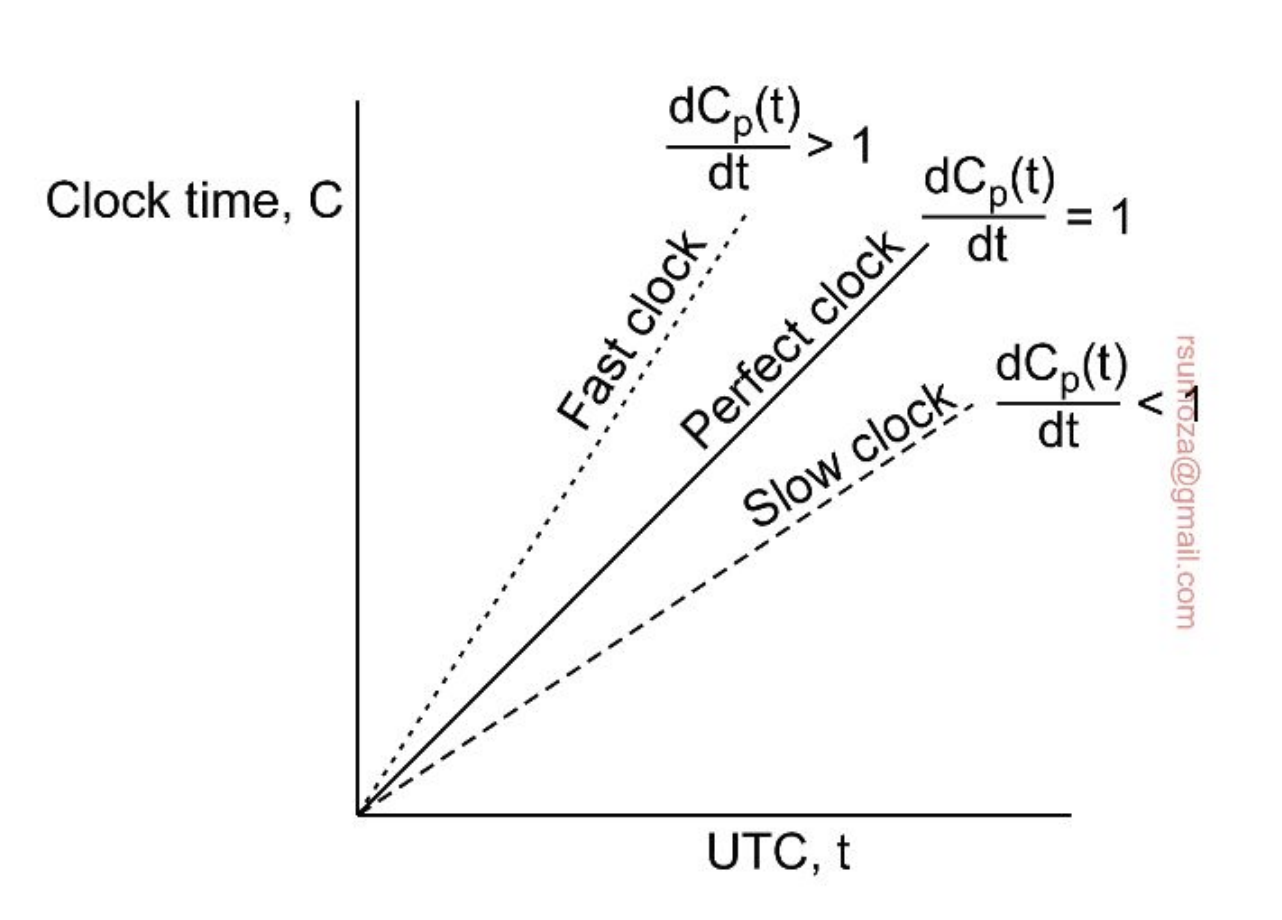
Sincronización
- Es imposible garantizar la coordinación de relojes físicos. Todo reloj tiene cierto sesgo y a lo largo del tiempo tienden a diferir más y más.
- Si yo a 2 relojes en algún momento con algún mecanismo los pongo a la misma hora, en algún momento van a desfasarse.
- Una primera solución a este problema es el Coordinated Universal Time (UTC), que se mantiene con antenas distribuidas a lo largo del planeta, que emiten un pulso por segundo. También existen satélites que emiten este pulso. Tienen una exactitud de +-10ms y +-5ns respectivamente.
- Los satélites tienen mucha menos interferencia.
- Estas antenas y satélites usan relojes atómicos que son mucho más precisos y su sesgo es despreciable.
Precisión y exactitud
- Para lograr precisión entre dos máquinas tenemos que la diferencia de tiempo entre dos máquinas sea menor o igual a un valor específico
- Para mejorar la exactitud tenemos que reducir la diferencia con el tiempo real
- P y Q son procesos
Mantener una buena precisión entre máquinas es IMPERATIVA para su coordinación, porque basta un desfasaje de un momento/tick/unidad de tiempo para que reviente todo por los aires.
Desviación
- Todos los relojes (de computadora) vienen con una desviación conocida, que suele ser de aproximadamente 31.5 segundos por año.
- Los de mano se suelen desfasar 30 seg por mes.
- Para mantener los relojes sincronizados, necesitamos realizar sincronizaciones de manera periódica
Algoritmos de sincronización
NTP (Network Time Protocol)
El Unix TimeStamp tiene el 0 (el primero de todos) en el 01/01/1970
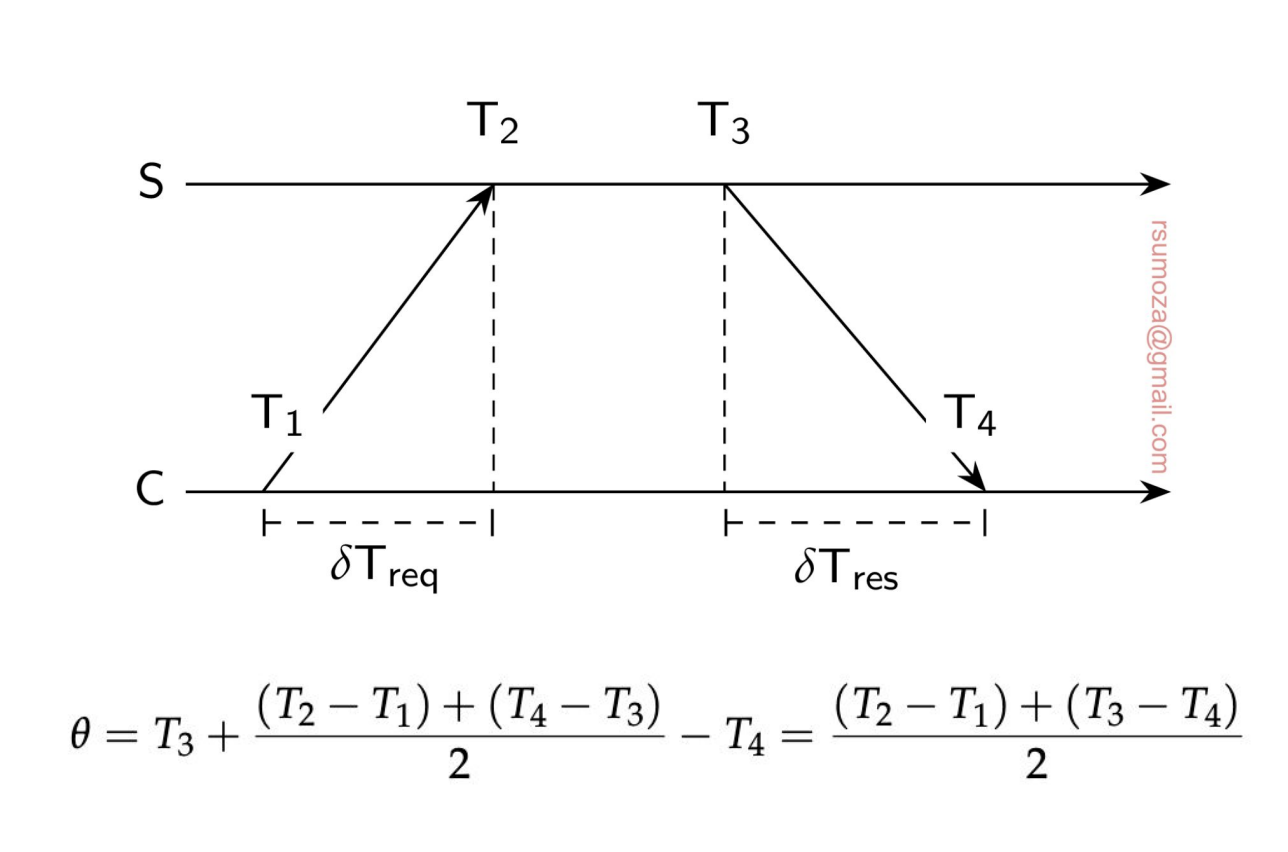
- Una solución es tener un timeserver que se encarga de decirnos qué hora es.
- Pero como los delays de la red no son despreciables, tenemos que tenerlos en cuenta también de forma de actualizar el reloj con el valor que nos da el server más un offset.
- No es trivial el tiempo que tarda en llegar la response.
- Si el tiempo del server es anterior al actual hay que ralentizar el reloj local
- En NTP particularmente hay un atributo de los relojes que es el estrato, que nos dice qué tan confiable es el reloj.
- El estrato 0 es el reloj en particular (UTC, relojes atómicos). Son lo más exacto que hay
- Este estrato sólo se consigue si tenés hardware que lo permita (es decir, tenés literalmente el reloj en particular)
- El estrato 1 es el servidor que existe alrededor del reloj puntual. Son servidores con mecanismos confiables.
- De acá para abajo (hasta N) baja la confiabilidad y la exactitud.
- El estrato 0 es el reloj en particular (UTC, relojes atómicos). Son lo más exacto que hay
Relojes lógicos
- Si nos interesa llevar un registro con exactitud, una solución como NTP es necesaria.
- Si todos estamos de acuerdo que A pasa antes que B, y B pasa antes que C, ya nos ponemos de acuerdo con cómo fueron las cosas, entonces no hay duda entre los procesos de cuál es el orden correcto
- Nos desacoplamos del tiempo, y nos fijamos específicamente en los eventos y su orden.
- Me importa lo que pasó y en qué orden, no cuándo pasó.
Lamport
- Si dos procesos no interactúan entonces no es necesario que estén coordinados. Su falta de sincronización no es observable, y por ende no genera problemas.
- No me interesa saber en qué orden pasaron las cosas si los procesos no se comunican entre sí.
- Para procesos que interactúan entre sí, Lamport define el happens-before
- a b. A pasa antes que B.
- Hay 2 reglas para el happens-before.
- Si A y B ocurren dentro de un mismo proceso, y A ocurre antes que B, entonces A B es cierto.
- Si A es el evento en el que un proceso envía un mensaje X, y B es el evento en el que otro proceso recibe el mensaje X, entonces A B es cierto. Un mensaje no puede recibirse antes de ser enviado.
- Happens-before es transitivo (A B y B C A C)
- Si ni X Y ni Y X, entonces X e Y son concurrentes.
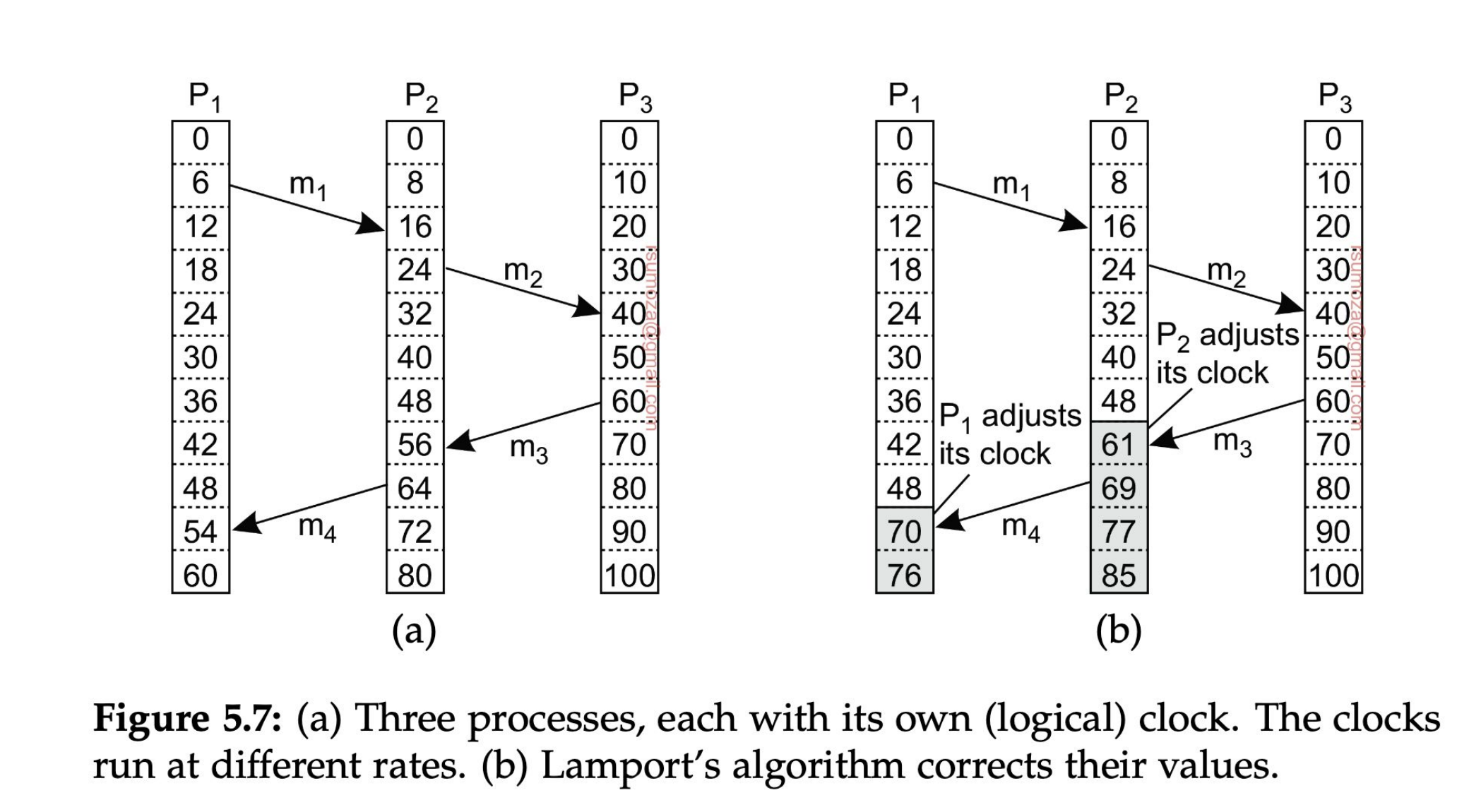
- Fíjense en la figura de la derecha que los relojes se auto-ajustan porque, por definición de Lamport, es imposible recibir un mensaje antes de que se haya enviado.
- Por tanto, los relojes le agregan uno al momento en el que salió el mensaje desde el otro proceso.
Relojes de vectores
Los relojes lógicos tienen un problema subyacente:
- Con los relojes lógicos tenemos mensajes que van y vuelven por el mismo camino, a través del cual puedo rearmar la causalidad.
- ¿Qué pasa cuando tengo muchísimas interacciones/eventos? ¿Y si tenemos eventos que existen no sólo por comunicación sino que son generados por el proceso per se?
- Seguir la causalidad en estos casos es un bodrio, es casi imposible.
- ¿La solución? Un reloj de vectores.
Nosotros sabemos cuántos procesos existen, y por cada posición de ese vector que usamos como reloj tenemos un proceso.
- Cada proceso mantiene un contador de eventos asociados a c/u de los procesos
- Entonces en todo momento cada proceso tiene su versión local del clock de todos los procesos.
- Si llega una nueva versión con valores más altos para cualquier posición en comparación con la local, se actualiza.
Cuando detectamos un conflicto en la sincronización de los relojes de vectores, tenemos que tomar alguna decisión arbitraria. El manejo de conflictos es muy similar al de los VCS (Git, por ejemplo).
Podemos determinar la posible precedencia de 2 eventos en base a la siguiente proposición:
Sea y . Decimos que si para toda posición se cumple que , y además existe al menos una posición tal que . Es decir, todos los elementos pueden ser iguales o mayores, pero al menos uno debe ser estrictamente mayor; si esto no se cumple, no se puede definir una relación de precedencia estricta entre los vectores.
A efectos de este ejemplo, se usan sólo 3 procesos para el reloj, pero en un caso real pueden haber N procesos participando.
Sobre el papel, es muy difícil determinar la causalidad de manera definitiva, por lo que decimos que si A ocurre antes que B, B pudo haber sido causado por A, pero no asegurarlo.
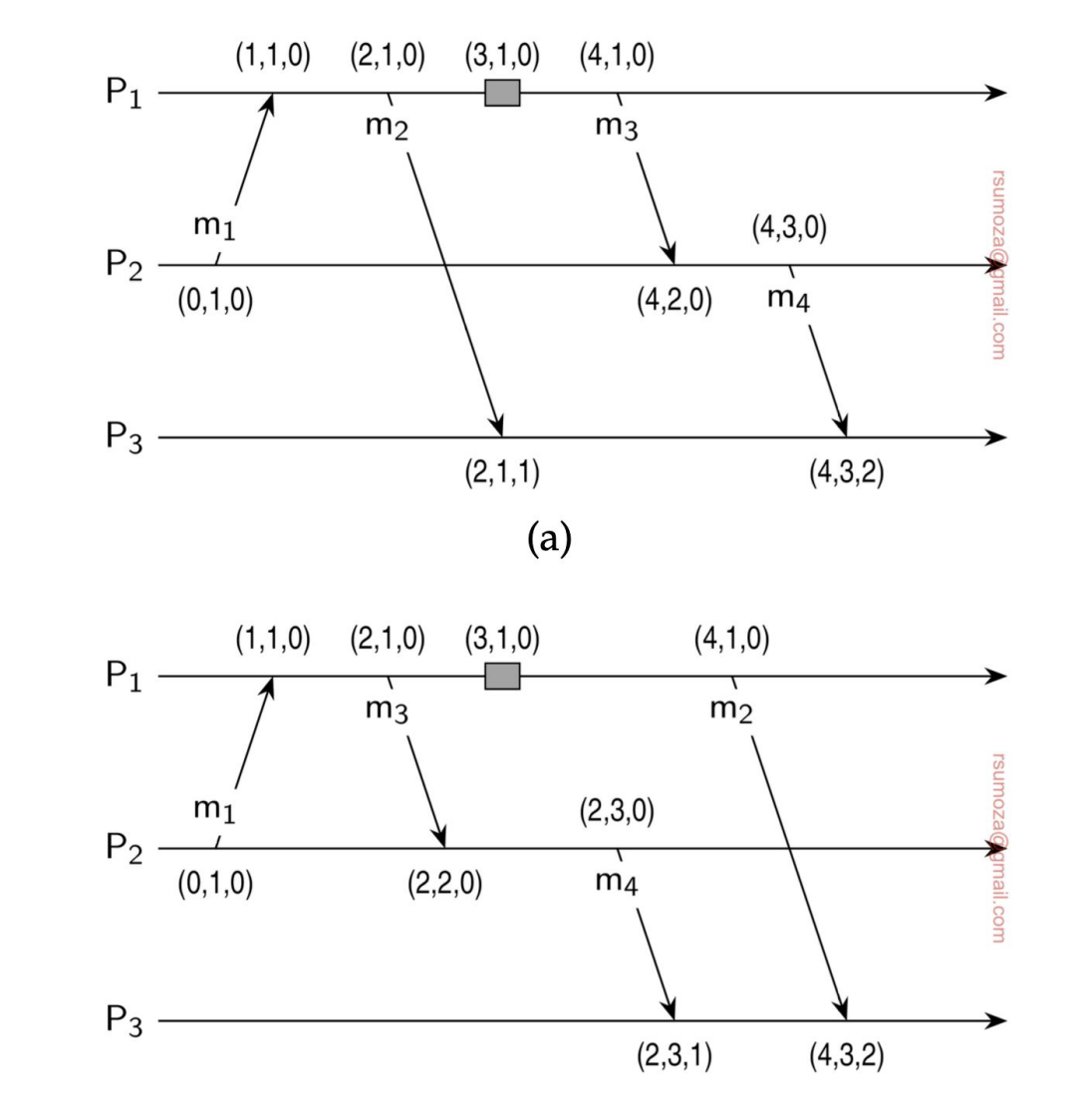

Exclusión mutua
Hay alguien que tiene el control sobre el recurso en este momento, en principio nadie más puede leerlo ni modificarlo.
Podemos empezar a determinar roles en estos casos, para determinar un esquema de jerarquía sobre los recursos.
Solución centralizada
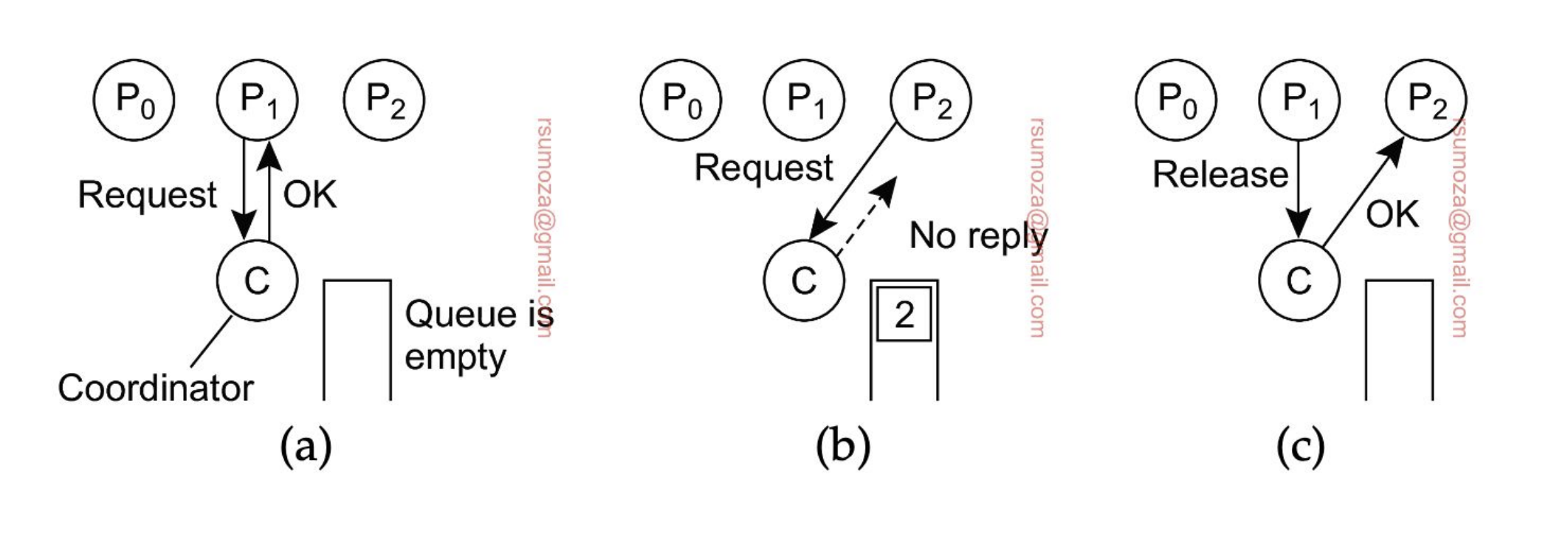
- El coordinador (uno solo) es el que se encarga de proteger/administrar el recurso
- El resto de procesos le piden acceso al recurso.
- Si me dice OK, puedo acceder al recurso
- Si otro proceso quiere acceder al mismo tiempo que otro, no se le responde nada, y se encola.
- Cuando se libere el recurso, se le manda un OK al proceso encolado
Problema subyacente: se genera un SPoF (Single Point of Failure), el cual es el coordinador. Si se muere el coordinador y se quiere recuperar, se puede llegar a perder la Queue, dando lugar a la posibilidad de generar Starvation.
Beneficio: es simple, fácil de entender, administrar, implementar, es sencillo debuggearlo.
Solución distribuida - Algoritmo de Ricart
El algoritmo de Ricart original consiste en que cuando un nodo necesita acceder a un recurso, le pide permiso a todos los nodos del sistema. Si al menos uno le contesta que no, no opera. El que vemos es una optimización sobre Ricart que hace uso de los timestamp.
- Cuando un proceso quiere acceder a un recurso compartido, envía un mensaje con el nombre del recurso, su ID y su timestamp a todos los nodos (incluso a sí mismo).
- Luego, hay 3 escenarios diferentes para cada nodo:
- Si no quiere acceder a ese recurso devuelve un OK
- Si tiene acceso al recurso, encola el mensaje y no responde nada
- Si quiere acceder al recurso pero todavía no lo hizo, compara su mensaje con el que recibió.
- El que tenga el timestamp más chico, gana. Se basa 100% en el orden en el que se envían los mensajes.
- Si gana el mensaje entrante, devuelve un OK. Si no, encola el mensaje
- Un proceso sólo va a acceder al recurso cuando haya recibido un OK de todos los otros procesos.
¿Cómo se da cuenta si él mismo quiere acceder al recurso? Se fija en la queue interna si tiene un mensaje suyo.
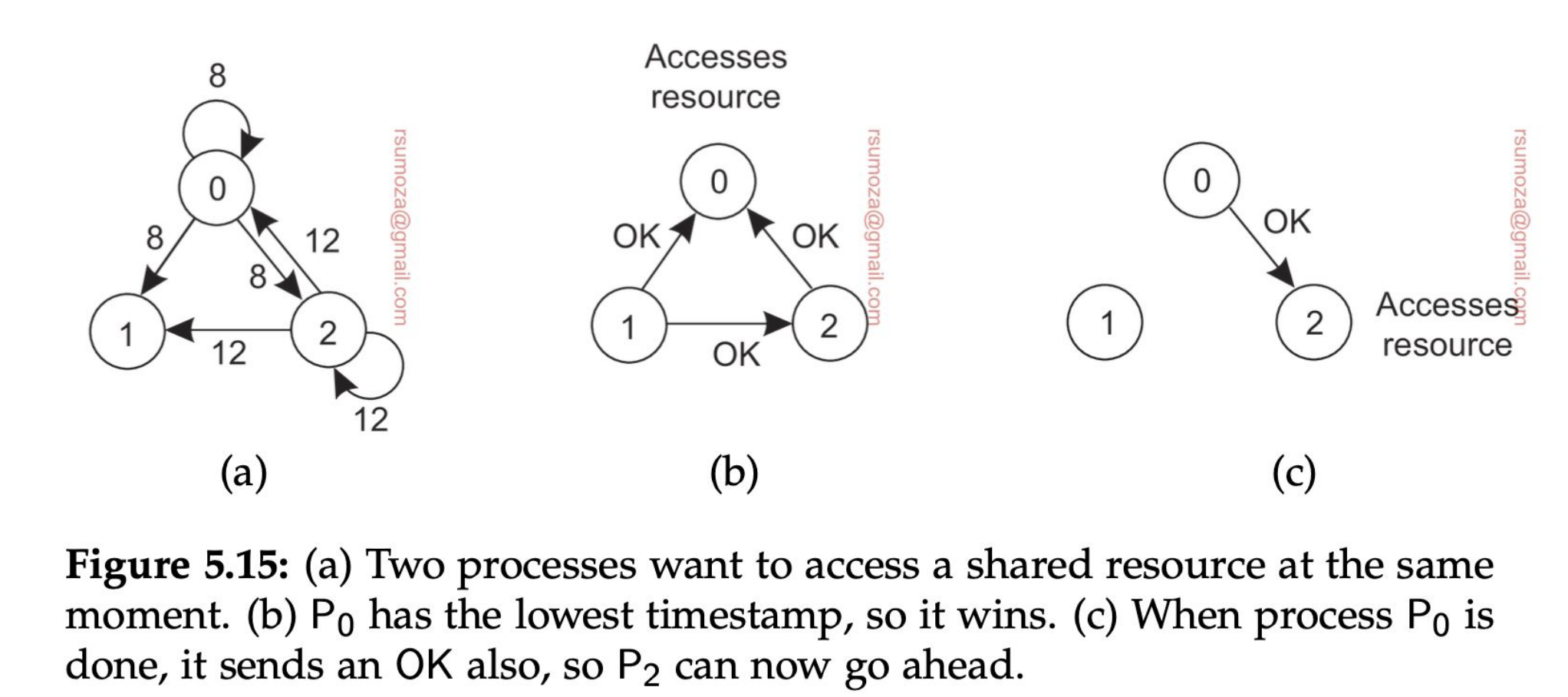
Se puede dar starvation en el caso de que el timestamp de 0 siempre sea más chico que 2 y que los procesos estén desordenados. Esto claramente no va a pasar si usamos una Queue bien estructurada, ya que los procesos se van a ordenar.
Problema: Si uno de los procesos se cae, se bloquean todos.
Solución distribuida - Token Ring
Es un anillo en el que se van a organizar los procesos. En principio, un proceso sólo conoce el próximo proceso.
En exclusión mutua, tenemos 2 escenarios:
- Token Based: se usa un token (llave) para habilitar el acceso a recursos
- El token tiene que ser difícil de replicar.
- Permission Based: en algún momento conseguimos el permiso del resto de los nodos. El ejemplo anterior es permission-based
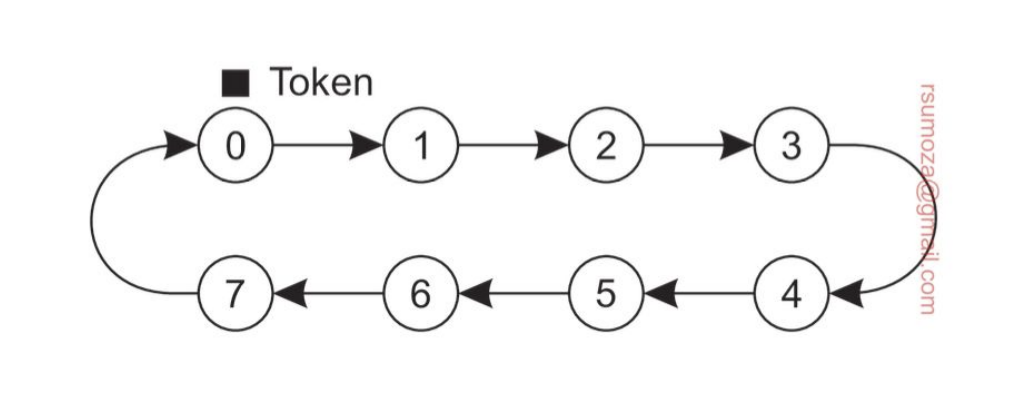
- Cuando el anillo se inicializa, a uno de los procesos se le da el token. Si en ese momento quiere usar el recurso puede hacerlo, y cuando termina pasa el token al siguiente del anillo. Está prohibido que use el token inmediatamente después de haberlo usado.
- Si al recibir el token el proceso no quiere acceder al recurso, simplemente pasa el token
- Problema: Si se pierde el token, ¿cuándo se regenera?
- Puedo tener también problemas de espera en función del tamaño del anillo.
- Beneficio: evitamos starvation porque el token tiene que pasar de mano y, si uso el mismo token puedo evitar el deadlock.
Algoritmos de elección
Los necesitamos para poder entender más adelante cosas que vamos a ver al final de la materia.
- Muchos algoritmos distribuidos requieren la existencia de un nodo coordinador. Pero, ¿cómo nos ponemos de acuerdo en quién es el coordinador?
- Los nodos tienen que tener algún mecanismo para elegir y ponerse de acuerdo en cuál es el coordinador
- Para poder diferenciar a los nodos es necesario que todos tengan un ID único
- En general lo que se hace es designar como coordinador al proceso con ID más grande.
- Además es importante que todos los nodos conozcan al resto de nodos. Lo que pueden no conocer es su estado.
Vamos a usar 2 criterios para elegir un coordinador:
- Todos los nodos se conocen entre sí
- El coordinador es el del ID más grande
- Es ineficiente cuando hablamos a gran escala
Los escenarios en los cuales vamos a usar algoritmos de elección son:
- Cuando se cayó el último coordinador
- Cuando se inicializa el sistema y no está decidido el coordinador
Algoritmo bully
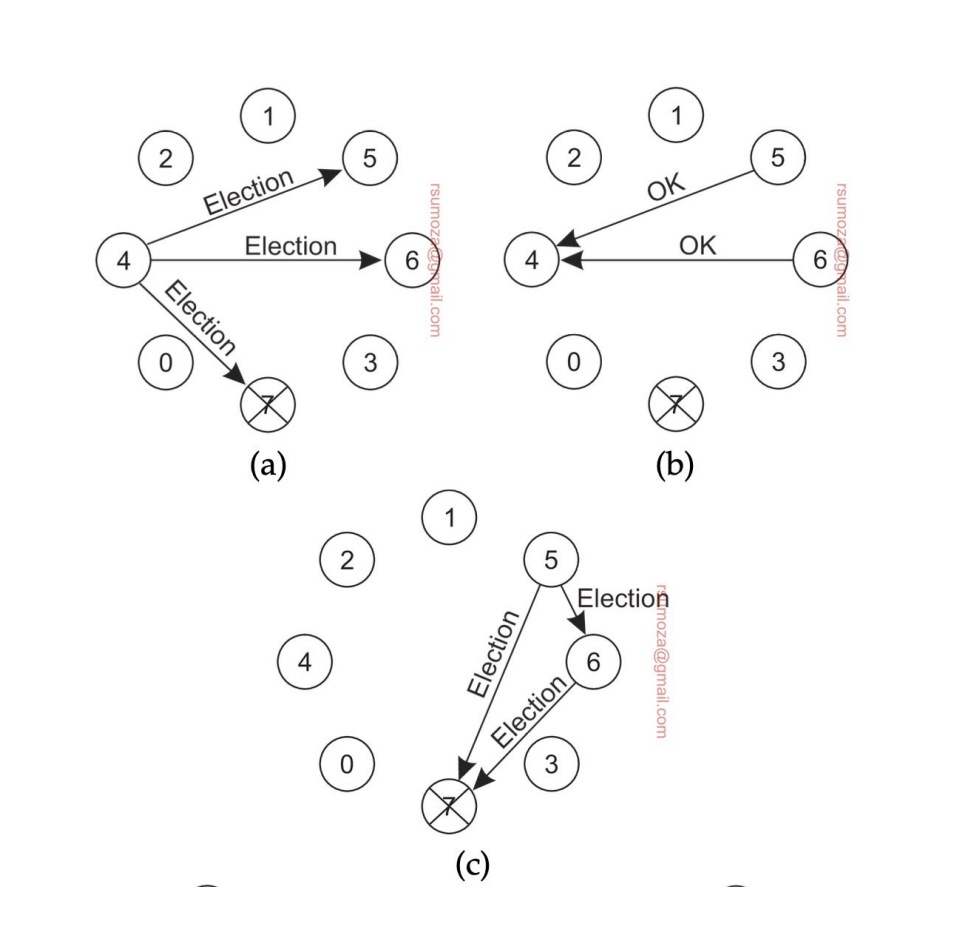
- Cuando un proceso detecta que el coordinador no responde, inicia una elección
- Envía un mensaje de elección a todos los nodos con ID mayor al suyo
- No me interesan los nodos más chicos que el nodo que inicia la votación
- Si ninguno responde, este nodo gana la elección
- Si alguno responde significa que ese nodo se encarga de seguir la elección, repitiendo el mismo proceso.
- Si algún proceso se recupera o se suma al sistema, arranca otra elección
- Si el que aparece es el del ID más grande, le manda un mensaje a todos los nodos diciendo que él es el coordinador.
- Si el que aparece es el más chico, arranca la votación de vuelta.
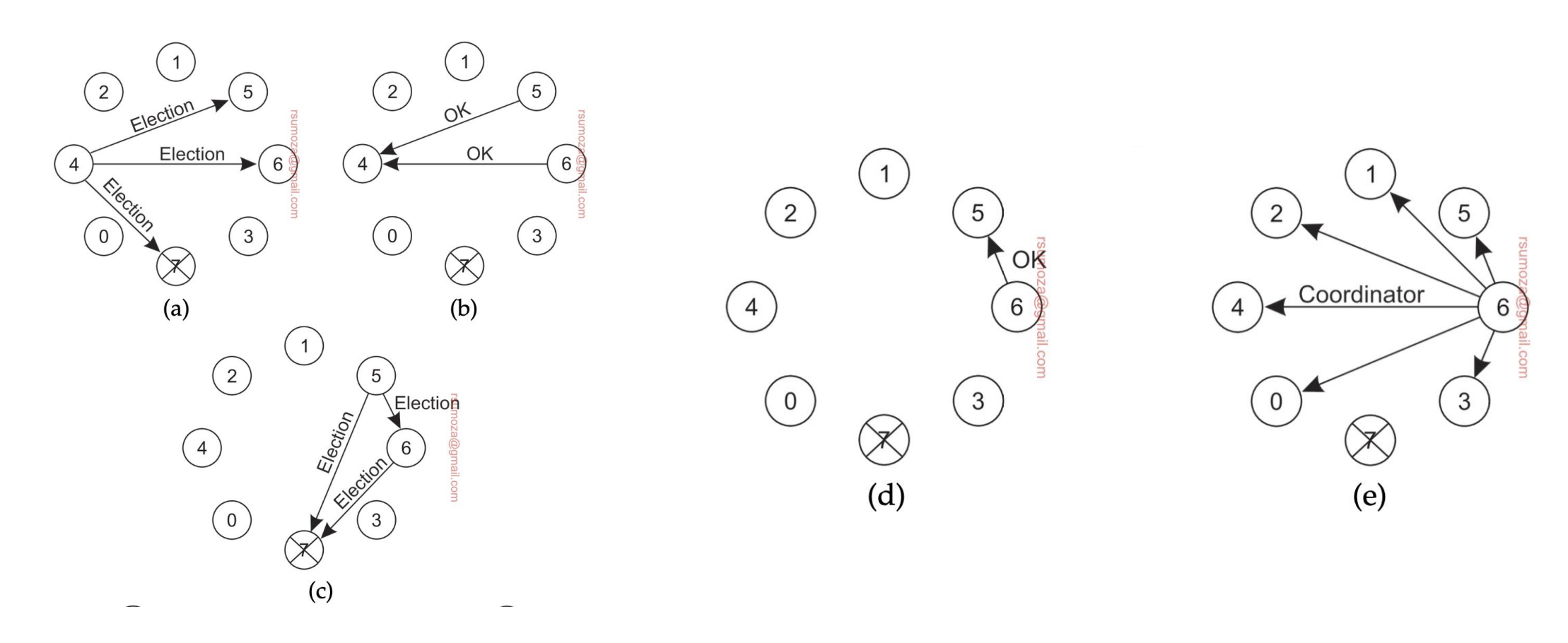
Algoritmo del anillo
Que el sistema esté diseñado como un anillo no implica que la red de elección sea en forma de anillo. Son 2 cosas inherentemente diferentes.
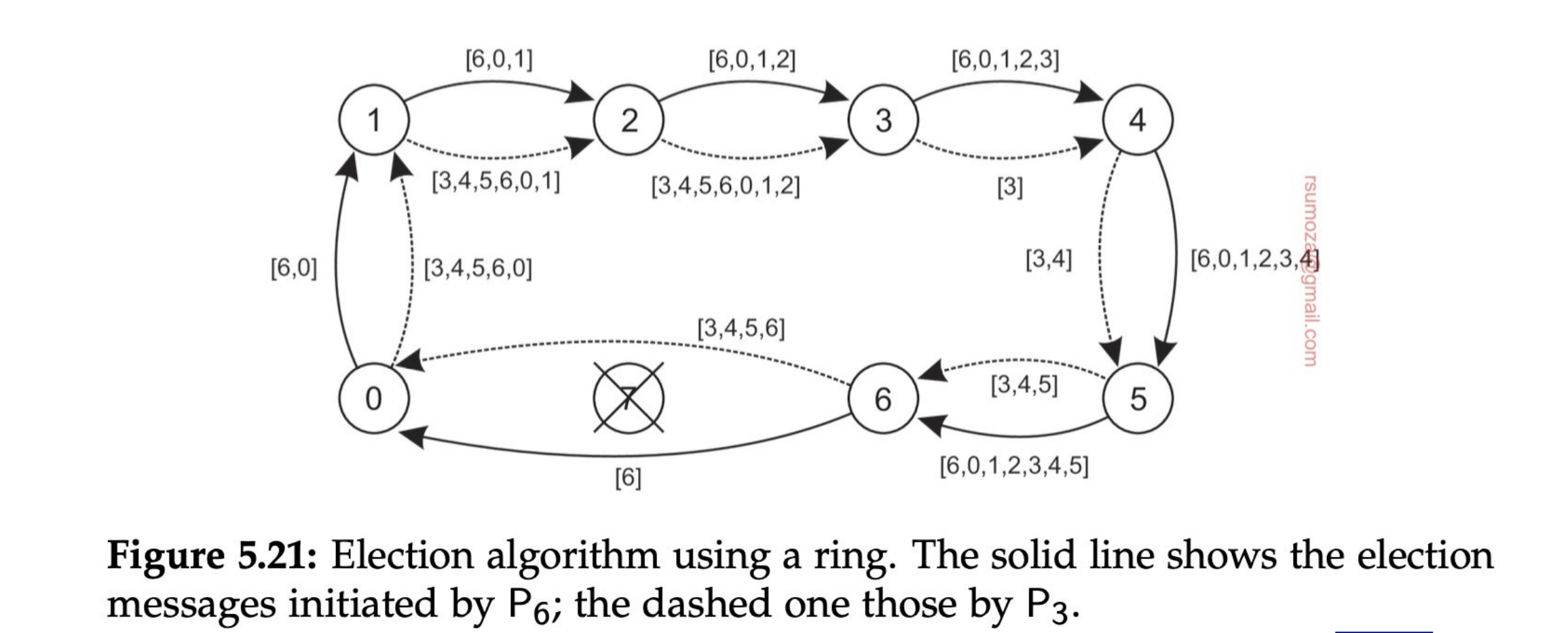
- Los nodos se organizan en una overlay network con forma de anillo.
- Cuando un nodo detecta que el coordinador no está funcionando, empieza una elección enviando un mensaje ELECTION con su ID al próximo proceso.
- Cada proceso suma su ID a la lista, y envía el mensaje al próximo proceso
- Finalmente el proceso que originó la elección recibe una lista con su propio ID. De todos los IDs, se selecciona el más grande, y lo comparte con un mensaje COORDINATOR con el próximo elemento, a lo largo de todo el anillo.
- Si cualquier nodo no responde el mensaje se envía al próximo proceso que esté funcionando del anillo.
Si 2 nodos detectan en simultáneo que se cayó el coordinador y arrancan la elección, el resultado va a ser el mismo, solamente va a haber más pasamanos porque van a haber 2 listas circulando.
Cada nodo que se anota en la lista, por más que sepa que no va a ser el coordinador, se anota para notificarle al resto que está vivo.
Algoritmo de Raft
Es un algoritmo basado en términos. Hay momentos para elecciones. Una elección arranca en el momento A y termina en el momento B, existe una ventana de tiempo.
Ningún nodo tiene ninguna jerarquía, solo se determina por quién pide ser coordinador.
Este algoritmo falla cuando más de un nodo pide ser coordinador.
Sistemas de gran escala - Proof of work
Hay un líder que le dice al resto "la versión real es esta".
- Hashing: toma un input cualquiera y produce una cantidad fija de bits. Calcular un hash debería ser barato computacionalmente. Pero calcular un input al que le corresponda el mismo hash. Y siempre o casi siempre, sin importar cuán mínima sea la diferencia, si dos inputs son diferentes van a producir hashes diferentes.
- Entonces es muy fácil garantizar que cualquier cambio a la blockchain va a generar un hash necesariamente diferente
- Esto hace que modificar la blockchain sin que el resto de los validadores se den cuenta sea prácticamente imposible.
- Cada validador produce un hash para el nodo que está procesando, que se llama digest.
- El desafío es calcular el nonce: un valor que, cuando se combina con el digest y se hashea, produce un valor con una cierta cantidad de ceros consecutivos al principio del hash final.
- El validador que lo encuentre primero pasa a ser líder, pero la probabilidad de encontrar un nonce válido es de
- En general este proceso suele tomar 10 minutos a nivel global
- Un nodo encontró un nonce a nivel global.
- Esto puede ajustarse cambiando la cantidad de ceros que se piden (suelen ser 64 ceros) de forma buscar un balance entre el tiempo que se tarda en calcular y posibles conflictos.
Elecciones en sistemas wireless
- Muchas de las propiedades que asumimos como ciertas en otros escenarios (los mensajes siempre llegan, la topología no cambia, la red es confiable) no son ciertas para sistemas wireless.
- Necesitamos un algoritmo capaz de elegir al mejor nodo
- Para eso, necesitamos un algoritmo que pueda conseguir información de todos los nodos disponibles en ese momento.
Naming
Conceptos básicos
- Los nombres juegan un papel importante en todos los sistemas informáticos
- Se usan comúnmente para compartir recursos, identificar entidades de manera única, hacer referencia a ubicaciones y más.
- Se traduce como "nombramiento" o "designación".
Todos los servicios de Internet necesitan un esquema de direccionamiento para poder ubicar un recurso.
La resolución de nombres se distribuye a través de múltiples nodos.
- Un nombre puede resolver la entidad a la que se refiere
- De esta forma la resolución de nombres permite que un proceso acceda a la entidad nombrada.
- Para resolver nombres, es necesario implementar un sistema de nombres
- La diferencia entre los nombres de los sist. distribuidos y no distribuidos radica en la forma en la que se implementan los sistemas de naming
- Los sistemas distribuidos implementan el sistema de naming de manera distribuida en múltiples máquinas
- En los no distribuidos los nombres están centralizados en un nodo.
Para los fines de esta materia se considerarán 3 tipos de sistemas distribuidos de naming:
- Flat Naming System (Sistema de direccionamiento plano)
- Se suele implementar en redes P2P (punto a punto) porque normalmente incorporan la información de las redes de los nodos vecinos
- Van haciendo un "teléfono descompuesto" basado en preguntar "¿vos tenés este recurso?"
- Ejemplo: BitTorrent.
- No hay un servidor centralizado que tiene todo, sino que la info está distribuida entre nodos.
- Los sistemas están preparados para la desconexión
- Se suele implementar en redes P2P (punto a punto) porque normalmente incorporan la información de las redes de los nodos vecinos
- Structured names (nombres estructurados, como por ejemplo DNS)
- Named Based Routing (enrutamientoi basado en nombres o características)
Pregunta de parcial: ¿DNS se puede aplicar sólo en Internet?
Respuesta: No, se puede aplicar a nivel organizacional y poner nombres puntuales a recursos dentro del dominio de una empresa, por ejemplo.
- Los nombres se usan para designar entidades en un sistema distribuido
- Para operar con una entidad, necesitamos acceder a ella mediante un punto de acceso
- Los puntos de acceso son entidades que se nombran mediante una dirección
- Una entidad puede ofrecer más de un punto de acceso
- Ej: puedo contactarme con Juan a través de su celular o de su teléfono de línea
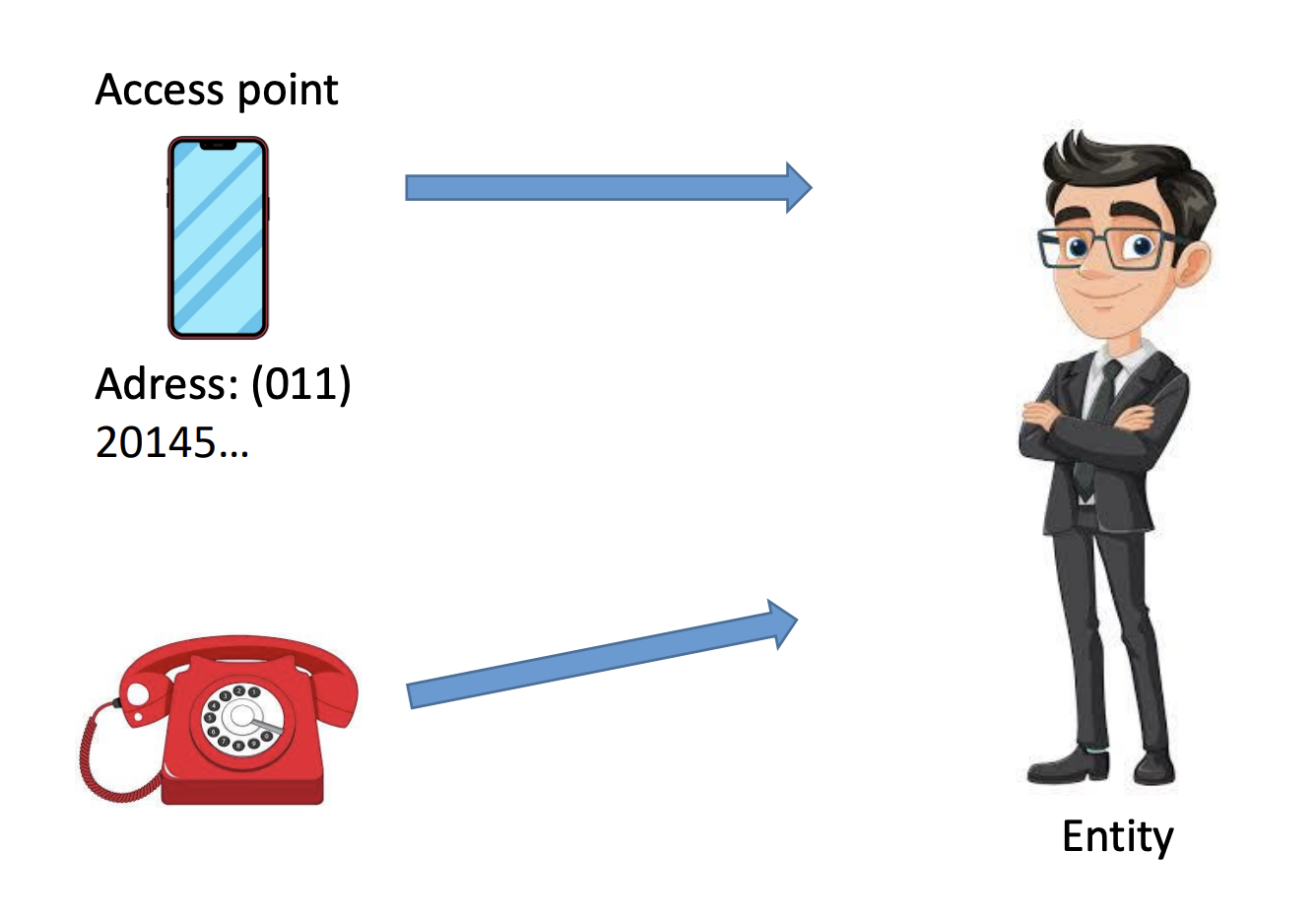
En un sistema distribuido, un ejemplo típico de un punto de acceso es un host que ejecuta un servidor específico, con su dirección formada por la combinación de, por ejemplo, una dirección IP y un número de puerto.
- Del mismo modo, si una entidad ofrece más de un punto de acceso, no queda claro qué dirección usar como referencia.
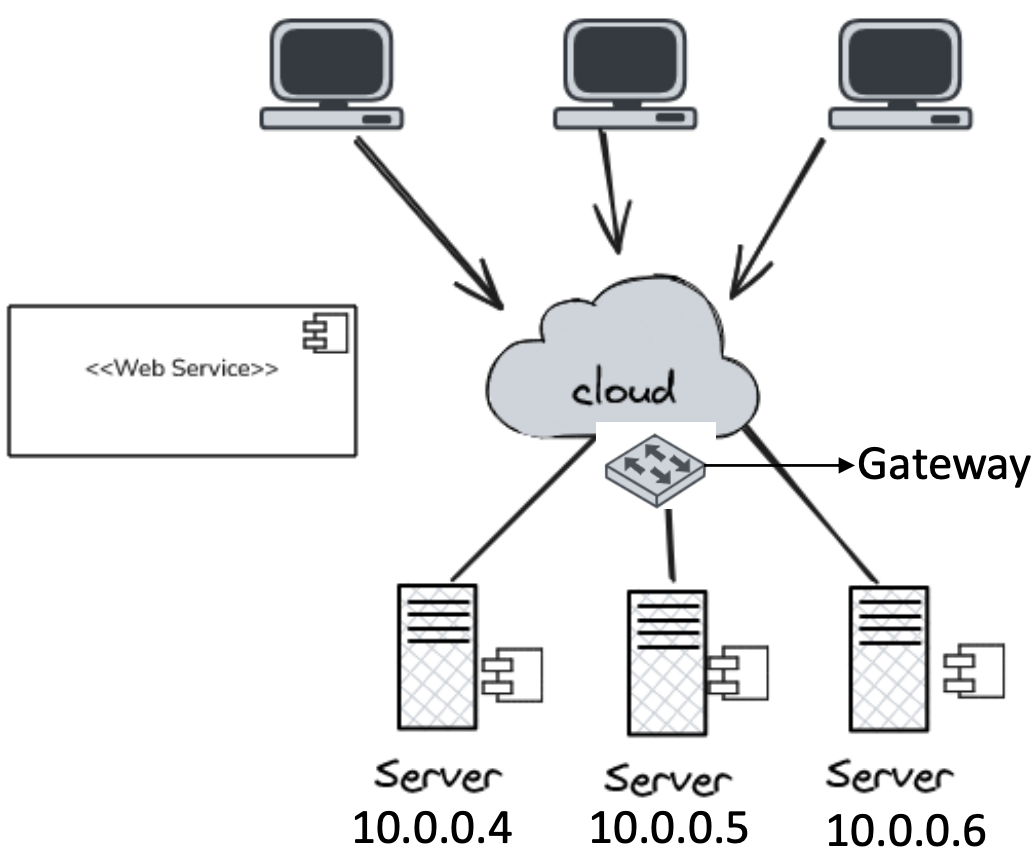
Gateway: puerta de enlace o de salida. En este caso me va a permitir redireccionar cada cliente a cada servidor, o avisarme
- Una solución mucho mejor es tener un solo nombre para el servicio web, independientemente de las direcciones de los diferentes servidores web. (De esta manera, va a ser un esquema simplificado)
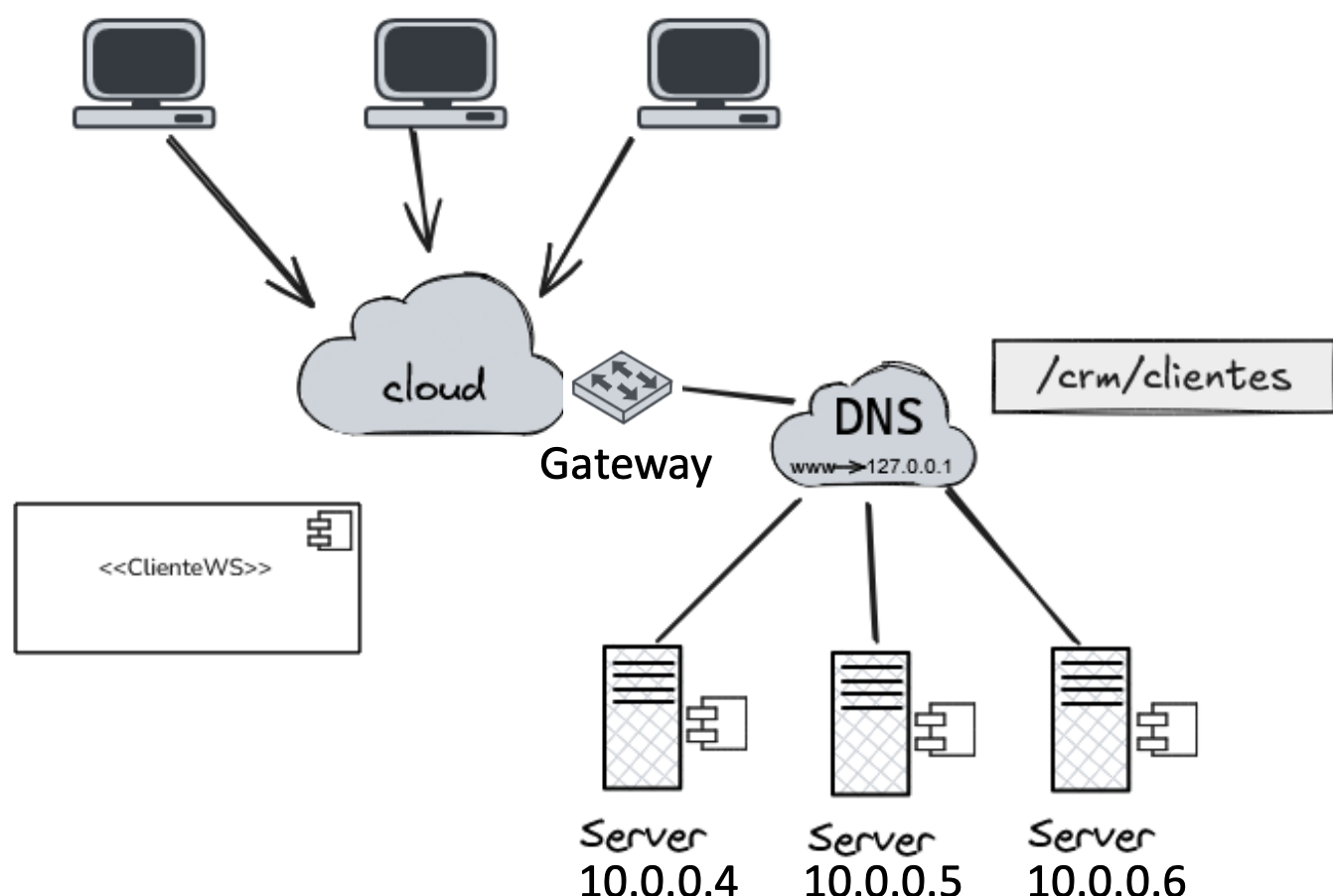
- Esta variante es independiente de la ubicación (en cuanto a su dirección IP)
Estos ejemplos ilustran que un nombre para una entidad que sea independiente de sus direcciones suele ser mucho más fácil y flexible de usar
Este tipo de nombre se denomina independiente de la ubicación.
Las direcciones y los identificadores.son dos tipos importantes de nombres que se utilizan para propósitos muy diferentes.
Otro tipo importante de nombre es el que está diseñado para ser usado por humanos, también conocidos como nombres amigables para los humanos (como los nombres DNS).
¿Cómo resolvemos nombres e identificadores en direcciones?
Tanenbuam presenta 2 enfoques:
- Mantener una tabla (generalmente distribuida) de pares (nombre, dirección). DNS usa este enfoque
- En el segundo enfoque, un nombre se resuelve enrutando la solicitud gradualmente a la dirección asociada al nombre o incluso directamente a un punto de acceso. Usualmente utilizado en sistemas estructurados de pares (peer-to-peer).
Flat Naming System
En estos sistemas existe un identificador que en principio no tiene mucho significado ni estructura, por lo que necesitamos una forma de rastrear la entidad.
No tienen estructura, lo que implica que necesitamos mecanismos especiales para rastrear la ubicación de dichas entidades.
A menudo, los identificadores son simplemente cadenas de bits aleatorias, a las que nos referimos convenientemente como nombres no estructurados o planos.
No tiene información de cómo llegar al punto de acceso desde la entidad asociada.
Tenemos 2 soluciones para alcanzar una entidad:
- Fordwarding pointers (punteros de difusión)
- Broadcasting
Ambas soluciones son aplicables principalmente sólo a redes de área local.
El router me permite saltar entre redes, pero el switch no. La información queda dentro de la red del switch, a menos que sea un switch de Capa 3.
Broadcast
Difundir el ID (por Broadcast), solicitando a la entidad que devuelva su dirección actual
- Nunca puede escalar más allá de las redes de área local
- Requiere que todos los procesos escuchen las solicitudes de ubicación entrantes
ARP (Address Resolution Protocol)
- Para saber qué dirección MAC está asociada con una dirección IP, hay que hacer broadcast de la consulta "¿quién tiene esta IP?"
Capa de enlace (OSI) maneja direcciones MAC.
arp -d: borra la tabla de direcciones
Forwarding pointers (punteros de reenvío)
Cuando una entidad se mueve, deja atrás un puntero que indica su próxima ubicación.
- La desreferenciación puede ser completamente transparente para los clientes siguiendo la cadena de punteros
- Se debe actualizar la referencia de un cliente al encontrar su ubicación actual
- Problemas de escalabilidad geográfica (para los que se requieren mecanismos de reducción de cadena independientes):
- Las cadenas largas no toleran fallos
- Mayor latencia de red al desreferenciar
Home based approach (enfoque basado en origen)
Tengo una cierta cantidad de ubicaciones fijas, que de alguna manera reenvían la información.
Las ubicaciones fijas redireccionan las IP en una cierta ubicación de origen, de manera que no tenga que armar cadenas demasiado largas.
- Se realiza un seguimiento de la ubicación actual de una entidad
- El enfoque basado en el origen se usa como mecanismo de respaldo para los servicios de ubicación basados en punteros de reenvío
- Otro ejemplo donde se sigue el enfoque basado en el origen es en IP móvil (para dispositivos móviles). Cada host móvil tiene una dirección IP fija.
- Los datos móviles te permiten conectarte de manera directa con el proveedor de servicios (Movistar, Personal, etc.)
Esquema de un solo nivel: permitir que un home (origen) lleve un registro de dónde se encuentra la entidad
- La dirección de origen (home address) de la entidad registrado en un servicio de nombres
- El origen (home) registra la dirección externa de la entidad.
- El cliente contacta primero con el origen (home) y luego con la ubicación foránea o externa (foreign location).
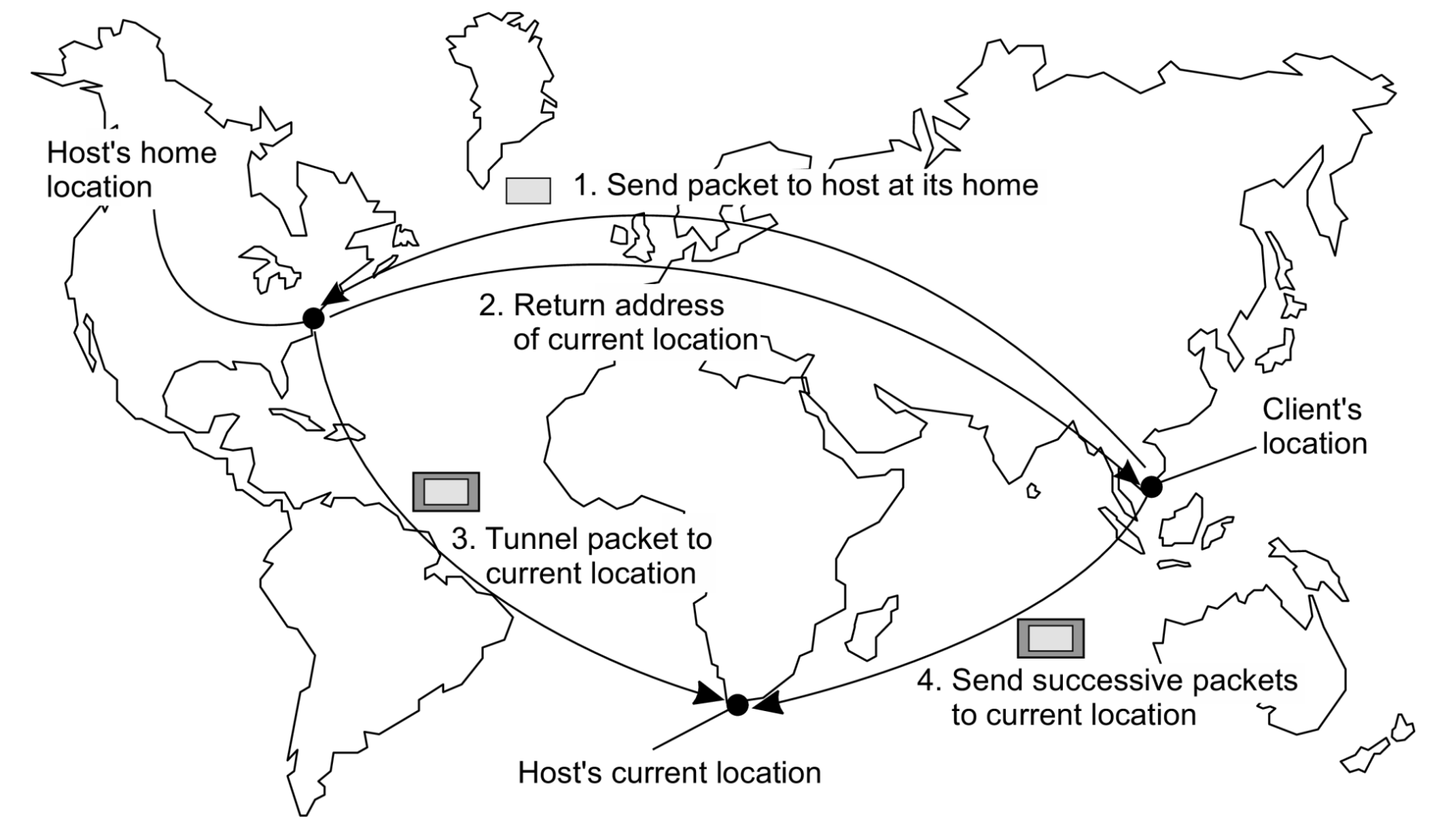
Problemas
- La dirección particular debe mantenerse durante toda la vida útil de la entidad
- La dirección particular es fija una carga innecesaria si la entidad se muda permanentemente
- Baja escalabilidad geográfica (la entidad puede estar junto al cliente).
Distributed Hash Tables
- Cuando necesito comunicarme con una entidad móvil, el cliente primero debe contactar con su origen, que puede estar en una ubicación completamente distinta a la de la propia entidad.
- Esto provoca un aumento de la latencia de la comunicación.
Cómo resolver un identificador en la dirección de la entidad asociada.
- En la última década se han desarrollado muchos sistemas basados en DHT.
- El sistema Chord (cuerda/anillo) es un representante típico
- Cada miembro del anillo tiene un puntero al siguiente miembro, y una tabla que muestra, en cada miembro,
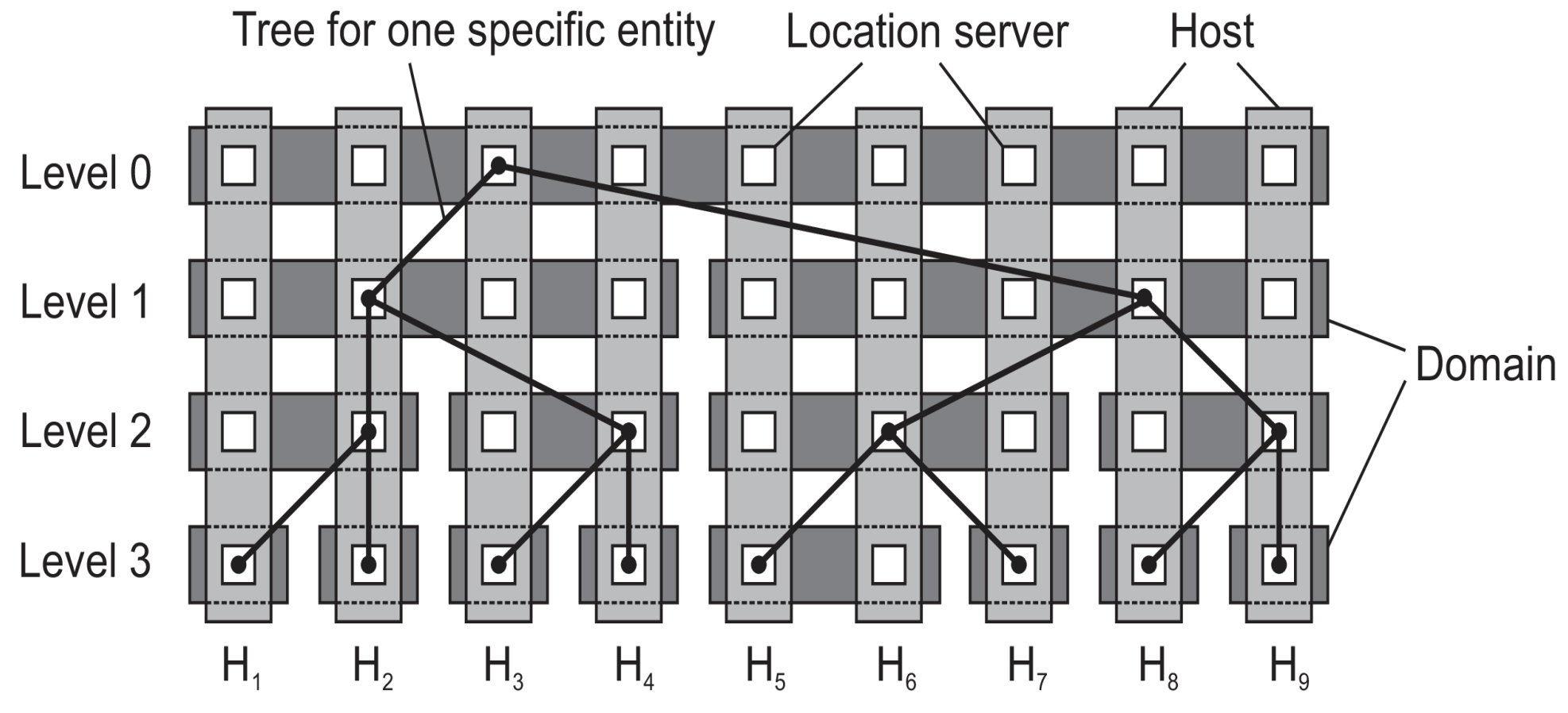
Sistemas de ubicación jerárquica (HLS)
- Construir un árbol de búsqueda a gran escala cuya red subyacente se divide en dominios jerárquicos
- Cada "dominio" está representado por un nodo de directorio independiente
- Tener un espacio de nombres dividido acelera el tiempo de búsqueda.
- Tengo una frecuencia mayor de comunicación en un espacio reducido que en el espacio total.
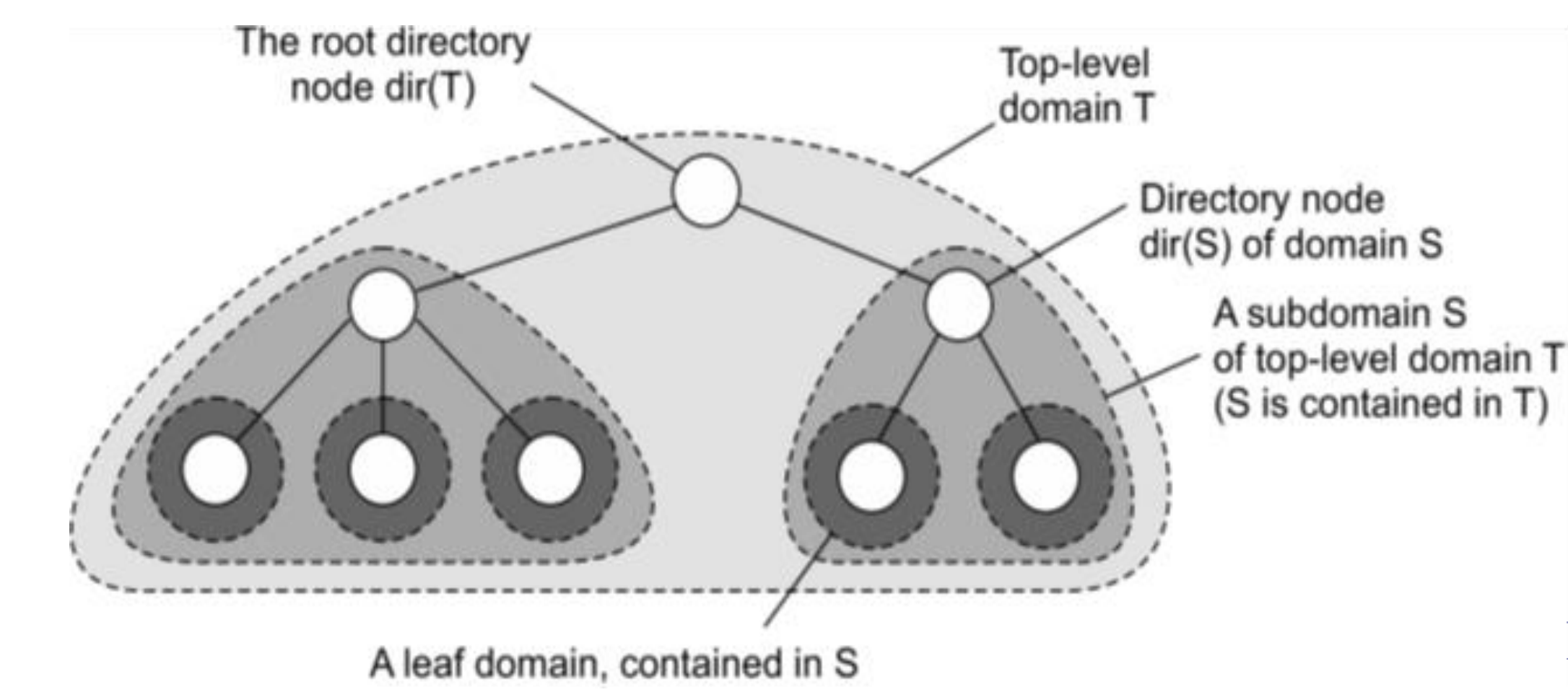
No confundir con DNS; DNS usa nombres fáciles para el usuario, mientras que HLS sigue manejándose por direcciones IP.
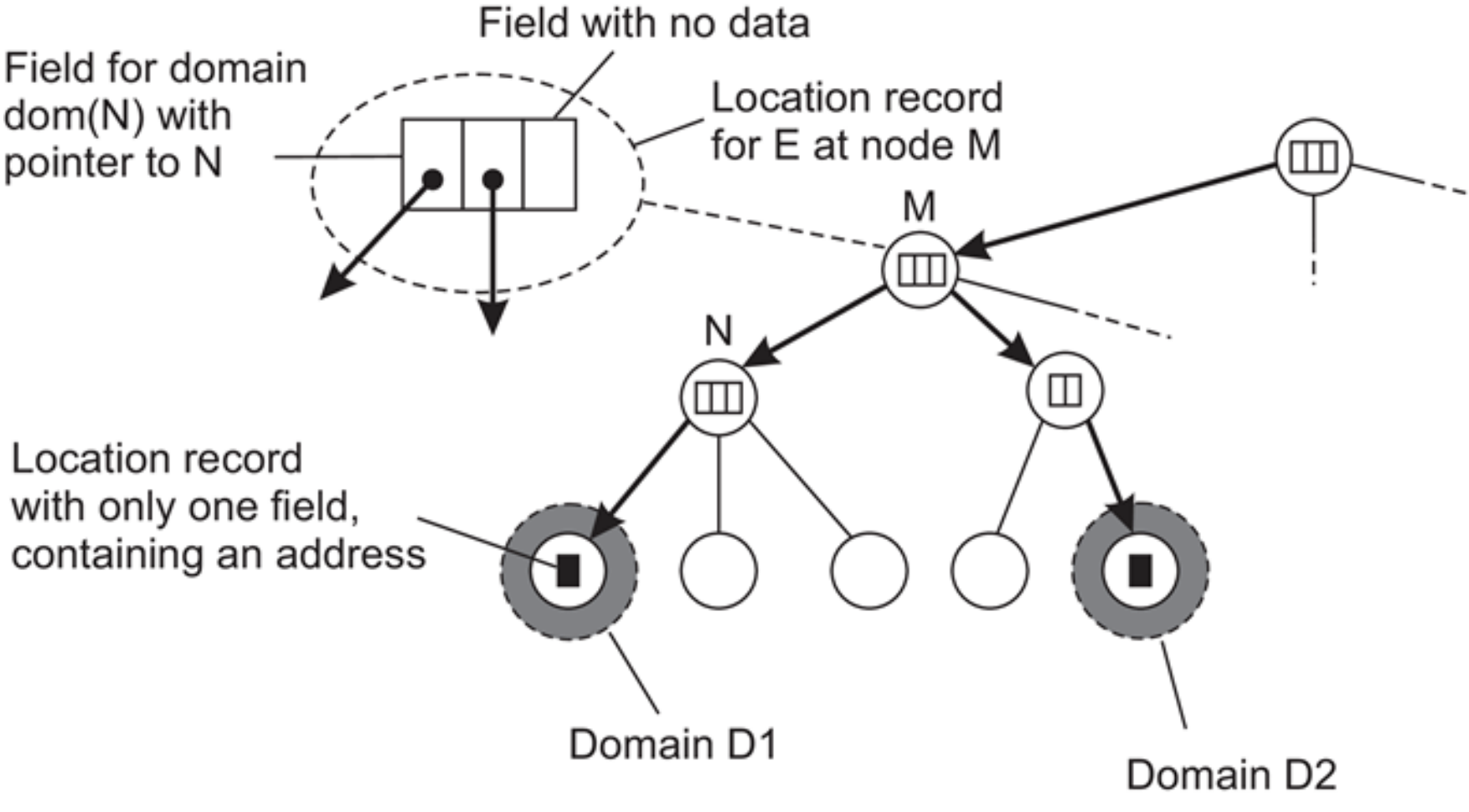
Nomenclatura de HLS
Invariantes:
- La dirección de la entidad E se almacena en un nodo hoja o intermedio
- Los nodos intermedios tienen un punteor a un hijo el subárbol con raíz en el hijo almacena la dirección de la entidad
- La raíz conoce todas las entidades
- Cada nodo tiene un puntero al padre
Almacenamiento de información de una entidad con 2 direcciones en diferentes dominios hoja
Buscando una ubicación
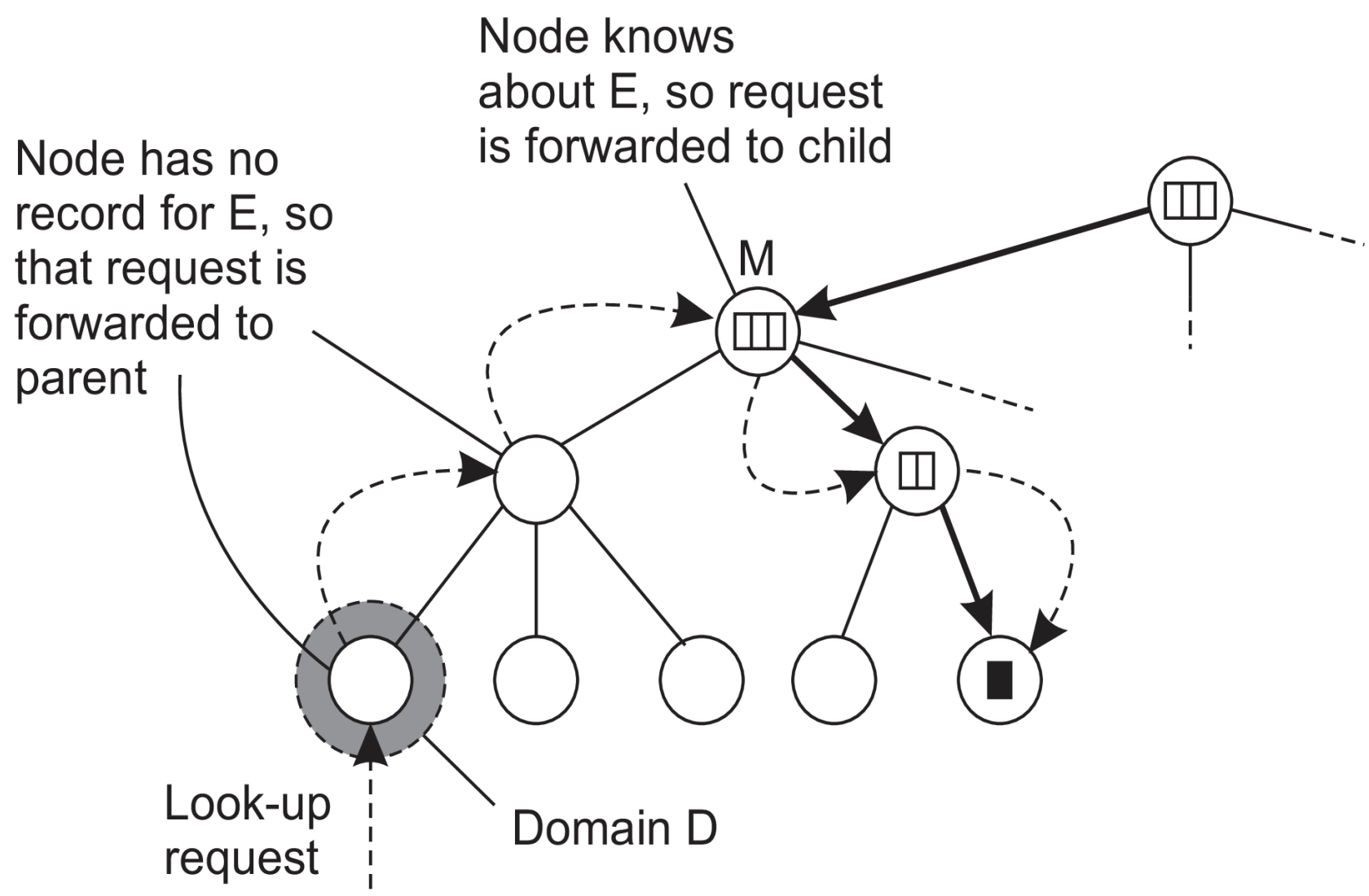
Principios básicos de HLS
- Iniciar la búsquead en el nodo hoja local
- Si el nodo conoce E sigue el puntero hacia abajo; de lo contrario, sube
- La búsqueda hacia arriba siempre frena en la raíz
Escalabilidad
- Es importante distinguir entre un diseño lógico y su implementación física
- Veamos como podemos llegar a una implementación altaente escalable de un servicio de ubicación jerárquico
- denota los dominios en el nivel
- Para cada nivel , el conjunto de hosts se divide en subconjuntos, y cada host ejecuta un servidor de ubicación que representa exactamente uno de los dominios de
Principio de distribución de servidores de ubicación lógicos
Seguridad en Flat Naming
- No hay información sobre cómo resolver un nombre a la entidad a la que hace referencia
- Por lo tanto, es necesario confiar completamente en el proceso de resolución de nombres para finalmente acceder a la entidad asociada
- ¿Qué pasa si el esquema de resolución de nombres del cual dependemos no es confiable?
Tenemos 2 opciones:
- Asegurar el proceso de resolución de nombres
- Es el más complicado porque estoy dependiendo de otro sistema
- Asegurar la asociación entre el identificador y la entidad
- Tengo una forma de autenticar a quien se está conectando
- Es un bodrio autenticar a nivel IP porque es un sistema de búsqueda.
- Existen ataques del tipo
ARP Floodingque consisten en inundar la red de solicitudes ARP.
- Existen ataques del tipo
Asegurar la asociación entre el identificador y la entidad
- Ocurre en un nombre autocertificado
- Como principio general, podemos calcular un identificador de una entidad simplemente usando una función hash
-
- Se le da un hash a cada uno, y si coincide el hash con el que se le dio la dirección, está diciendo la verdad
- Es parecido a la dirección de email, que es irreplicable
Structured Naming
Los nombres planos son buenos para las máquinas, pero generalmente no son muy convenientes para el uso humano.
Como alternativa, los sistemas de nombres generalmente admiten nombres estructurados.
- Se componen de nombres simples y legibles para humanos.
- Nombres de archivos y hosts en Internet siguen este enfoque.
Name Spaces
Se pueden representar como un grafo dirigido y etiquetado con dos tipos de nodos.
- Leaf node (Nodo hoja): Un nodo hoja representa una entidad nombrada y no tiene aristas salientes. Mantiene información representativa de la entidad (ej: dirección).
- Directory node (nodo directorio): tiene varias aristas salientes, cada una etiquetada con un nombre. Cada nodo en un grafo de nombres se considera como otra entidad en un sistema distribuido.
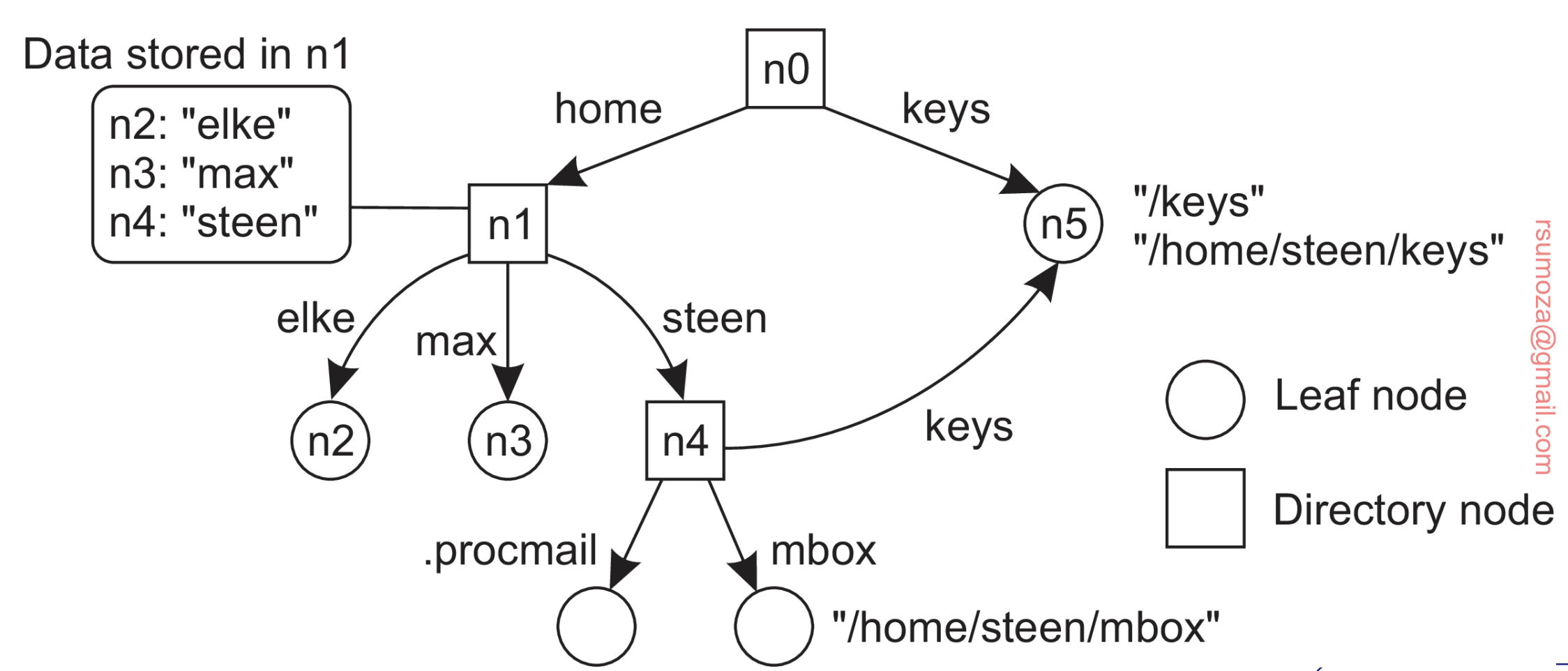
- Un nodo de directorio almacena una tabla en la que una arista de salida se representa como un par (identificador de nodo, etiqueta de arista).
- Dicha tabla se denomina tabla de directorio.
Name Resolution
- Los espacios de nombres ofrecen un mecanismo conveniente para almacenar y recuperar información sobre entidades a través de nombres.
- De manera más general, dado un nombre de ruta (route name), debería ser posible buscar cualquier información almacenada en el nodo al que hace referencia ese nombre.
- El proceso de buscar un nombre se llama resolución de nombres.
Se reduce a "En base a un nombre, dame una IP".
Mecanismo de clausura
- Sólo puede tener lugar si sabemos cómo y dónde empezar
- Saber cómo y dónde comenzar la resolución de nombres generalmente se conoce como mecanismo de clausura.
- Un mecanismo de clausura se ocupa de seleccionar el nodo inicial en un espacio de nombres, desde el cual debe comenzar la resolución de nombres.
Implementación de un espacio de nombres
- Un espacio de nombres forma el corazón de un servicio de nombres
- Es un servicio que permite a los uusarios y procesos agregar, eliminar y buscar nombres
- Un servicio de nombres se implementa mediante servidores de nombres
- En una LAN, se puede implementar un servicio de nombres con un sólo DNS
- En una WAN, se distribuye a través de varios DNS
- Acá los espacios de nombres usualmente se organizan jerárquicamente
- Asumir que el espacio de nombres tiene un solo nodo raíz
- Para implementar eficazmente dicho espacio de nombres, es conveniente dividirlo en capas lógicas
- Capa global: formada por nodos de nivel más alto
- Comprende el nodo raíz y otros nodos de directorio lógicamente cercano s ala raíz, es decir, sus hijos directos
- Los nodos representan organizaciones o grupos de ellas
- Se me caen estos y se me cae todo
- Capa administrativa: formada por nodos de directorio que, en conjunto, se gestionan dentro de una única organización. (Ej: la universidad y sus departamentos)
- Capa de dirección (Managerial layer): consta de nodos que suelen cambiar periódicamente. (Ej: nodos host, directorios y archivos)
- Capa global: formada por nodos de nivel más alto
DNS
- Usa el sistema de distribución por capas que mencionamos antes
- Es el sistema de resolución de nombres que usa actualmente internet
- DNS se usa para buscar direcciones IP de hosts y servidores de mail
- El namespace de DNS está organizado jerárquicamente como un árbol.
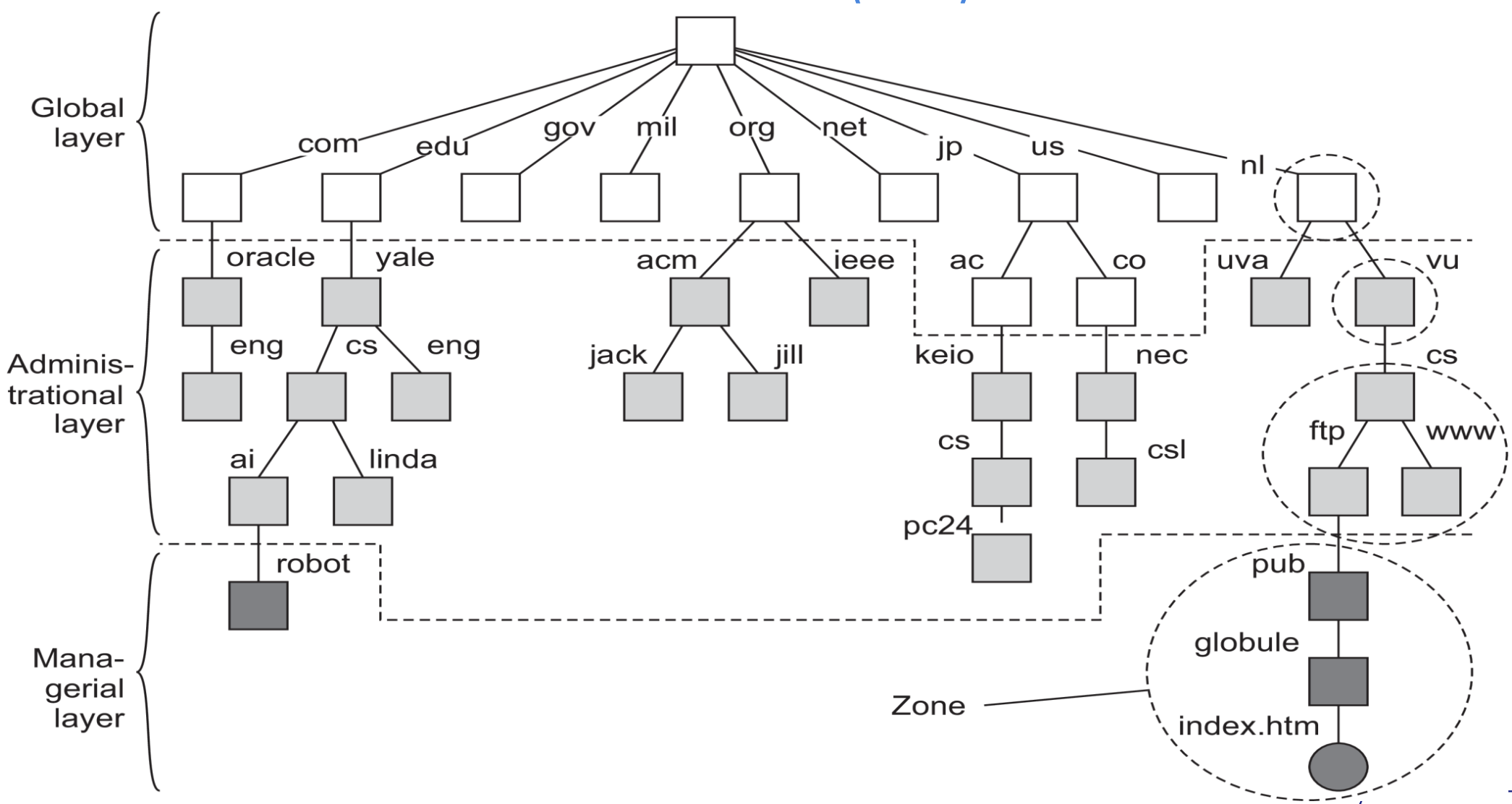
- Los subárboles son los dominios
- La ruta a su nodo raíz es el nombre de dominio
- La resolución de nombres se distribuye a través de varios servidores de dominio o "DNS servers"
- Para resolver un nombre, se comienza a leer desde adelante hacia atrás.
En esencia, el DNS namespace se puede dividir en una capa global y una administrativa:

Nota: la capa de dirección (managerial layer) no es gestionada por el sistema DNS, por no ser formalmente parte de este sistema.
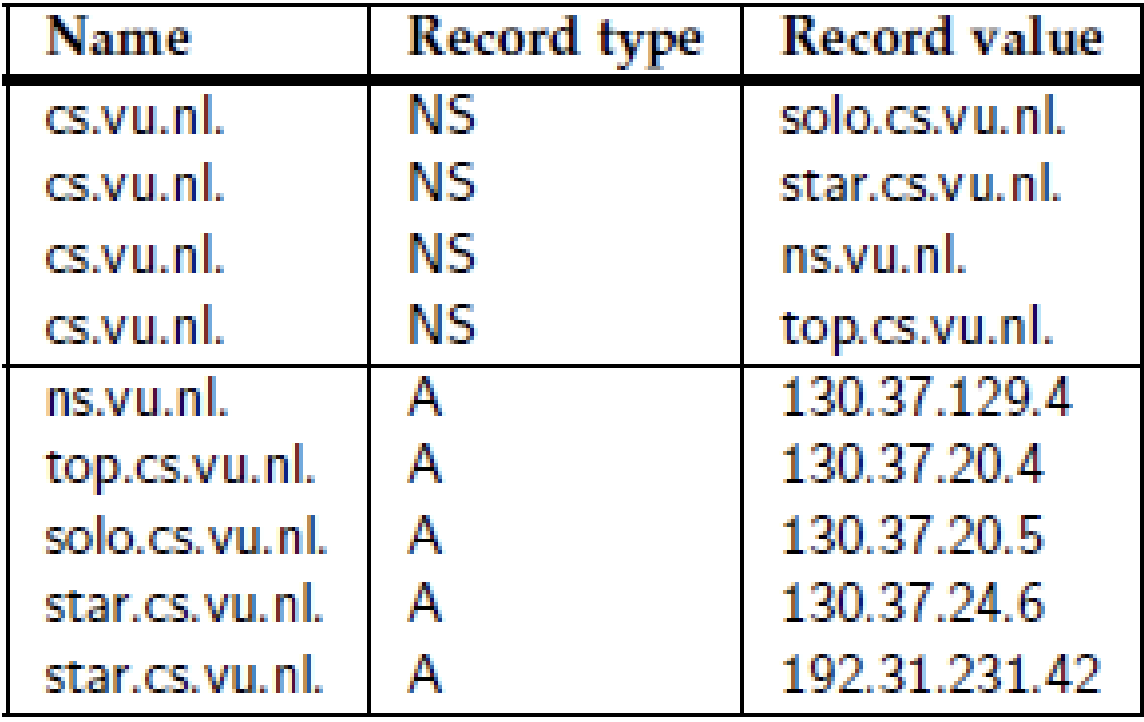
- Cada zona se implementa mediante un servidor de nombres, que prácticamente siempre se replica para garantizar la disponibilidad.
- Una base de datos DNS se implementa como una (pequeña) colección de archivos
- El más importante contiene todos los registros de recursos de todos los nodos en una zona particular.
- Este enfoque permite identificar los nodos de forma sencilla a través de su nombre de dominio
El contenido de un nodo está formado por una colección de registros de recursos.
Los más comunes para cada nodo son:

Al resolver un nombre para un nodo que se encuentra en el dominio cs.vu.nl, la resolución del nombre continuará en un punto determinado leyendo la base de datos DNS almacenada por el servidor de nombres para el dominio cs.vu.nl.
Attribute-based Naming
- Los nombres planos y estructurados generalmente proporcionan una forma única e independiente de la ubicación para referirse a las entidades.
- Los nombres estructurados se han diseñado en parte para proporcionar una forma amigable para los humanos de nombrar entidades.
- En particular, a medida que se dispone de más información, se vuelve importante buscar entidades de manera efectiva.
- Este enfoque requiere que el usuario pueda proporcionar simplemente una descripción de lo que está buscando.
- Entre las formas en que se puede proveer descripciones, una forma popular en sistemas distribuidos es describir una entidad en términos de pares (atributo, valor).
- Generalmente se conoce como “attribute-based naming” (nombramiento basado en atributos).
- En este enfoque, se asume que una entidad tiene una colección de atributos asociada.
- Cada atributo dice algo acerca de la entidad.
Servicios de directorio
- Los sistemas de nombres basados en atributos también se conocen como servicios de directorio.
- Con los servicios de directorio, las entidades tienen un conjunto de atributos asociados que se pueden utilizar para realizar búsquedas.
- Para casos simples, por ejemplo, en un sistema de correo electrónico, los mensajes se pueden etiquetar con atributos para el remitente, el destinatario, el asunto, etc.
- Para casos más complejos, un ejemplo son determinados filtros de email.
Desventajas
- En la mayoría de los casos, el diseño de atributos debe realizarse manualmente.
- En la práctica, establecer valores de manera consistente por parte de un grupo diverso de personas es un problema en sí mismo. Por ejemplo, búsquedas en bases de datos de música y vídeo en Internet.
- Para aliviar algunos de estos problemas, se han llevado a cabo investigaciones para unificar las formas en que se pueden describir los recursos
RDF
- Un desarrollo relevante es Resource Description Framework (RDF).
- Fundamental para el modelo RDF es que los recursos se describen como tripletes que constan de un sujeto, un predicado y un objeto.
- Por ejemplo, (Persona, nombre, Alicia) describe un recurso denominado Persona cuyo nombre es Alicia.
- En RDF, cada sujeto, predicado u objeto puede ser un recurso en sí mismo
- Esto significa que Alice puede implementarse como una referencia a un archivo que puede recuperarse posteriormente.
- En el caso de un predicado, dicho recurso podría contener una descripción textual de ese predicado.
- Los recursos asociados a sujetos y objetos pueden ser cualquier cosa. Las referencias en RDF son esencialmente URLs.
Consistencia y Replicación
Conceptos básicos
Los datos se replican para mejorar la confiabilidad o el rendimiento de un sistema.
El problema principal es que las réplicas sean consistentes entre si.
- En estos modelos de consistencia, se supone que varios procesos acceden de manera concurrente a los datos compartidos
- Esto implica restricciones en cuanto a la escalabilidad del sistema.
- La consistencia en estas situaciones se puede formular en cuant a lo que pueden esperar los procesos al leer y actualizar los datos compartidos.
- Los procesos conocen que otros procesos tienen acceso a los datos compartidos
Razones para replicar
- Los datos se replican para aumentar la confiabilidad del sistema
- Se puede replicar un sistema de archivos; cuando el principal se cae, el sistema puede seguir funcionando
- La otra razón es por mejorar la performance del sistema
- Un S.D puede necesitar escalar en términos del tamaño o del área geográfica que cubre
- Ej de Tamaño: cada vez más procesos requieren acceder a los datos compartidos
- En ese caso, puedo replicar para distribuir la carga del "sistema central"
Desventajas
- Tener múltiples copias puede generar problemas de consistencia
- Cada vez que se modifica una copia, esa copia se vuelve distinta del resto
- Es necesario realizar cambios en todas las copias para garantizar la consistencia
- Exactamente cuándo y cómo deben realizarse esos cambios determina el costo de replicación
- Cuanto más performante tiene que ser el proceso de replicación, mayor es el costo
Replicación como técnica de escalabilidad
-
Replicación y cacheo se usan ampliamente como técnicas de escalabilidad por cuestiones del aumento de rendimiento que implican
- Ej: se puede configurar el TTL (Time To Live) de la copia en caché a partir de los headers de
HTTP
- Ej: se puede configurar el TTL (Time To Live) de la copia en caché a partir de los headers de
-
Las restricciones de escalabilidad generalmetne aparecen en forma de problemas de rendimiento
-
Colocar copias de datos cerca de los procesos que los usan puede mejorar el rendimiento mediante la reducción del tiempo de acceso. Y entonces se resuelven problemas de escalabilidad.
-
Para mantener la copia actualizada, voy a requerir un mayor ancho de banda de la red. Claramente incurre un costo
-
Mantener varias copias consistentes puede estar sujeto a problemas de escalabilidad serios
-
Una colección de copias es consistente cuando varias copias terminan siendo las mismas
-
Una operación de lectura realizada a cualquier copia siempre devolverá el mismo resultado
-
Cuando se realiza una actualización, se tiene que propagar a todas las copias previo a realizar una operación posterior
-
Esto debe ser independientemente de en qué copia se inicie o realice la operación
-
Este tipo de consistencia se denomina (informalmente) como consistencia hermética. En el caso de replicación sincrónica.
Triggers de Bases de Datos: son operaciones que se ejecutan cuando sucede un evento en particular. Ej: si escriben a la tabla
users, hago una copia de todas las tablas previo a modificarla.
- La idea principal es que una actualización se realiza en toda slas copias como una sola operación atómica, o transacción.
- Implementar atomicidad involucrando una gran cantidad de réplicas, muy dispersas en una red de gran escala, es difícil cuando se necesita velocidad de operaciones.
- Las dificultades surgen cuando necesitamos sincronizar todas las réplicas.
Modelos de consistencia centrados en los datos
Conceptos
- Almacén de datos (data store): el objeto que conforma los datos, que pueden estar compartidos.
- El almacén de datos puede estar físicamente distribuido a través de múltiples máquinas.
- Se asume que todo proceso que puede acceder a datos del almacén tiene una copia local (o en las cercanías)
- Las operaciones de escritura se propagan hacia las otras copias
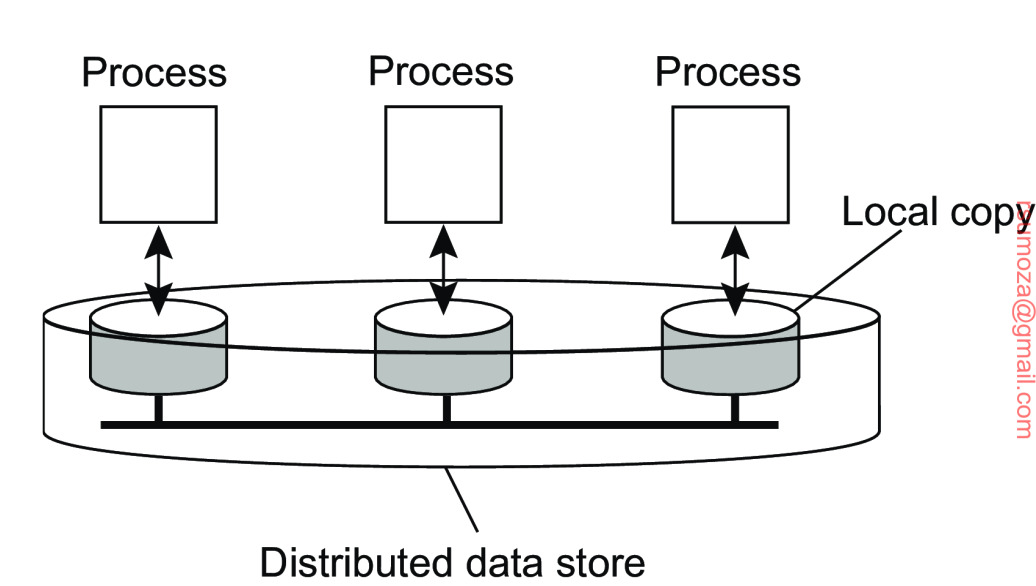
- Un modelo de consistencia es esencialmente un contrato entre los procesos y el almacén de datos (data store)
- Si los procesos aceptan obedecer ciertas reglas, el almacén promete funcionar correctamente
- Se puede llamar también
nivel de consistencia, porque el contrato determina el nivel de consistencia
- Se puede llamar también
- Sin un reloj global, es difícil definir precisamente cuál es la última operación de escritura
- Como alternativa, necesitamos proporconar otras definiciones, lo que nos lleva a una gama entera de modelos de consistencia
- cada modelo va a restringir los valores que puede devolver una operación de lectura sobre un elemento de datos
- La facilidad de uso es proporcional a los niveles de restricción de los modelos, pero es inversamente proporcional al rendimiento.
- Entre más restrictivo, más fácil de usar pero peor anda. Y viceversa.
Consistencia continua
- Hasta el momento no hay una mejor solución para replicar los datos
- Lo que podemos hacer cuando tenemos una distribución muy grande de replicacion es dilatar la consistencia.
- Refiere a "relajar" la consistencia, no hacer que sea instantáneo.
- Infiere una
consistencia eventual. Puede llevarnos a soluciones eficientes.
- Tampoco hay reglas generales para esta dilatación, la tolerancia depende bastante de las aplicaciones.
- Si replico mucho, divido el riesgo de que se me caiga el sistema.
Hay distintas formas en las que las aplicaciones especifican las incosistencias que pueden tolerar:
- Desviación en valores numéricos entre réplicas
- Es muy fino (poco usadi)
- Desviación en el deterioro entre réplicas
- Desviación con respecto al ordenamiento de operaciones de actualización
Estos se definen como rangos de consistencia continua.
Desviaciones
- Desviación en valores numéricos entre réplicas
- Puede ser en rangos de valores que representan los datos.
- Ej: updates con tolerancia de precisión los datos de la bolsa de valores
- Cantidad de updates a una réplica no vista por otras réplicas.
- Ej: caché web
- Puede ser en rangos de valores que representan los datos.
- Desviación en el deterioro entre réplicas
- De acuerdo a la última vez que se "updateó" una réplica
- Se toleran datos viejos a menos que sean "muy viejos".
- Ej: informes sobre el clima
- En realidad el término viejo refiere a cuanto tiempo el sistema determina como válido el dato.
- Desviación con respecto al ordenamiento de operaciones de actualización
- El orden de updates difiere en distintas réplicas (siempre que las diferencias sean limitadas)
- Se aplican tentativamente a una copia local, en espera de un acuerdo global de todas las réplicas
- Algunos updates necesitarán repetirse y tendrán que aplicarse en un orden diferente antes de volverse permanentes
El modelo de consistencia para aplicar los cambios en DNS es un modelo relajado.
Conit
- Para definir inconsistencias, se presentó una unidad de consistencia, abreviada como
conit - Una conit especifica la unidad con la que se va a medir la consistencia
- En el ejemplo de acciones, una conit podría definirse como un registro que representa una sola acción
El tamaño del conit se relaciona directamente con el nivel de granularidad que quiero. Ejemplos:
- Puedo replicar de a bytes entre 2 discos espejados.
Granularidad fina.- Me rijo por los bits
- Puedo replicar a nivel de transacciones en una base de datos.
Granularidad gruesa.- Puede ser de 10 MB, por ejemplo.
Puedo hacer sincronizaciones mucho más grandes con conits chiquitos. En el caso del backup de una BD, puedo usar la tabla como conit y replicar toda la base de datos replicando las tablas.
O puedo tomar la base de datos como conit y replicarla entera
Consistencia secuencial
-
Una clase importante de modelos de consistencia centrada en datos provienn del campo de programación concurrente
-
en la computación paralela y distribuida carios procesos necesitara2n compartir recursos y acceder de manera simultanea a ellos
-
Da lugar a 2 modelos:
- Consistencia secuencial esta es más exigente que la causal
- Consistencia causal
-
En principio, los modelos superan a aquellos de consistencia continua
-
Cuando es necesario confirmar updates en réplicas, éstas tendrán que ...
- son operaciones de escritura
- son operaciones de lectura
- es el elemento/objeto puntual
- es el la cantidad de eventos/operaciones de la operación particular
- Puedo tener , que quiere decir que escribí 2 veces y leí una sola vez.
- representan los valores
El eje horizontal representa el tiempo:
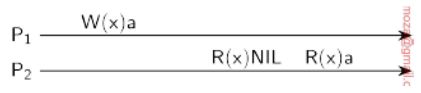
- Cuando el proceso 2 lee
NILquiere decir que todavía no se actualizó el dato - Entre y hubo alguna actualización que hizo que efectivamente se leyera el dato que escribió el proceso 1.
- Recién en tiempo
t3se alcanzó la consistencia
La consistencia secuencial la define Lamport en el contexto de memoria compartida para sistemas multiprocesador
Un data store es secuencialmente consistente en tanto y en cuanto:
"El resultado de cualquier ejecución es el mismo que si las operaciones (de lectura y escritura) de todos los procesos efectuados sobre el almacén de datos se ejecutaran en algu2n orden secuencial y las operaciones de cada proceso individual aparecieran en esa secuencia en el orden especificado por su programa."
Implica consistencia eventual, simplemente se fija que se respete el orden.
El modelo este define un dato que es la secuencia que es numérica, incremental y ascendente para que la replica pueda ordenar. Tiene que haber un orden necesariamente para poder aplicar este modelo.
A este modelo solo le importa que una secuencia (con transacciones ) se replique con ese orden. Si se produce otra secuencia (con transacciones ) al mismo tiempo, al modelo no le importa que y se ordenen de cualquier manera, si no que ocurran en su orden "interno" (que sus transacciones se ejecuten en el orden indicado)
- Cuando los procesos se ejecutan concurrentemente en (quizá) diferentes máquinas, cualquier interpolación válida de operaciones de lectura y escritura es un comportamiento aceptable
- Pero todos los procesos ven la misma interpolación de operaciones
- No hay referencias temporales, respecto de la operación de escritura "más reciente".

- El modelo B es inconsistente porque la secuencia de los eventos es necesariamente inconsistente.
- El orden de los eventos es inconsistente necesariamente. Se escribe A, se escribe B, pero el orden de lectura no se condice de ninguna manera.
| Proceso 1 | Proceso 2 | Proceso 3 |
|---|---|---|
| x 1; | y 1; | z 1; |
| impresión (y, z); | impresión (x, z); | impresión (x, y); |
- Terminas teniendo 720 () secuencias de ejecución posibles
- No todas las posibilidades son secuencialmente consistentes. A efectos de este ejemplo, solo hay 90 combinaciones válidas.

- En todos los resultados menos en uno (el de
Execution 3) los prints son consistentes con la firma- Aún así sigue siendo secuencialmente consistente
- La firma es la concatenación de todas las salidas. Es el orden en el que se deberían ejecutar los procesos.
- Es una forma de validar la consistencia secuencial.
- En el libro se asegura que no haya ninguna firma que diga
000000.
- En el libro se asegura que no haya ninguna firma que diga
- A efectos de este ejemplo, se asume que se ejecuta
- Es una forma de validar la consistencia secuencial.
- Los 90 diferentes ordenamientos válidos producen una variedad de diferentes resultados de programa
Consistencia causal
Un evento es consecuencia de otro. No me interesan ciertas secuencias por su falta de relación.
- Representa una debilidad de la consistencia secuencial
- Diferencia entre eventos que potencialmente están relacionados por la causalidad y los que no lo están
- Si el evento
bes causado o influenciado por un evento previoa, la causalidad requiere que todos los demás eventos vean primero al eventoay después alb. - Si un evento de lectura depende d eotro evento de escritura, ya sea porque accedan a la misma pieza de datos, entonces están causalmente relacionados.
- Si 2 procesos escriben espontánea y simultáneamente 2 diferentes elementos de datos, no están causalmente relacionados. Son operaciones concurrentes.
Para que un data store se considere causalmente consistente, es necesario que respete la siguiente condición: "Escrituras que potencialmente están relacionadas por la causalidad, deben ser vistas por todos los procesos en el mismo orden. Las escrituras concurrentes pueden verse en un orden diferente en diferentes máquinas."
 Si los eventos son concurrentes, esta secuencia está permitida con un almacén causalmente consistente, pero no con un almacén secuencialmente consistente.
Si los eventos son concurrentes, esta secuencia está permitida con un almacén causalmente consistente, pero no con un almacén secuencialmente consistente.
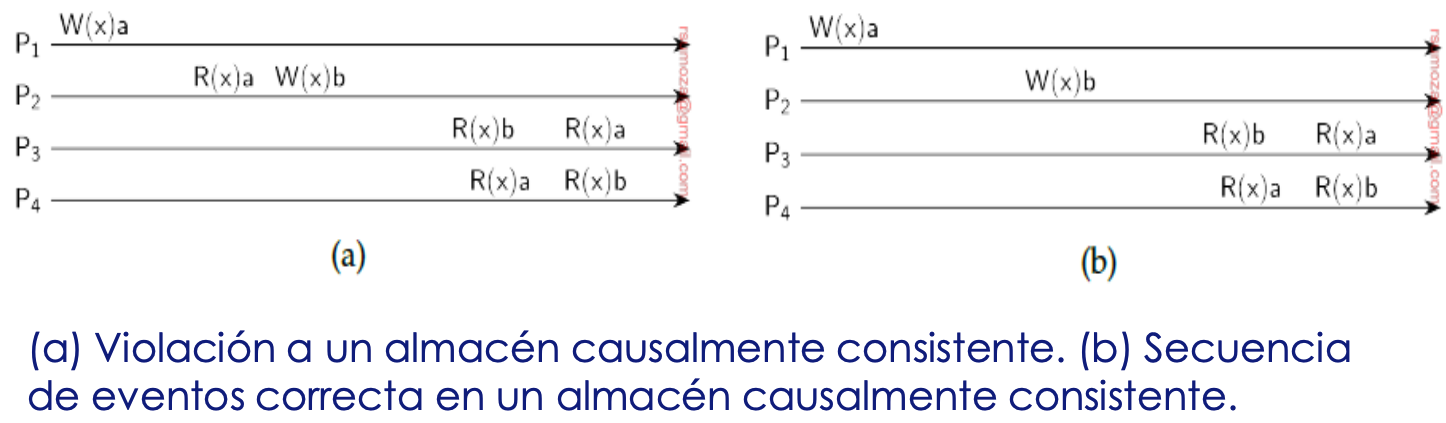
- a) es el data store causalmente inconsistente
- b) es el causalmente consistente
Implementar la consistencia causal requiere dar seguimiento a cuáles procesos han visto cuáles escrituras
Esto significa que debe construirse y mantenerse una gráfica de la dependencia de cuál operación depende de qué otras operaciones. Se termina construyendo un árbol de secuencia de lecturas y escrituras
Operaciones de agrupamiento
- La consistencia secuencial y la causal están definidas a nivel de operaciones de escritura y lectura
- Estos modelos se desarrollaron inicialmente para sistemas multiprocesador de memoria compartida
- La concurrencia entre programas que comparten datos generalmente se mantiene bajo control a través de mecanismos de sincronización para exclusión mutua y transacciones.
- A nivel de programa, las operaciones de escritura y lectura se colocan entre "corchetes" (en este caso son operaciones) mediante el par de operaciones
ENTER_CSyLEAVE_CS. CS= Critical Section; sección crítica- Los datos manejados mediante una serie de operaciones de lectura y escritura están protegidos contra accesos concurrentes.
- Lo que está delimitado por
ENTER_CSyLEAVE_CSconvierten la serie de operaciones de lectura y escritura en una unidad ejecutada atómicamente - De esta manera aumentan el nivel de granularidad
- Los datos manejados mediante una serie de operaciones de lectura y escritura están protegidos contra accesos concurrentes. “Unidad Atómica”
- Se usan variables de sincronización compartidas.
- Cuando un proceso entra en su sección crítica, debe adquirir las variables importantes de sincronización
- De igual manera, debe liberar esas variables al abandonarla
- Cada variable de sincronización tiene un propietario en un momento dado, siendo este el último proceso que la adquirió

- Una secuencia de eventos válida para la consistencia de entrada.
Modelos de consistencia centrados en el cliente
Conceptos
- En la consistencia centrada en datos, se proporciona una vista consistente a lo largo del sistema de un almacén de datos.
- En la consistencia centrada en el cliente se verá una clase especial de almacenes de datos
- Se caracterizan por:
- La falta de updates simultáneos
- O bien, la facilidad para resolver updates simultáneos
Se intenta que la consistencia sea orientada a cada cliente, no se compara entre clientes para determinar si el sistema es consistente.
Si uno ve una cosa y otro ve otra, mientras que sea consistente con lo que se le quiere mostrar a cada uno ta todo bien ![]() .
.
- La mayoria de las operaciones involucran la lectura de datos.
- Estos data stores ofrecen un modelo de consistencia muy débil, llamada consistencia momentánea.
- Se mantiene una consistencia local
- Al introducir modelos de consistencia centrada en el cliente, es posible ocultar muchas inconsistencias de una manera relativamente barata
Consistencia momentánea
- ¿Hasta qué punto los procesos operan de manera concurrente?
- ¿Hasta qué punto necesito garantizar la consistencia?
Para ambos casos puede variar... Ej: en muchos sistemas de BD, la mayoría de los procesos difîcilmente realizan alguna vez operaciones de actualización, sino que mayoritariamente leen datos. Entonces:
Todo tiene que ver con el diseño de la arquitectura de datos.
- Las BD replicadas y distribuidas (de gran escala) suelen tolerar un grado de inconsistencia relativamente alto
- Si no ocurren actualizaciones durante mucho tiempo, todas las réplicas gradualmente se volverán inconsistentes
- Esta forma de consistencia se conoce como consistencia momentánea.
- En ausencia de updates, todas las réplicas convergen en copias idénticas unas de otras
- Solo requieren la garantía de que los updates se propaguen en todas las réplicas
- Los conflictos de escritura-escritura con frecuencia son fáciles de resolver cuando se asume que sólo un pequeño grupo de procesos puede realizar actualizaciones.
- Por ende, la implementación de este tipo de consistencia es barata
- Los data stores funcionan bien siempre y cuando los clientes siempre accedan a la misma réplica
- Los problemas surgen cuando en un período corto se accede a réplicas diferentes.
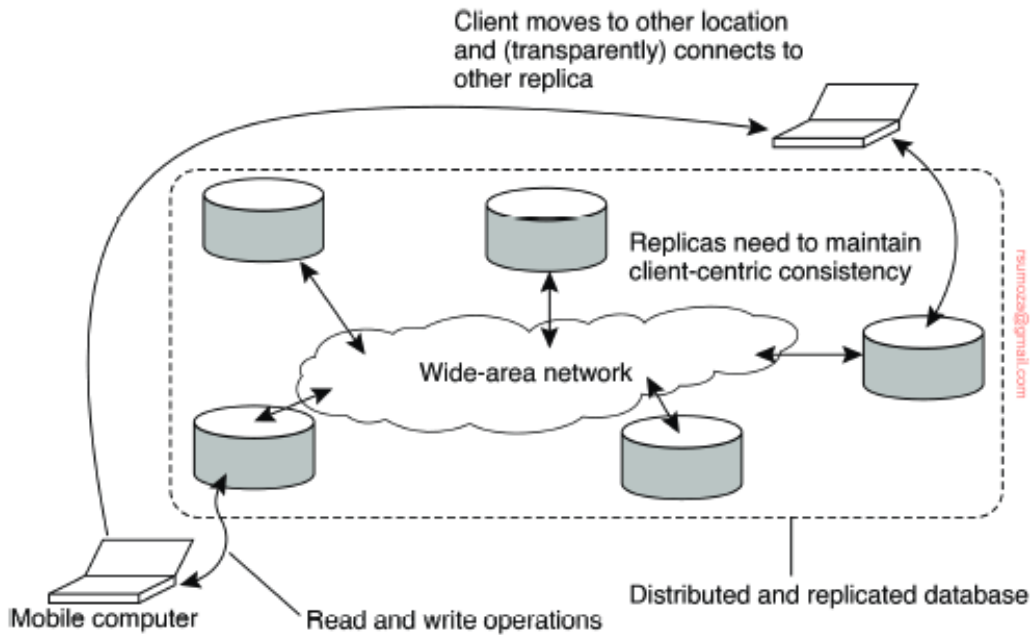
- Los problemas subyacentes a este tipo de consistencia pueden mitigarse introduciendo la consistencia centrada en el cliente
- En esencia, esta última proporciona garantías para un solo cliente, para el almacén de datos de ese cliente en particular
- No se proporciona garantía alguna con respecto a accesos concurrentes de distintos clientes
Lecturas monotónicas
- El primer modelo de consistencia centrada en el cliente es el de lecturas monotónicas.
- Un almacén de datos proporciona consistencia de lectura monotónica si se cumple la siguiente condición:
“Si un proceso lee el valor de un elemento de datos x, cualquier operación de lectura sucesiva sobre x que haga ese proceso devolverá siempre el mismo valor o un valor más reciente.”
O sea, si un proceso ha visto un valor de al tiempo , nunca verá una versión más vieja de en un tiempo posterior ().
Escrituras monotónicas
- En muchas situaciones, es importante que las operaciones de escritura se propaguen en el orden correcto hacia todas las copias del almacén de datos, esto es escritura monotónica.
- Un almacén de datos proporciona consistencia de escritura monotónica si se cumple la siguiente condición:
“Una operación de escritura hecha por un proceso sobre un elemento x se completa antes que cualquier otra operación sucesiva de escritura sobre x realizada por el mismo proceso.”
O sea, una operación de escritura sobre una copia del elemento se realiza sólo si esa copia se ha actualizado mediante cualquier operación de escritura previa, la cual pudo haber ocurrido en otras copias de
Blockchain
Siempre que se desarrolle en blockchain se desarrollan 2 apps:
- Un front que se conecta con el backend usando una librería llamada
web3 - Un backend que escribe en la cadena de blockchain
El backend queda guardado en la blockchain puntual.
La blockchain se usa para la tenencia de activos, que pueden ser criptoactivos o cualquier cosa que yo pueda tokenizar como los NFT.
Ethereum
Se programa en Solidity.
Introduce el concepto de Smart Contract, el cual es un programa que corre dentro de la blockchain, sobre el que se define una serie de condiciones,
Puede ser invocado por prácticamente cualquier billetera que consuma este programa, y está distribuido por toda la blockchain.
Tolerancia a fallos
Se espera que el sistema tenga fallas: es inevitable. Lo que se busca es que sea tolerable a las mismas.
Confiabilidad y sus requerimientos
Dependable Systems
High availability + Reliability = Dependability
Tolerancia a fallas:
- Tolerar fallas parciales
- Tener la capacidad de auto recuperarse
(Ver definiciones de clases anteriores de distintos conceptos relacionados a disponibilidad)
El concepto de "Dependability", yendo al ejemplo de un auto, se pone en juego en caso de que, si bien el motor puede andar bien y tener buena potencia, la batería quizá falle todo el tiempo.
Métricas
- Mean Time To Failure (MTTF): Tiempo medio hasta el fallo
- EJ: en un datacenter, se mide cuál es el tiempo promedio hasta la falla de un disco, para poder reemplazarlo antes.
- Mean Time To Repair (MTTR): Tiempo medio para reparar.
- Mean Time Between Failures (MTBF): MTTF + MTTR
- Disponibilidad (A): MTTF / (MTTF + MTTR)
Métricas - ejercicio
Availability en 1 mes = 99,95% uptime
¿Cuántos minutos en el mes puede estar caído el sistema? Es decir, que no responde o responde con 500s (Internal Server Error).
¿Cuántos minutos hay en 30 días? 43.200 minutos
Respuesta:
- Tiempo disponible = 43.200 * 99.95% = 43.178,4 minutos
- Tiempo indisponible = 43.200 - 43.178,4 = 43.200 * (1 - 99.95%)
- Tiempo indisponible = 21,6 minutos
¿Es mucho o poco tiempo? Depende. Si es algo crítico, sí (p. ej. el funcionamiento de respiradores en un hospital). En caso de que no, quizá no sea tan grave.
Es muy común que empresas serias muestren su uptime en una página web (p. ej. Mercado Libre).
Teorema de CAP
Un sistema distribuido solo puede garantizar simultáneamente dos de las siguientes tres propiedades:
- C - Consistencia (Consistency): Todos los nodos del sistema ven la misma versión de los datos al mismo tiempo. Es como si hubiera una única copia actualizada de los datos
- A - Disponibilidad (Availability): Todas las solicitudes reciben una respuesta (no un error), aunque esa respuesta no siempre contenga la versión más reciente de los datos
- P - Tolerancia a Particiones (Partition Tolerance): El sistema continúa funcionando incluso si algunos nodos no pueden comunicarse entre sí (una "partición" de la red).
Consistencia, disponibilidad y particionamiento
- Sistemas CP: Priorizan la Consistencia. Si hay una partición, el sistema puede volverse no disponible para garantiszar que las respuestas sean correctas.
- EJ: sistema bancario, donde es preferible tardar en mostrarle al usuario su balance correcto, antes de mostrarle uno desactualizado y que haga una transacción incorrecta.
- Sistemas AP: Priorizan la Disponibilidad. Si hay una partición, el sistema puede devolver datos potencialmente inconsistentes para seguir respondiendo.
- EJ: un Marketplace como Mercado Libre, donde yo quizá hago una compra de algo que en realidad no tiene stock. Sin embargo, después puede arreglarse con una compensación (EJ: un vale de compra por )
Fallas
¿Qué es una falla?
- Un sistema falla (failure) cuando no cumple sus promesas o especificaciones.
- Es lo más abstracto, porque puede no ser causada por un error del sistema en sí. La falla es un comportamiento que yo no esperaba del sistema.
- De la falla no te salvás (?)
- Un error es una parte del estado del sistema que puede llevar a un fallo (p. ej. un bug de programación)
- Un defecto (fault) es la causa de un error (p. ej. un programador que introduce un bug, un disco rallado, etc.)
La cadena de sucesos es: Defecto -> Error -> Falla.
Es imporatnte distinguirlos porque es la forma en la cual uno puede hacerse tolerante a cada uno de estos 3 problemas.
Categorización de fallas
- Fallas por caída (Crash Failures): se detiene y no responde
- Fallos de Omisión (Omission failures)
- Fallos de envío (Send-omission): falla al enviar un mensaje que debía enviar
- Fallos de recepción (Receive-omission): falla al recibir mensajes que llegan
- Cuando tengo una sobrecarga a nivel de OS (porque tengo demasiados threads laburando), se me puede producir un fallo de este tipo, ya que no tengo capacidad suficiente para recibir.
- Fallos de tiempo (Timing failures): timeout. Se tarda mucho en responder un mensaje.
- La diferencia entre omisión y timing es que en el caso del primero falla instantáneamente.
- Fallos de respuesta: respuesta es incorrecta
- Fallos de valor (Value Failure): La respuesta contiene un valor incorrecto. Yo quería un determinado valor, y me responden cualquier cosa
- Fallos de transición de estado: se desvía el correcto flujo de control
- Fallos arbitrarios: puede producir respuestas incorrectas en momentos arbitrarios (ej: respuestas inconsistentes). Este tipo de error es el peor, porque como los errores no siguen un patrón, son difíciles de detectar. Siendo rigurosos, no existen los fallos arbitrarios, porque siempre hay una causa. Lo que realmente pasa es que yo como desarrollador desconozco la causa.
- Falla por omisión: Un componente no realiza una acción que debería hacer
- Falla por comisión: Un componente realiza una acción que no debería haber realizado.
Fun fact 🤓: Los fallos arbitrarios también se llaman bizantinos
Detección de fallas
De suma importancia para la tolerancia a fallos.
- Dificultad en sistemas asíncronos: en un sistema puramente asíncrono, es imposible distinguir si un proceso se ha caído o si solo está respondiendo muy lento.
- Algo que se suele hacer es medir el "heartbeat": el load balancer envía requests cada cierto tiempo para verificar si el servicio está vivo. Cuando no respondió ante X intentos, se considera muerto.
- Mecanismos comunes: la práctica se basa en mecanismos de tiempo de espera (timeouts) para sospechar que un proceso ha fallado.
Forma de detección
En los casos siguientes, la severidad es ascendente.
Imaginemos que un proceso P intenta detectar si un proceso Q ha fallado:
- Fallas fail-stop: pueden detectarse de forma confiable, asumiendo correcta comunicación y un retraso máximo en las respuestas de
Q. - Fallas fail-noisy:
Psolo eventualmente llega a la conclusión correcta de queQha fallado. Puede haber un tiempo desconocido durante el cual las detecciones dePsobre el comportamiento deQno son fiables - Fallas fail-silent: Se asume que los enlaces de comunicación no tienen fallas, pero el proceso
Pno puede distinguir entre fallas por caída y fallas por omisión (no sabe si está caído o si por algún motivo no está respondiendo) - Fallas fail-safe: fallas arbitrarias de
Q, pero son benignas: no pueden causar ningún daño. - Fallas fail-arbitrary: las fallas de
Qpueden ser inobservables además de ser perjudiciales para el comportamiento correcto de otros procesos.
Masking (manejo de fallos) mediante redundancia
- Redundancia de información: Se añade información redundante (p. ej. códigos de detección o corrección de errores, como en TCP)
- Redundancia de tiempo: Se realiza una acción varias veces (p. ej. retransmisión de mensajes).
- Redundancia física: Se usan componentes duplicados (p. ej. replicación de procesos o datos).
Redundancia
Redundancia no es lo mismo que replicación:
- Redundante: se usa al mismo tiempo que algo
- Replicado: es una copia de algo
¿Qué pasa cuando le pido lo mismo a X sistemas distintos? Espero que respondan lo mismo. Ese es el principal problema de la redundancia, porque quiero ser consistente con mis respuestas.
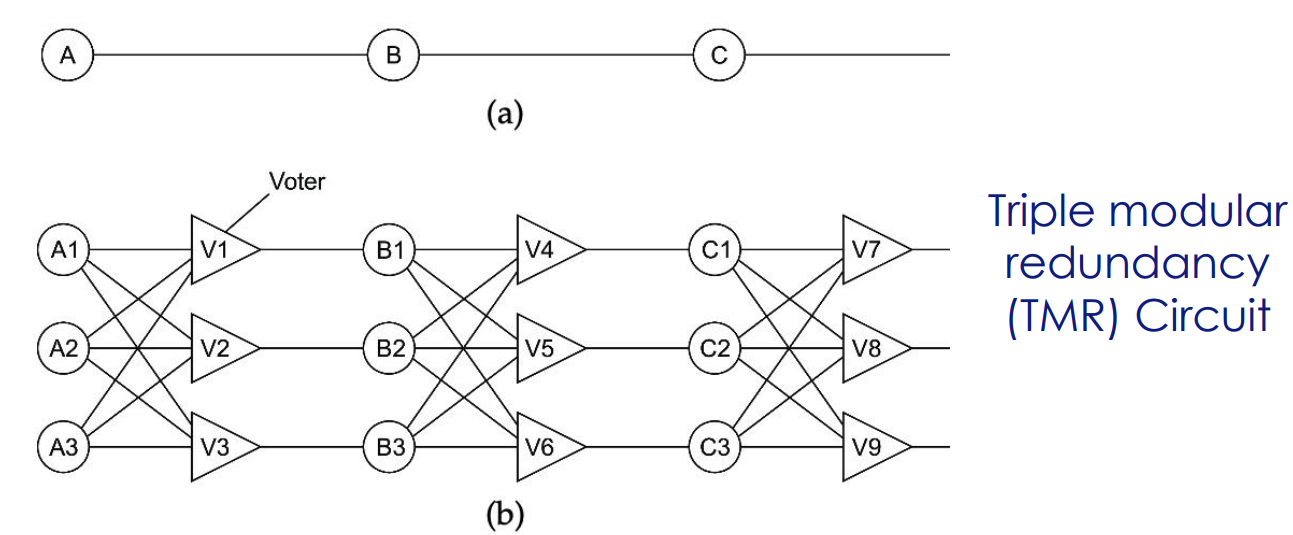
- Siguiendo el caso de la imagen, incluso el votador se replica, porque es capaz de caerse también.
Evidentemente la redundancia tiene un costo
Y en Software?
- Server redundancy: Múltiples instancias
- Data Redundancy: Múltiples copias de la DB
- Network Redundancy: Múltiples redes por si una se cae
- Otros...
Ejemplo: un servidor por país
- Puedo tener más disponibilidad porque distribuye la carga
- Pero no tengo redundancia. Se cae el servidor de un país y ese país queda sin servicio
Recuperación ante fallos
Tiene más relación con una pérdida de datos que con una caída de la aplicación. Consiste en cómo se vuelve a un estado razonable después de haber tenido una pérdida de datos.
Recuperación del sistema
Objetivo:
- Analizar las dependencias entre servicios para entender cómo reaccionar ante un evento de recuperación de uno de los miembros.
- Dependencia de datos entre aplicaciones
El problema principal de la recuperación ante fallas es la consistencia entre los nodos del sistema. Por ejemplo, si un servicio de ventas depende de ciertos datos consistentes que tiene un servicio de historial, al caerse este último, el primer servicio no puede realizar operaciones consistentes.
Recuperación
- La recuperación se refiere al proceso de devolver un componente fallido (o todo el sistema) a un estado correcto luego de que un fallo haya ocurrido, y haya sido detectado/reparado
- Lo que se tiene como objetivo es minimizar el impacto y restaurar el servicio
- Tenemos distintos tipos de recuperación:
- Hacia atrás (backwards): volver a un estado anterior correcto
- Hacia adelante (forward): es necesario conocer los errores que van a ocurrir con antelación
- Es un quilombo de implementar porque tampoco podés pretender "atajar todos los penales"

- Es un quilombo de implementar porque tampoco podés pretender "atajar todos los penales"
Backwards Recovery - Checkpoint
- El sistema debe guardar su estado periódicamente: checkpoint
- En caso de fallo, un proceso puede retroceder a su último checkpoint válido en lugar de reiniciar desde cero
- La recuperación requiere construir un estado global consistente a partir de los estados locales guardados por cada proceso
- Tenemos 2 maneras principales de tomar checkpoints:
- De manera coordinada: usando un algoritmo como 2PC. Es más simple que tenga un estado global consistente
- De manera independiente: el desafío justamente yace en lograr un estado global consistente
- La línea de recuperación (recovery line) es la colección más reciente de puntos de control que forman un estado global consistente.
- Es recomendable volver el estado a una línea de recuperación.
- Es más simple el checkpoint coordinado y por lo tanto más usado.
Desafíos del checkpoint independiente
- Cada proceso graba su estado local ocasionalmente y de manera no coordinada.
- Para descubrir una línea de recuperación, cada proceso debe retroceder a su estado guardado más reciente.
- Si estos estados locales conjuntamente no forman un estado global consistente requiere que otro proceso retroceda a un estado anterior.
- Esto puede desencadenar un efecto dominó.
Message Logging
El checkpointing tradicional tiene un par de limitiaciones:
- Costo Elevado: La toma de checkpoints es una operación costosa y puede penalizar severamente el rendimiento.
- No Determinismo: Si solo se usa checkpointing, el comportamiento después de la recuperación puede ser diferente al original debido a que pueden recibirse los mensajes en orden o tiempos diferentes de los que se había recibido antes de la falla
Para "parchear" esas fallas que tiene el checkpoint, surge el Message Logging.
¿Qué es?
- Idea clave: Si la transmisión de mensajes puede ser "reproducida" (replayed), se puede restaurar un estado consistente global.
- Mecanismo:
- Se parte de un estado previamente checkpointed
- Todos los mensajes enviados desde ese checkpoint se retransmiten y manejan o ejecutan de nuevo
- Beneficios:
- Permite restaurar un estado más allá del checkpoint más reciente sin el alto costo de nuevos checkpoints
- Facilita una reproducción exacta de los eventos
- Mayor eficiencia en la práctica, al requerir menos checkpoints.
Resiliencia de Procesos
- Foco: ¿Cómo hacer que un proceso o un conjunto de procesos sea tolerante a fallos?
- Objetivo: hacer que un grupo de procesos se comporte como un único proceso más robusto.
- Metodología: se logra mediante la replicación de procesos
- Desafío: mantener la coherencia y coordinación entre los procesos replicados para que actúen como una sola entidad fiable.
Organización de grupos
Dos opciones:
- Todos los procesos son iguales, decisiones colectivas (ej: muchos sistemas P2P)
- Un coordinador (líder) y trabajadores (p. ej. DNS, primary-backup).
Gestión de membresía:
- Crear/eliminar grupos, unir/dejar procesos. Centralizado (servidor de grupo) vs Descentralizado
Algoritmos de consenso
En definitiva, tengo varios procesos redundantes, y necesito una sola respuesta.
- Supuesto: en un sistema tolerante a fallos, todos los procesos ejecutan los mismos comandos, en el mismo orden, de igual manera que todo el resto de los procesos sin errores.
- Problema: ¿Cómo conseguir consenso sobre el comando concreto a ejecutar?
- Enfoques: el algoritmo de consenso elegido depende del modelo de fallo que el sistema debe tolerar
K-Fault Tolerant
Un sistema es k-fault tolerant si puede sobrevivir a fallos en k componentes y seguir cumpliendo sus especificaciones
- fail-silent: componentes
- fail-safe: un mínimo de procesos
Si un sistema k-fault tolerant sufre la caída de más de miembros, no se puede confiar en sus resultados
En unga-unga, si yo te digo "flaquito, fijate que tengo 10 componentes en mi arquitectura y sigo andando si se me caen 5". En la que se me cayeron 6, es imposible confiar en los resultados de mi sistema.
Fallos por caída
| Protocolo/Enfoque | Fallos tolerados | Requisitos mínimos |
|---|---|---|
| Basado en inundación (Flooding) | Fail-stop(detectables de forma fiable) | - |
| Raft | Fail-noisy (la caída es detectada correctamente en algún momento) | - |
| Paxos | Fallos por caída (crash failures). También asume comunicación no fiable y sistemas parcialmente síncronos | servidores para tolerar fallos de caída silenciosa |
Fallos arbitrarios
Estos son los fallos más graves, donde un servidor puede actuar de manera inconsistente o maliciosa, produciendo resultados incorrectos que no pueden detectarse inmediatamente.
| Protocolo/Enfoque | Fallos tolerados | Requisitos mínimos |
|---|---|---|
| Tolerancia Práctica a Fallos Bizantinos (PBFT) | Fallos Arbitrarios (Bizantinos). | procesos para tolerar k fallos arbitrarios. |
| HotStuff | Fallos Arbitrarios (como una mejora de PBFT). | procesos |
Consenso en sistemas de Blockchain
| Tipo de blockchain | Enfoque de consenso | Contexto |
|---|---|---|
| Sin permiso | Basado en elección de líder (p. ej. Prueba de Trabajo PoW, Prueba de Participación PoS) | El líder decide qué bloque se añade |
| Con permiso | PBFT o variantes más escalables (p. ej. HotStuff) | Usado por grupos pequeños de procesos tolerantes a fallos que deciden quién añade bloques |
Limitaciones
- Rendimiento: replicación y organización de procesos implican una pérdida potencial de rendimiento debido a la gran cantidad de mensajes que deben intercambiarse para alcanzar el consenso.
- Procesos asíncrono: es imposible alcanzar el consenso en un sistema asíncrono si existe incluso un único proceso defectuoso (no podemos diferenciar si está caído o está lento)
- Teorema CAP: en los sistemas distribuidos se espera que hayan particiones, lo que obliga a elegir entre
CoA
Comunicación cliente-servidor confiable
Antes hablamos de errores en los procesos. ¿Qué pasa si fallan los canales de comunicación?
- Nos interesa poder manejar los errores.
- Asegurar que los mensajes se procesen una sola vez o al menos de manera predecible.
Examinemos las 2 categorías: Point To Point y RPC
- Point to Point (conexión dedicada)
- Confiabilidad basada en el protocolo de comunicación TCP
- Ante un fallo se puede intentar establecer conexión
- RPC
- Objetivo: hacer parecer que estamos haciendo llamadas locales
Posibles errores - RPC
- No se puede conectar con el servidor
- Se pierde el mensaje enviado por el cliente
- El servidor muere luego de recibir el mensaje
- El mensaje de respuesta del servidor se pierde
- El cliente muere luego de enviar el mensaje
Posibles soluciones - RPC
- Handlear una excepción. Pero se tendría la ilusión de estar usando un servidor local
- Configurar un timeout en el cliente con algún retry.
- Timeout con entry, ¿pero cómo asegurás que no haya un reproceso?
- At least once
- At most once
- No guarantees
- Timeout con retry
- Retransmisión
- Operaciones idempotentes. No siempre se puede (ver saldo vs transferir plata)
- Número de secuencia en los mensajes. Requiere mantener estado
- Bit de retransmisión agregado a la solicitud
- Existen algunas propuestas complejas y con limitaciones. Se recomienda no hacer nada y que, luego del reinicio, se pueda volver a un estado anterior a su reinicio (ver Recuperación).
Respecto a la idempotencia, refiere que al ejecutarse dos veces una solicitud, tenga el mismo efecto.
- La idempotencia es una propiedad del mensaje, aplicada cuando es realmente importante (p. ej. en streaming, ya de base no me interesa volver a enviar un frame si falló)
- El ejemplo más claro es una transferencia bancaria, donde tengo que asegurar que una transacción no se ejecute dos veces.
- Como todo, la idempotencia tiene sus costos.
Comunicación de grupo o multicast confiable
Definición
- Servicio que permite enviar mensajes a múltiples receptores en un sistema distribuido
- Esencial para la tolerancia a fallos
Tenemos como objetivo principal asegurar que los mensajes se entreguen a todos los miembros de un grupo particular
¿Cómo realizamos la comunicación?
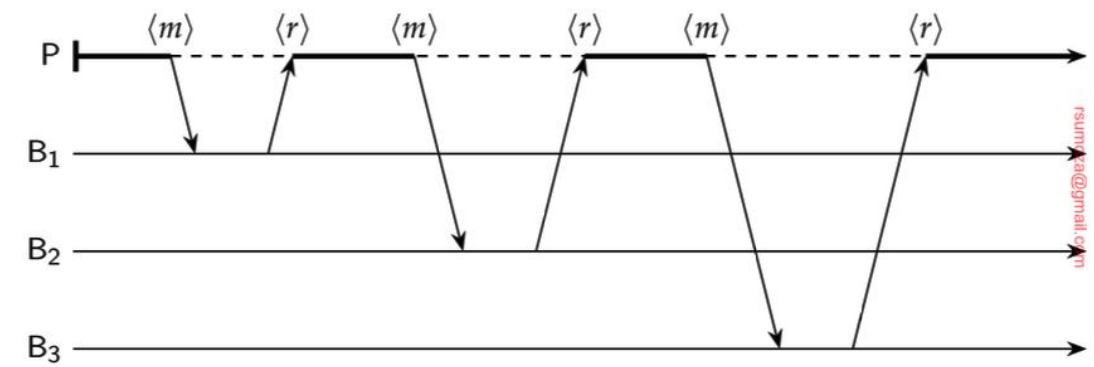 Se realiza una conexión point to point para cada proceso. Puede parecer una solución, pero no realmente. Se queda corta en escalabilidad.
Se realiza una conexión point to point para cada proceso. Puede parecer una solución, pero no realmente. Se queda corta en escalabilidad.
- Si enviamos múltiples solicitudes en paralelo, puede escalar
Orden en los mensajes
- Un mensaje enviado a un grupo debe ser entregado a cada miembro no defectuoso de ese grupo, o a ninguno de ellos si el remitente falla durante la transmisión. Eso se llama: sincronía virtual, establece "todo o nada".
- Pero no asegura el orden de entrega entre mensajes. Para ello se distinguen cuatro tipos principales de ordenamiento
- Multicasts no ordenados (Unordered multicasts)
- También llamados "multicasts confiables"
- Multicasts ordenados FIFO
- Multicasts ordenados causalmente (Causally ordered)
- Entrega totalmente ordenada (Totally ordered): todos los mensajes son entregados en orden a todos los miembros del grupo, independientemente del origen o de su causalidad.
- Multicasts no ordenados (Unordered multicasts)
La sincronía virtual que ofrece una entrega totalmente ordenada se llama Atomic Multicast.
6 formas diferentes de comunicación de grupo (multicast) confiable o sincronía virtual
| Multicast | Ordenamiento | Entrega totalmente ordenada |
|---|---|---|
| Confiable (desordenado) | No | No |
| FIFO | FIFO | No |
| Causal | Causal | No |
| Atomic | No | Sí |
| FIFO Atomic | FIFO | Sí |
| Causal Atomic | Causal | Sí |
Transacciones en servicios
Contexto
- Sistemas complejos con relaciones entre ellos
- Muchas veces tiene que operar sincronizados
- Ejemplos:
- Reservar hotel y vuelo
- ¿Cómo aseguro que se haga todo o nada?
- Cada uno es una operación distinta
Dos operaciones en principio:
- Commit distribuido y atómico
- Complicado hacerlo en ciertos casos distintos a una base de datos
- EJ: algoritmo two-phase commit (2PC), pero en la práctica es un problema más que una solución
- Involucra 1 coordinar y participantes
- Compensaciones
Compensaciones
Deshacer una operación ya realizada. Esto es una gestión para deshacer algo ya realizado. Consiste en "ir desarmando" lo que se fue haciendo. Es una consistencia de negocio donde se deshace lo que se hizo.
- No es un rollback, es decir, no hay un undo de la operación en sí.
- EJ de situación - Despegar.com: reservo el hotel, pero el pasaje ya lo saqué y está commiteado
- Esta opción es la más común en sistemas distribuidos.
Ejemplos de compensación:
- Envío un mail para avisar
- Hago un contramovimiento
Seguridad
Conceptos clave
Objetivos
- Lograr un sistema seguro a través de:
- Autenticación
- Autorización
- Solo con eso se puede asegurar? No
- Necesitamos de:
- Integridad
- Confidencialidad
- Las vamos a obtener a partir de un concepto importante: Criptografía
- Necesitamos de:
También hay que tener en cuenta que pueden haber distintos niveles de seguridad:
- Integridad: las modificaciones de los datos sólo deben ser realizadas por clientes autorizados
- Asegurar completitud y precisión de los datos
- Confidencialidad: la información se divulga sólo a partes autorizadas.
Estas propiedades además permite cumplir con las normas de privacidad como las de la Ley de Protección de Datos Personales (Argentina) o la regulación europea.
-
En estas, el cliente tiene derecho a:
- El olvido de sus datos (que las vueles)
- Esto no es pavada, dadas arquitecturas como los microservicios (muy fácil comerte un culo con esto)
- Entre otras
- El olvido de sus datos (que las vueles)
-
Amenaza de seguridad
- Unauthorized information disclosure
- Se divulga información que no debería haberse divulgado
- Caso GitHub 2022: se exponen todos 🤤 los datos de un montón de usuarios (aprox. 38 TB) por accidente, mientras estaban entrenando un algoritmo de Machine Learning
- Publicaron claves secretas, contraseñas, mensajes internos de Microsoft
- Unauthorized information modification
- Se cambia información que no debería haberse modificado
- Caso "Aysa Australiana": un loco es despedido y sabía que las bombas de agua estaban programadas por radiofrecuencia en canales públicos
- Claramente terminó por abrir manualmente las bombas de agua, largando aguas residuales a parques, hoteles, espacios públicos
- Unauthorized denial of use
- El famoso DDoS
- En 2020 atacaron a Amazon donde se les enviaban 2.3 TB/s y los fundían, les bajaron el servicio, básicamente
- Unauthorized information disclosure
-
Política de seguridad: describen qué acciones tienen permitido o prohibido realizar las entidades dentro de un sistema (usuarios, servicios, datos, máquinas).
Principios de seguridad
- Denegar el acceso por defecto, corta.
- Open design: todos los aspectos deben ser revisables, no aplicar seguridad por ocultamiento. Cualquiera pueda saber qué mecanismo usa, cómo se usa, cómo se implementa, etc.
- Separación de privilegios: aspectos críticos no controlados por una única entidad
- Principio de mínimo privilegio: un proceso opera con los mínimos privilegios posibles
- Actualizá las dependencias, máquina. Por algo el software se actualiza (no solo por cuestiones de seguridad)
Capas de seguridad
¿Dónde aplico la seguridad?
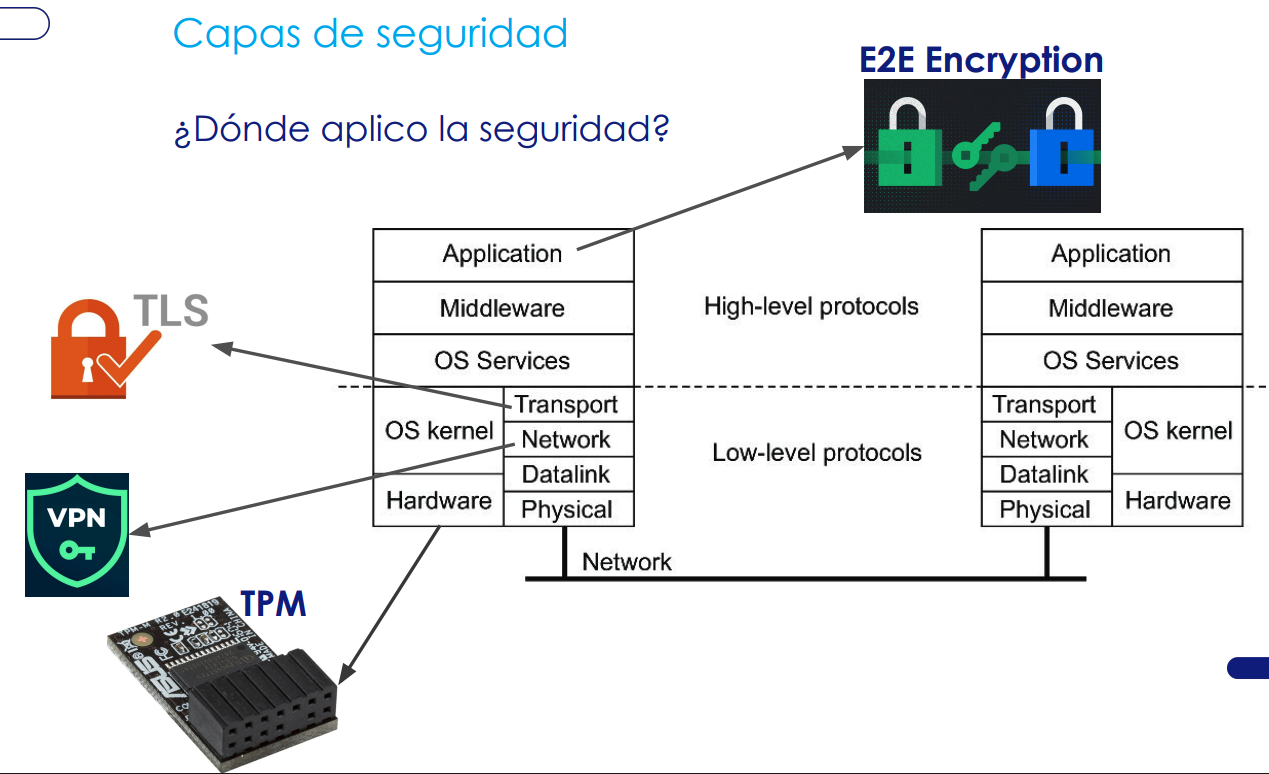
- TPM: Trusted Platform Module. Es un chip que es resistente a modificaciones, alberga algoritmos de encripción, guardado seguro de claves. Te da seguridad a nivel hardware
- VPN: seguridad en capa de red.
- TLS: seguridad en capa de transporte. HTTPS lo usa por debajo.
- E2E Encryption: seguridad a nivel capa de aplicación. Ej: Whatsapp, Telegram, etc.
Todos estos métodos de seguridad en cada capa solamente aplican seguridad, justamente, desde su capa para abajo.
- El TPM no puede afectar de ninguna manera lo que haga la VPN.
Criptografía
Posibles ataques - ¿Por qué encriptar?
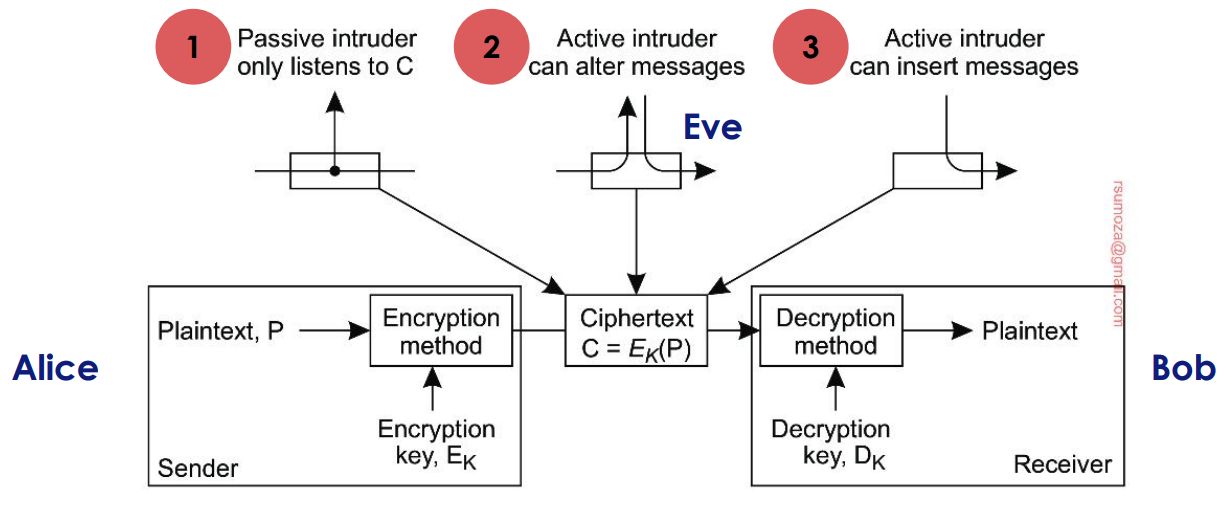
Simétrica y Asimétrica
- Simétrica: uso la misma clave para encriptar y desencriptar
- Asimétrica: se usan claves diferentes pero ambas forman un par único (clave pública y privada)
- Encriptar con este tipo de claves es más costoso, es menos performante
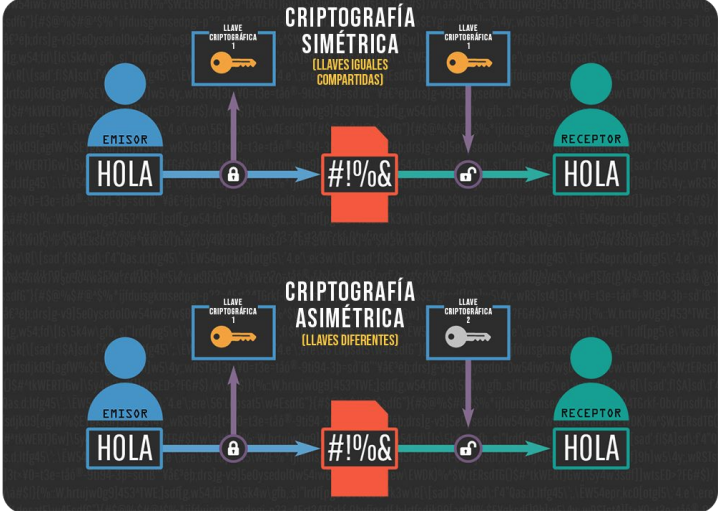
- Encriptar con este tipo de claves es más costoso, es menos performante
Casos de uso
- Simétrica
- Cifrado
- Claves de sesión
- Clave de sesión: clave simétrica generada para cifrar la comunicación entre dos partes durante una sesión específica
- Asimétrica
- Demostrar autoría de un documento
- Establecer un canal seguro entre 2 partes (HTTPS)
Hashing
Se recibe un mensaje m de largo arbitrario y produce un string h de tamaño fijo.
Permite detectar modificaciones de manera simple.
- Función one-way: computacionalmente inviable encontrar la entrada original de un mensaje
ma partir de un hashh - Resistencia a colisiones débiles: dado un mensaje de entrada
my su hashh=H(m), es computacionalmente inviable encontrar otra entrada diferentem', donde . - Resistencia a colisiones fuertes: Esta propiedad es más estricta. Significa que, dada solo la función hash H, es computacionalmente inviable encontrar 2 valores de entrada diferentes cualesquiera
mym', donde .
Computacionalmente inviable refiere únicamente a la actualidad; se puede dar el caso que las computadoras cuánticas o de mayor procesamiento puedan vulnerar un hash.
Casos de uso del hashing:
- Firma digital
- Guardado de passwords
- Asegurarse que un descargable no fue modificado
- Dificultad de minado en algoritmos PoW
PoW = Proof of Work
Firma digital
Es ponerle una marca a un dato con una cierta clave. Es lo que se usa en criptografía asimétrica

¿Qué limitaciones tiene?
- Poder de cómputo y tiempo. Es muy costoso firmar con criptografía asimétrica.
La solución a esta limitante es la siguiente:
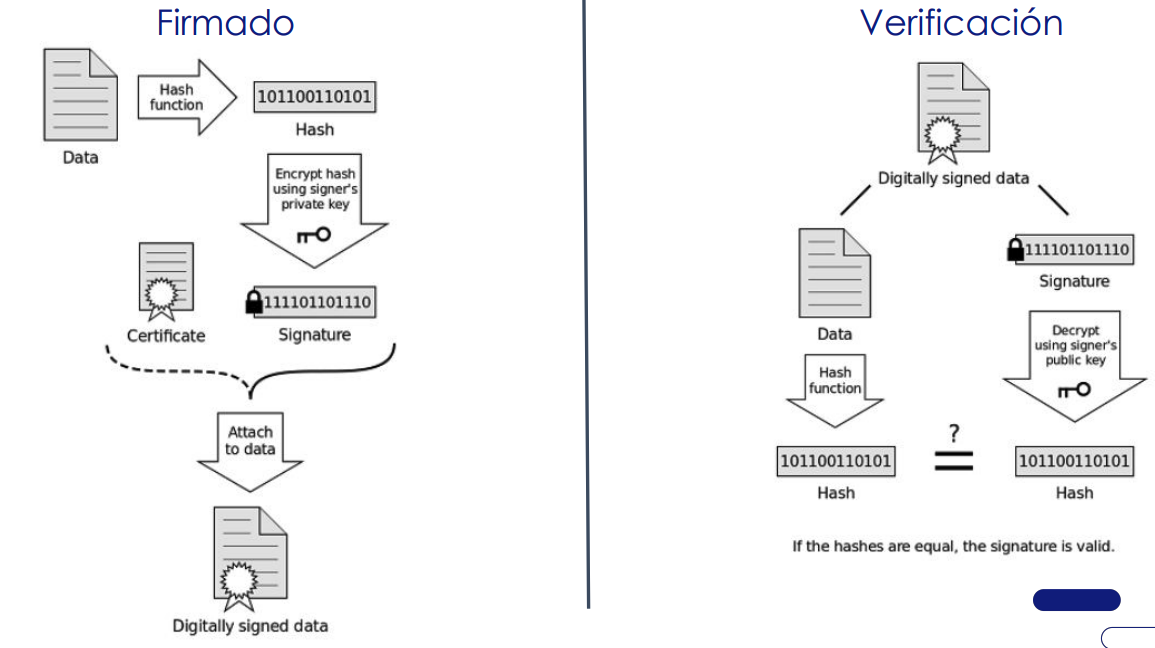
- Generar un hash del dato
- Encriptar el hash (siendo esto la firma)
- Adjuntarlo al certificado
Listo, tengo datos firmados
Del otro lado, voy a poder verificarlo solamente comparando los hashes
Autenticación
Métodos de autenticación
Buscamos:
- Validar la identidad que una persona, software o, en genérico, cliente/entidad dice tener. Asegurarse que estamos tratando con el usuario real
- Hoy no basta con solo un factor de autenticación sino que necesitamos múltiples capas

Autenticación basada en lo que un cliente...
- Conoce: contraseña o un número de identificación del cliente
- Tiene: tarjeta, token, teléfono
- Es: biometría como reconocimiento facial o huella dactilar
- Tiene que ser necesariamente físico
- Hace: biometría dinámica como un patrón de voz o de tipeo
Autenticación continua: no solo se pide validación al ingresar sino dentro de la sesión ante operaciones sensibles
Protocolos
- Autenticación e integridad deben ir juntos
- No le siore de nada a Bob saber que un mensaje vino de Alice si no se puede asegurar que no fue modificado
- Protocolos de autenticación:
- Challenge Response (desafío)
- Key Distribution Center
- Public-key Cryptography
- Luego de la autenticación se usan Session Keys
- Se usan solo durante el tiempo de vida del canal. Al término se destruye
- Permite preservar las lcaves de mayor vida como las que se usan para autenticar. Un atacante con suficiente información encriptada podría deducirla
Challenge-Response (Desafío)
- Se asume que Alice y Bob tienen una clave compartida (simétrica)
- Este método es importante cuando no te podés asegurar de que el canal es confiable/seguro.
- En el caso ideal se asume que nadie puede meterse en el medio ni puede hacerse pasar por una de las 2 partes del canal
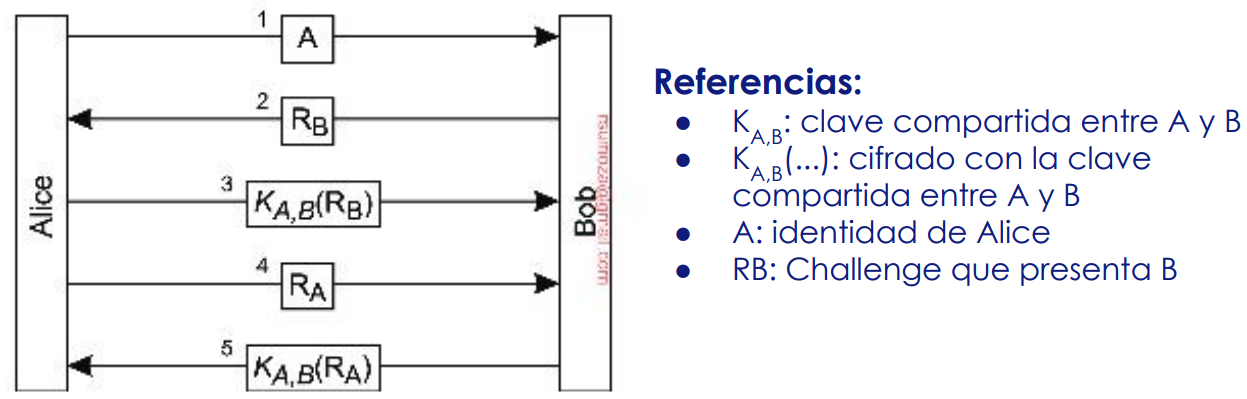
- Hola Bob soy Alice, quiero hablar con vos de manera autenticada
- Hola "Alice", te voy a mandar un Challenge para verificar que realmente sos Alice
- Este challenge puede ser una palabra
- Alice firma el
challengecon la clave compartida que tiene con Bob - Bob compara la firma y se asegura que realmente es Alice, y le manda un OK
- Alice le dice ahora a Bob que le va a mandar un Challenge para lo mismo.
- Ya sabemos cómo termina.
En una versión simplificada (3 pasos):
- Alice le manda a Bob un mensaje diciendo que es ella y su challenge
- Bob le manda el challenge de ella firmado y un nuevo challenge para que ella firme
- Alice le manda el challenge que recibió ya firmado
¿Qué problemas trae? Es muy propenso a ataques de Man In The Middle.
Si el atacante se pone a escuchar el canal de comunicación, puede deducir fácilmente la firma [Insertar el ejemplo de Chuck]
Key Distribution Center
- Si tenemos muchos hosts se tienen que almacenar muchísimas claves compartidas. Se usa un Trusted Party que genera Session Keys.
- Se hace uso de un ticket, que es un mensaje de cifrado de naturaleza temporal
- En principio la otra parte que recibe la Session Key no va a saber comprenderlo, puesto que está cifrado
- Existe un protocolo más avanzado basado en este: Needham-Schroeder
- SSO también se basa en este protocolo
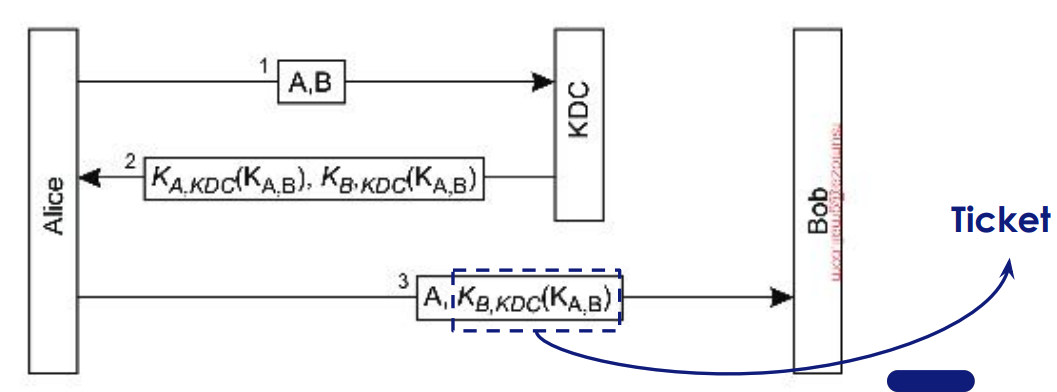
La diferencia principal con el protocolo anterior es que hay una sola clave compartida, con el KDC.
En resumen, el KDC es una parte confiable, y sus tickets sirven como garantía. Un host obtiene un ticket para comunicarse con otro servicio y puede hablarle al mismo sin problema, ya que dicho servicio puede validar con el ticket que el host emisor es legítimo.
El KDC presenta un SPoF, todos confían en este. Si lo hackean, cagaron todos.
Criptografía de clave pública
- Se asume de antemano que ambas partes conocen la clave pública del otro (ambos usando pares de claves asimétricas)
- Alice envía su identidad y challenge firmado con la clave pública de Bob
- Importante tener garantía que Alice tiene la clave pública de Bob y no de alguien que se hizo pasar por él
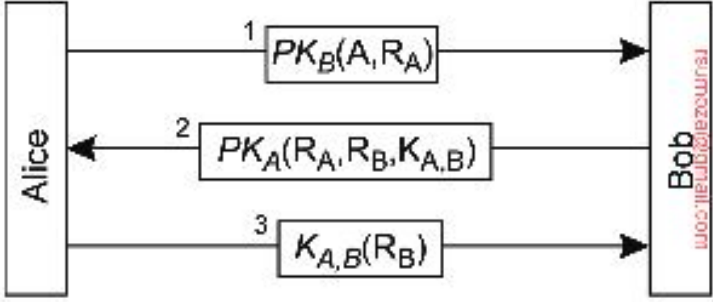
La diferencia respecto al Challenge-Response es que no tienen que firmar con una clave compartida, sino que firman con la clave pública y se van a asegurar de que sólo lo pueda leer quien tenga la clave privada.
La falencia de este protocolo es que por ahí la clave pública que tiene Alice no es necesariamente la de Bob, sino que puede ser la de otra persona que lo impersonó, justamente
Desafíos que enfrentan los protocolos
- Garantizar la integridad del mensaje y la autenticación mutua
- Suplantación de identidad
- Ataques de replicación
- Gestionar eficientemente las claves secretas compartidas en sistemas grandes
- Distribución de claves, basicamente
- Las claves se tienen que rotar de alguna manera.
- Si pierdo la clave privada, tengo que notificarlo a quienes tengan mi clave pública
- Autenticidad de las claves públicas
- No revelar información sensible antes de la autenticación de las partes
Autorización
Definición: Conceder acceso a los recursos del sistema una vez autenticada una entidad
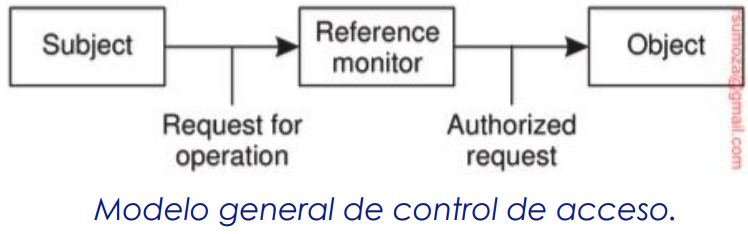
Reference monitor
- Almacena quién puede hacer qué
- Decide cuándo un sujeto puede hacer una operación
Enfoques de protección
3 enfoques principales:
- Proteger la información o el dato, en su integridad
- Proteger las operaciones a realizar
- Proteger quién tiene acceso a la información
Políticas de control de acceso
Aclaración: AC = Access Control o Control de acceso
- MAC - Mandatory AC: la administracion central define políticas de acceso (ej: niveles de secreto, desde público a top secret)
- DAC - Discretionary AC: el propietario de un objeto decide quién tiene acceso (ej: permisos de archivos Unix, archivos de Google Drive)
- RBAC - Role Based: la autorización se basa en el rol del usuario en la organización (ej: profesor, estudiante)
- ABAC - Attribute Based: control de acceso más granular, basado en atributos de usuarios, objetos, entorno, conexión y administrativos (ej: Si tenés un DNI muy viejo/nuevo no podés hacer tal cosa)
Delegación
- ¿Cómo delegar derechos de acceso sin compartir las credenciales principales?
- ¿Cómo hacerlo sin tener que estar consultando al usuario que delegó todo el tiempo?
Respuesta: Proxy
- Un proxy permite a su poseedor operar con derechos y privilegios iguales o restringidos en comparción con el sujeto que lo concedió
- Incluso le puede permitir delegar a su vez alguno o todos los derechos a otro usuario
El proxy puede impersonar (sin ser un ataque) a otro usuario/persona/entidad.
Estructura Proxy
- Certificado a. : conjunto de derechos de acceso delegados. b. : es la parte pública de un secreto utilizada para autenticar al poseedor. c. El certificado está firmado por el emisor A para protegerlo contra modificaciones.
- Clave Secreta: parte secreta que debe protegerse de la divulgación
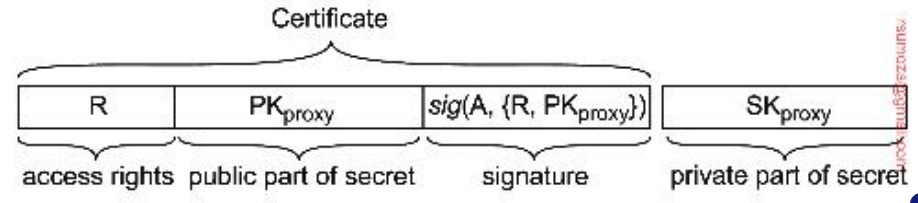
Proceso
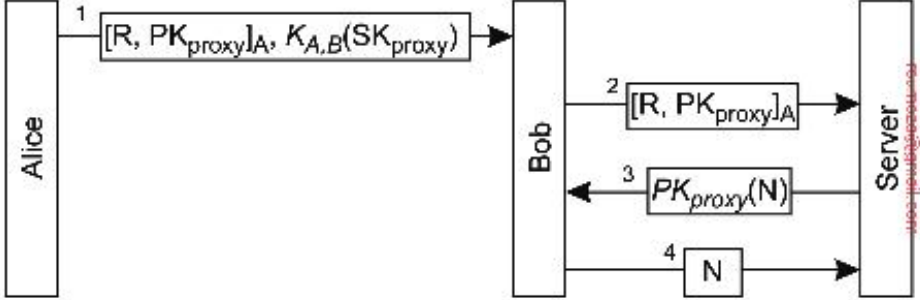
- Alice le da a Bob la lista de derechos firmada junto con la parte pública del secreto. También le da la secret key cifrada.
- Bob ejerce sus derechos, entrega lista firmada.
- Se le pide la respuesta a un nonce firmado con la pub key.
- Si Bob la proporciona, el Server sabrá que los derechos listados fueron delegados a Bob por Alice.
OAuth
- Es un protocolo de delegación usado por grandes empresas (Amazon,
 , Facebook, Microsoft, Twitter) y por muchos otros servicios.
, Facebook, Microsoft, Twitter) y por muchos otros servicios. - Su objetivo es permitir que una aplicación (por ejemplo, un cliente de correo o una app móvil) pueda acceder a recursos de un usuario (como tus correos, fotos o contactos) en otro servicio, sin que la app reciba directamente la contraseña del usuario.
- A diferencia de otros sistemas de delegación tipo proxy, en OAuth el usuario otorga permisos de manera granular (por ejemplo, "dejo que esta app vea mis contactos, pero no mis fotos"), y el acceso suele estar acotado por tiempo.
- OAuth separa claramente la autenticación (saber quién sos) de la autorización (qué puede hacer esa app en tu nombre), y usa tokens de acceso en vez de claves secretas largas o certificados que la aplicación debería proteger todo el tiempo.
- Esto reduce el riesgo en caso de compromiso y facilita revocar permisos específicos a aplicaciones sin afectar el acceso general del usuario.
Confianza
Muchas de las decisiones las realizamos basadas en la confianza.
- Robos de cuentas de Whatsapp para pedir transferencias.
- Compras Crypto que se apalancan en la opinión de algún personaje conocido.
- Videos o imágenes fakes para hacer campañas de desinformación.
En los sistemas hay muchas decisiones que se realizan de manera (semi)automatizados.
- ¿Cómo afecta eso a nuestras vidas?
- ¿Podemos confiar en esas decisiones?
Definición: La confianza es la certeza que una entidad tiene de qué otra se comportará de acuerdo con una expectativa específica.
- Complemento a la Autenticación: Si bien la autenticación verifica una identidad, la pregunta clave es: ¿cuánto vale esa autenticación si no se puede confiar en la persona?
- Limitación de Daños: una autorización adecuada es vital, ya que puede usarse para limitar cualquier daño.
- Dependencia y Expectativas: Si las expectativas se hacen lo suficientemente explícitas (es decir, especificadas), es posible que ya no sea necesario depender de la confianza.
- Ej: entre los microservicios de un sistema cerrado no hace falta estar autenticando a cada momento.
Ataques Bizantinos
- Volviendo a procesos resilientes si queremos soportar ataques bizantinos debemos construir un sistema donde no haya confianza.
- Esto se logra especificando algoritmos de consenso que no dependen de un individuo sino de un grupo.
- Para lograr k-tolerance a fallos bizantinos, se requiere un total de servidores.
- Si quiero soportar 1 servidor dañino se requiere 4 servidores en total
Confiar en una identidad
- Enfoque: Se centra en la relación entre una identidad lógica y una entidad física.
- Problemática: El problema fundamental es el ataque Sybil, donde un atacante presenta múltiples identidades lógicas para controlar una parte desproporcionada del sistema.
- Posible solución: Se requieren mecanismos de contabilidad y prueba de coste que hagan que la clonación de identidades no sea rentable, como (Proof of Work, PoW) o (Proof of Stake, PoS) en blockchains
Confiar en un sistema
- Enfoque: Se centra en cómo una estructura de datos distribuida puede generar confianza sin depender de terceros.
- Problemática: La necesidad de asegurar la integridad de los datos y su inmutabilidad.
- Posible solución: La confianza se deriva de la transparencia y la protección criptográfica. En blockchain se logra a través de la vinculación mediante hashes de los bloques. Asegura que cualquier cambio en un bloque se propague y sea detectable en toda la cadena.
En resumen...
Confiar en una Identidad:
- ¿La identidad que interactúa es legítima y única?
- Especialmente relevante en sistemas descentralizados donde la reputación es crucial para la toma de decisiones. Confiar en un Sistema:
- Garantía técnica de que la información almacenada en el sistema es correcta y no ha sido manipulada.
Monitoreo y auditoría
Introducción
- Objetivo: garantizar que las políticas de seguridad se cumplen.
- Auditoría: herramienta pasiva para saber qué fue lo que sucedió. Pero no ayuda a prevenir.
- Para eso existe: Intrusion detection, busca detectar actividades no autorizadas.
Herramientas - Firewall
- Filtro de tráfico.
- Puerta de entrada o salida hacia el mundo exterior.
- Decide qué tráfico es permitido o descartado.
- Categorías:
- packet-filtering: funciona como router y decide según el contenido de los headers del paquete.
- application-level: decide según el contenido del mensaje. Ejemplos: mail gateway o proxy gateway.
Herramientas - Intrusion Detection Systems (IDS)
- SIDS - Signature-based Intrusion Detection Systems
- Funcionan comparando patrones de intrusiones ya conocidas a nivel de red.
- Limitación: resultan menos útiles ante ataques nuevos o desconocidos
- AIDS - Anomaly-based Intrusion Detection Systems
- Se basa en la premisa que se puede modelar un comportamiento típico del sistema para luego detectar cualquier comportamiento anómalo.
- Se basa especialmente en herramientas de IA como Machine Learning.
- Desafío: disminuir los falsos-positivos (etiquetado incorrecto como intrusión) manteniendo un número bajo de falsos-negativos (intrusiones omitidas).
Guía Introductoria
Sistemas centralizados, descentralizados y distribuidos
Acá buscamos que se afiance el entendimiento de porqué es necesario y/o suficiente hacer un sistema distribuido. Para poder analizar y clasificar y entender las razones que nos mueven a hacerlo más complejo.
Ejercicio 1
Califique y justifique los siguientes sistemas bajo estos conceptos.
- Gmail
- Spotify, Netflix
- Un server NAS (eg. synology)
- Un Home Assistant con las luces y sensores de la casa
- Una IA corriendo en un datacenter
- Un cluster de virtualización de computadoras
- Un tótem de información en el medio de un parque Elija un sistema de su preferencia: Descríbalo, clasifíquelo y justifique
Respuesta:
- NAS (Network Attached Storage): es un sistema centralizado porque la decisión de a quién darle la información es de un único nodo. Es un rack de discos conectado a la red, en definitiva.
- Home Assistant: es un sistema centralizado porque quien determina el estado de las luces lo expone un sólo nodo. Independientemente de si se desincroniza o no, la responsabilidad de estar sincronizado es del server, de un único nodo.
- Netflix, Spotify: son sistemas centralizados, puesto que los nodos que deciden el contenido que existe en X zona, qué usuario ve qué, etc., toman las decisiones de manera central en cada zona, a pesar de que para obtener el contenido hagan una especie de "pasamanos".
- Tótem de información: es un sistema centralizado, puesto que el origen de la información es uno solo.
- IA en Data Center: es un sistema centralizado, dado que todos los servicios que consumen esa IA le hacen preguntas a esa, la cual da las respuestas de manera centralizada.
- Cluster de virtualización de computadoras: es un sistema centralizado, porque a pesar de que cada entorno virtual haga lo suyo, todos le "preguntan" cosas al sistema central/intermedio, el HyperVisor.
- Gmail: es un sistema centralizado, porque replica información de la infraestructura central de Google pero toma las decisiones de manera centralizada en cada instancia de "clusters" de servicios.
Ejercicio 2
Elija un sistema de su preferencia: Descríbalo, clasifíquelo y justifique.
Respuesta
El Cluster de Redis es una implementación distribuida de Redis, cuyos objetivos son los siguientes:
- Alto rendimiento y escalabilidad lineal hasta 1000 nodos. No hay proxies, se utiliza replicación asíncrona y no se realizan operaciones de fusión sobre los valores.
- Grado aceptable de seguridad en las escrituras: el sistema intenta (en la medida de lo posible) retener todas las escrituras originadas por clientes conectados con la mayoría de los nodos maestros. Usualmente existen pequeñas ventanas en las que se pueden perder escrituras ya confirmadas. Estas ventanas son más grandes cuando los clientes están en una partición minoritaria.
- Disponibilidad: Redis Cluster es capaz de sobrevivir a particiones donde la mayoría de los nodos maestros son accesibles y existe al menos una réplica accesible para cada nodo maestro que ya no lo está. Además, utilizando migración de réplicas, los maestros que ya no son replicados por ninguna réplica recibirán una desde un maestro que esté cubierto por múltiples réplicas.
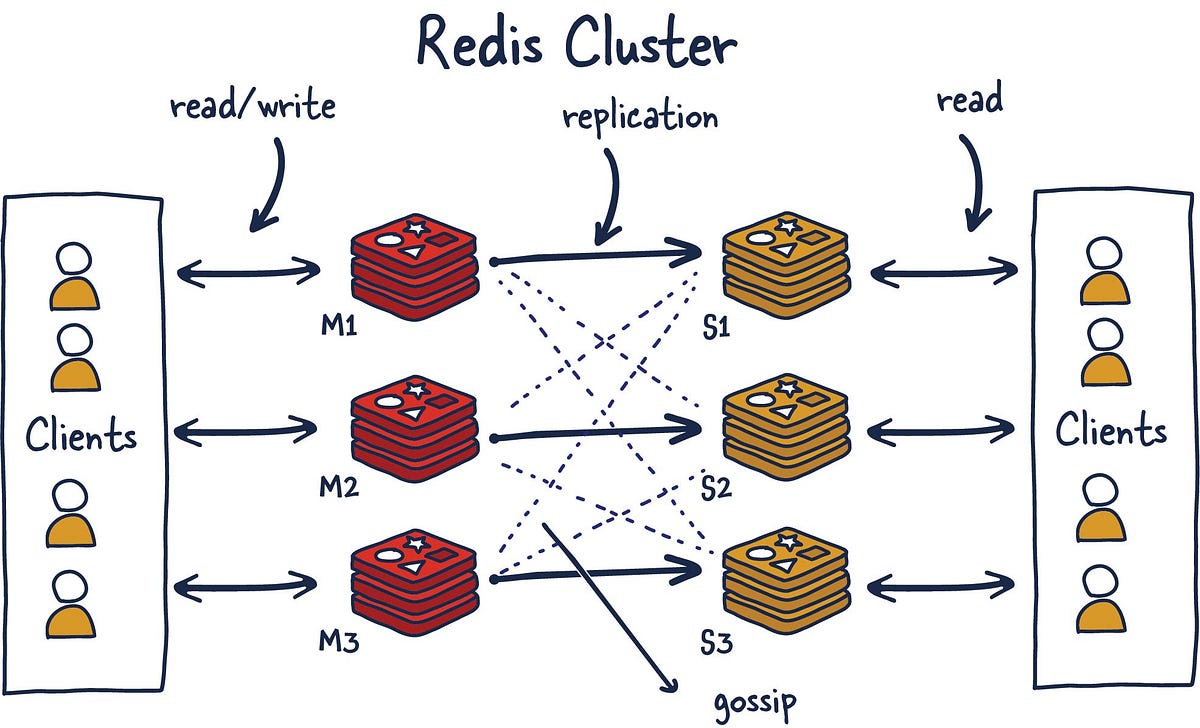
Funciona de esta manera: En Redis Cluster, los nodos son responsables de almacenar los datos y de mantener el estado del clúster, incluyendo el mapeo de las claves hacia los nodos correctos. Los nodos del clúster también pueden descubrir automáticamente otros nodos, detectar nodos que no están funcionando y promover nodos réplica a maestros cuando es necesario para que el sistema siga operando ante una falla.
Para realizar estas tareas, todos los nodos del clúster están conectados mediante un bus TCP y un protocolo binario llamado Redis Cluster Bus. Cada nodo está conectado con todos los demás nodos del clúster a través de este bus. Los nodos utilizan un protocolo de gossip para propagar información sobre el clúster, descubrir nuevos nodos, enviar paquetes de ping para asegurarse de que los demás nodos estén funcionando correctamente y enviar mensajes específicos del clúster para señalar ciertas condiciones. El bus del clúster también se utiliza para propagar mensajes de Pub/Sub a través del clúster y para orquestar failovers manuales cuando son solicitados por los usuarios (los failovers manuales son aquellos que no son iniciados por el detector de fallos de Redis Cluster, sino directamente por el administrador del sistema).
Dado que los nodos del clúster no pueden hacer de proxy para las solicitudes, los clientes pueden ser redirigidos a otros nodos usando los errores de redirección -MOVED y -ASK. En teoría, el cliente es libre de enviar solicitudes a cualquier nodo del clúster y será redirigido si es necesario, por lo que no se requiere que el cliente mantenga el estado del clúster. Sin embargo, los clientes que pueden cachear el mapeo entre claves y nodos pueden mejorar el rendimiento de manera significativa.
Entonces, en cuanto a su clasificación, podemos decir que es un sistema distribuido descentralizado, por el hecho de que no existe un único nodo master por cluster que tome las decisiones o que tenga el control absoluto sobre el resto de nodos del cluster, si no que las decisiones son tomadas por cualquier nodo, teniendo todos la misma autonomía. Estas decisiones, como bien se menciona previamente, pueden ser:
- Qué nodo se tiene que apagar
- Qué nodo réplica se tiene que promover a ser un master (de acá viene la resiliencia del sistema)
- A quién le tienen que pasar qué mensaje (sabiendo que usan Pub/Sub como modelo de comunicación)
Los ejercicios 3 y 4 no los voy a hacer porque es innecesario dado lo hecho en los ejercicios anteriores.
Ejercicio 5
Dado un server plex corriendo en una raspberry donde tengo todos los videos familiares en el mismo disco, ¿cuándo pasaría a ser un sistema distribuido y por qué?
Respuesta
Previo a dar una respuesta, es necesario aclarar cómo funciona un Server Plex.
Server Plex: es un sistema de streaming personal que te permite centralizar tu biblioteca de películas, series y música en un servidor propio. Funciona indexando tus archivos multimedia y transmitiéndolos a tus dispositivos (TV, celular, PC) vía red local o internet. Se apoya en transcodificación para adaptar la calidad según el dispositivo y la conexión.
Entonces, tomando la definición al principio de la clase 2, este pasaría a ser un sistema distribuido en el momento en el que se instala, dado que requiere que todos los dispositivos que se conecten a él requieren conectarse por red para lograr el objetivo en común que es streamear películas.
Problemas de los sistemas distribuidos
El primer paso para un buen entendimiento es conocer los problemas que pueden ocurrir cuando dos o más computadoras se comunican entre sí
Ejercicio 1
Busque ejemplos conocidos de problemas relacionados con cada uno de los ítems:
- Las computadoras se rompen
- No saben con quién comunicarse
- No se ponen de acuerdo
- Se corta la comunicación
- Se pierden los bits
- Pueden venir intrusos
- Obvio… hay bugs en el código
Respuesta
| Problema | Ejemplo |
|---|---|
| Las computadoras se rompen | Se prende fuego el espacio físico donde corre un server |
| No saben con quién comunicarse | Entra un nodo nuevo a la red y no conoce a los demás, teniendo una red donde el protocolo de comunicación no permite que los "descubra" |
| No se ponen de acuerdo | 2 nodos tienen problemas de consenso porque tenían la misma prioridad asignada |
| Se corta la comunicación | El datacenter pierde la conectividad y queda aislado |
| Se pierden los bits | Se rompe un paquete de TCP |
| Pueden venir intrusos | Hay un ataque de MiTM |
| Obvio… hay bugs en el código | Un microservicio entra en loop infinito porque pusieron mal la condición de corte de un método recursivo |
Ejercicio 2
Para cada uno de esos problemas, busque ejemplos donde se han resuelto.
- Por ejemplo: los discos hot swap, que se pueden reemplazar sin apagar el equipo
Respuesta
| Problema | Ejemplo |
|---|---|
| Las computadoras se rompen | Google Spanner replica datos en varios continentes, de modo que si un datacenter falla, otro sigue respondiendo. |
| No saben con quién comunicarse | Kubernetes usa un Service Discovery (DNS interno + etcd) para que los pods encuentren a otros sin conocer su IP. |
| No se ponen de acuerdo | Apache Zookeeper implementa un protocolo de consenso (Zab) para elegir un líder único y evitar conflictos. |
| Se corta la comunicación | Amazon S3 replica objetos en distintas Availability Zones, permitiendo acceso incluso si una zona queda aislada. |
| Se pierden los bits | TCP usa confirmaciones (ACK) y retransmisiones automáticas para asegurar que los datos lleguen completos. |
| Pueden venir intrusos | HTTPS/TLS cifra las comunicaciones, evitando ataques de man-in-the-middle en servicios como Gmail o Netflix. |
| Obvio… hay bugs en el código | Netflix Chaos Monkey detecta fallos inyectados y prueba la resiliencia de los servicios para mejorar el software. |
Guía Comunicación
Modelo OSI
Ejercicio 1
Explicar por qué el modelo OSI es anticuado o poco representativo y por qué se opta por hablar de middleware.
Respuesta
El modelo OSI no necesariamente representa un protocolo de comunicación puntual ni mucho menos un conjunto de protocolos, sino que es un modelo de referencia con demasiadas capas y con complejidad extra respecto al modelo que hace uso de Middleware, ya que para cada capa hay que implementar un protocolo de comunicación puntual que, a su vez, debe ser compatible con los de la capa superior e inferior, siendo extremadamente caro de seguir y poco transparente.
En cambio, se opta por TCP/IP, sobre el que se distingue la capa de middleware, la cual es una capa de abstracción que brinda la transparencia de la que carece OSI.
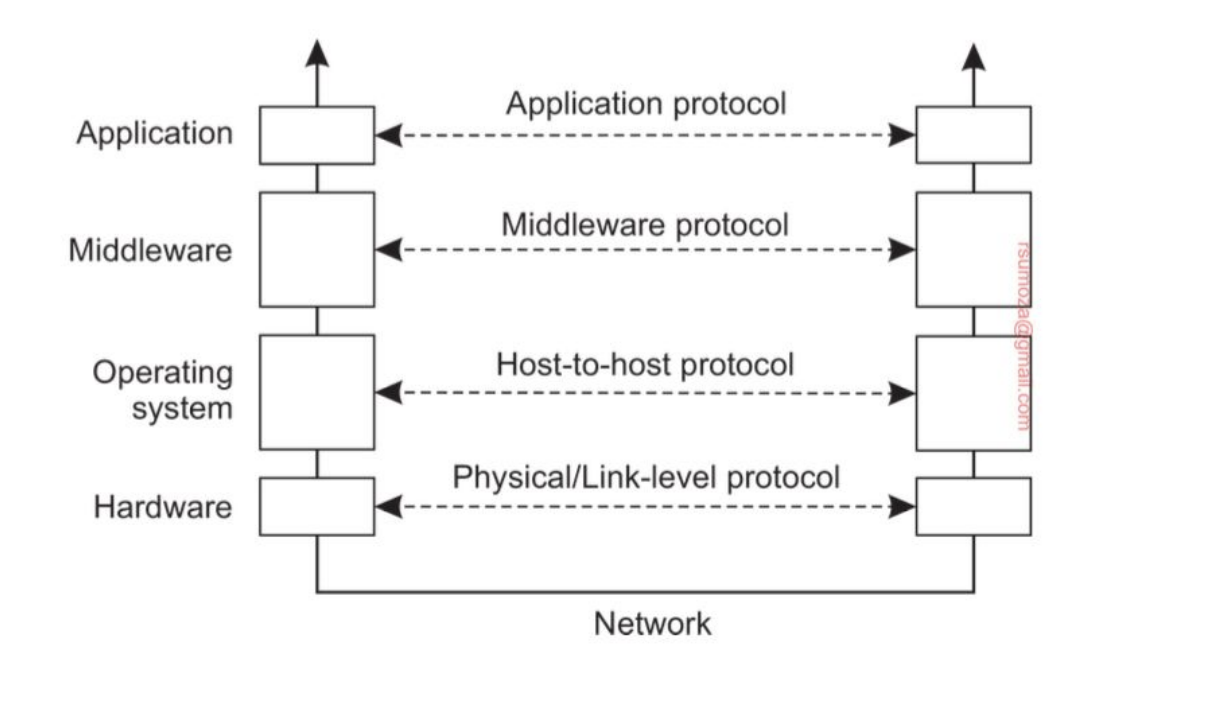
RPC
Ejercicio 1
En clase se presentó RPC. ¿Cómo se relacionan con los siguientes conceptos?
- HTTP
- REST
- gRPC
- GraphQL
Desarrollar un párrafo corto sobre cada uno de los temas y comparar o establecer la relación con RPC. Considerar qué aspectos comparten y cómo se diferencian
Respuesta
- HTTP: protocolo de comunicación que opera a nivel capa de aplicación, usado para transferir documentos de "hypermedia" como páginas web entre un cliente (generalmente un browser) y un servidor. El modelo de comunicación que sigue es el de REQ/REP, visto en la clase de Comunicación
- gRPC: framework open-source para implementar RPC (Remote Procedure Call) sobre cualquier aplicación. Usa HTTP por debajo, más concretamente HTTP/2. Las APIs REST usan HTTP/1.1
- REST (Representational State Transfer): estilo de arquitectura para web apps que sigue el modelo cliente-servidor, cuya interfaz es uniforme al hacer uso de HTTP como protocolo de comunicación (basada en métodos HTTP como GET, PUT, POST, DELETE).
- GraphQL: estilo de arquitectura orientado a queries hacia APIs, que también opera sobre HTTP. La diferencia principal respecto a REST es que obtiene exactamente la data que pide.
- Ej: si yo tengo una API que expone un endpoint que devuelve una respuesta del estilo
{
"name": string,
"surname": string,
"dni": number
}
- En un API REST, al pegarle a ese endpoint obtendría todo el JSON.
- En un API del estilo GraphQL, si pido:
{
name,
surname
}
- obtengo sólo eso, se ignora por completo el DNI.
Relaciones con RPC:
- HTTP: RPC opera generalmente sobre HTTP para hacer los Call-To-Action.
- gRPC: gRPC es un framework que permite implementar RPC sobre diversos lenguajes
- REST: tanto las APIs REST como RPC usan HTTP por abajo. Mientras que uno es un modelo de llamados remotos a operaciones y otro es un estilo de arquitectura, ambos se sirven de la misma herramienta para lograr su objetivo.
- GraphQL: la forma de operar entre ambos es parecida, en RPC el cliente decide a qué procedimiento llamar específicamente, mientras que en GraphQL el cliente decide qué datos específicos quiere traerse.
Ejercicio 2
¿Qué es gRPC? ¿Por qué se desarrolló? ¿Por qué no se usa en aplicaciones web? ¿Por qué si se usa en mobile? ¿Qué nos ofrece por sobre la definición de RPC vista en clase?
Respuesta
gRPC lo desarrolló Google porque estuvieron usando una única infraestructura de uso general llamada Stubby (que usa los stubs que vimos en clase) para conectar una gran cantidad de microservicios distribuidos en los data centers de Google. ![]()
En resumen, gRPC nace a modo de evolución de Stubby, ya que este último estaba altamente acoplado a la infraestructura interna de Google como para poder ser público. Además, tenían un objetivo urgente de extenderse a casos de uso modernos, como sistemas mobile, IoT y Cloud.
Sabiendo que gRPC usa HTTP/2 por debajo, no puede usarse en web apps porque ni los browsers ni las APIs REST existentes lo soportan, dado que se basan en respuestas basadas en JSON, mientras que gRPC usa Protobuf (streams binarios multiplexados). Se puede usar gRPC-Web como solución intermedia, pero no alcanza, ya que tampoco es gRPC puro.
En mobile, el stack de red es decidido por quien desarrolle dicha app mobile, por lo que puede usar librerías que le den soporte sobre HTTP/2 a la aplicación en cuestión.
Ejercicio 3
Explicar qué es Protocol Buffers y por qué se usan junto con gRPC. Comparar con JSON y XML en términos de tamaño, eficiencia y flexibilidad.
Respuesta
Protobuf (o Protocol Buffers) son mecanismos de serialización de datos flexibles y extensibles, ya que son agnósticos a la plataforma y al lenguaje. Es como un XML más chico, rápido y simple.
Vos definís cómo estructurar los datos una vez, y después usás código específico para leer y escribir esos datos estructurados desde y hacia APIs que lo soportan. (Ver ejemplo en el link)
Ejercicio 4
Implementar un servidor en Python y un cliente de JavaScript usando gRPC. El cliente debe enviar una lista de personas y el servidor debe responder con el usuario de mayor edad.
Person {
string name;
int age;
}
Respuesta
MPI
Ejercicio 1
¿Cuál es la definición de mensaje en el contexto de la comunicación basada en mensajes?
Respuesta
No está en el libro ni en los slides, así que contesto lo que me parece:
Es la unidad mínima de comunicación de un sistema distribuido, una unidad de datos que contiene ciertos metadatos ordenados que un emisor le envía a un cierto destinatario. En el contexto de un sistema distribuido, tanto emisor como receptor son procesos, necesariamente.
A partir de estos mensajes, los procesos pueden ordenarse y coordinarse.
Ejercicio 2
¿En qué escenarios se usa MPI? Listar ejemplos reales y citar fuentes.
Respuesta
| Escenario | Detalles |
|---|---|
| Modelado climático, dinámica de fluidos y ciencia de materiales | MPI es ampliamente utilizado en simulaciones científicas complejas como predicción climática, dinámica de fluidos o estudios de comportamiento de materiales, donde se necesita comunicación eficiente entre miles de procesos en supercomputadoras. (Number Analytics) |
| Supercomputadoras exascala (ECP, Frontier, Aurora, El Capitan) | En sistemas exascala patrocinados por el Departamento de Energía de EE.UU., MPI (específicamente MPICH) es la interfaz de comunicación estándar para coordinar procesos entre CPUs y GPUs en estos superordenadores. (exascaleproject.org) |
| Exploración paralela de estructuras de archivos (MPI-FTW) | En Los Alamos National Laboratory se desarrolló una herramienta llamada MPI-FTW que explora árboles de archivos en paralelo usando MPI, dividiendo tareas entre procesos y acelerando drásticamente el recorrido comparado con versiones seriales. (hpc.nmsu.edu) |
| Simulaciones neurológicas con MUSIC sobre MPI | El framework MUSIC permite la comunicación entre simuladores neuronales en clusters a gran escala (como Moose, NEURON, NEST), utilizando MPI como capa de transporte para intercambiar eventos y datos en simulaciones de redes neuronales. (Wikipedia) |
| Visualización y renderizado científico (Tachyon) | Tachyon, un motor de renderizado paralelo, fue portado a MPI y usado para visualización en supercomputadoras como Blue Waters. Fue clave en la generación de imágenes científicas, como la estructura del virus HIV-1, y en proyectos relacionados con SARS-CoV-2. (Wikipedia) |
| Entrenamiento distribuido de redes neuronales (MPI + Keras) | Se creó un framework en Python que combina Keras con MPI para entrenar redes neuronales distribuidas en múltiples GPUs/CPUs, usando MPI para coordinar y sincronizar el proceso de entrenamiento. (arXiv) |
Ejercicio 3
Explicar por qué MPI no se usa de forma generalizada en aplicaciones web. Relacionar esto con: transporte, persistencia de conexiones, seguridad y compatibilidad.
Respuesta
De entrada, la latencia en los casos en los cuales se usa MPI es DEMASIADO BAJA, yendo al orden de magnitud de nanosegundos, cosa que es prácticamente imposible en las web apps que manejamos nosotros.
En cuanto al transporte, el ancho de banda que MPI requiere es altísimo, puesto que se envían volúmenes de datos mucho mayores en comparación a los que enviamos regularmente en web apps.
En lo que a persistencia de conexiones refiere, las conexiones son "efímeras" en MPI: como toda la jerarquía involucrada requiere que todos los procesos empiecen y terminen en simultáneo y bajo un mismo contexto, es imposible implementarlo en una web app, puesto que pueden haber ocasiones donde el cliente o el servidor están apagados por la razón que sea, y si implementásemos MPI serían necesario reiniciar AMBOS para poder establecer la conexión nuevamente. Además es muy poco resiliente, si revienta uno de los procesos asociados revienta todo.
Yendo al lado de seguridad, MPI no tiene mecanismos de seguridad integrados. Depende completamente del protocolo de comunicación que use por debajo, nada te asegura que esté usando UDP o HTTPS.
Por último, en cuanto a compatibilidad, MPI no es universal como HTTP. Es un bodrio de implementar para que sea compatible.
ZeroMQ
Esto está explicado muy bien en la teórica, así que veo innecesario hacer los ejercicios.
Otros tipos de comunicación
Ejercicio 1
Lista 3 message brokers y sus características principales. ¿Es Apache Kafka un message broker?
Respuesta
- RabbitMQ:
- Message & streaming broker Open Source
- Soporta diversos protocolos de comunicación (como AMQP y MQTT). También soporta RPC.
- Provee una gran flexibilidad en cuanto a las operaciones que puede realizar (ruteo, filtrado, streaming, "federation", etc.).
- Brinda una alta confiabilidad gracias a la posibilidad de confirmar la entrega de mensajes y de replicarlos a través de un cluster.
- Redis
- Se maneja por el protocolo Pub/Sub
- Permite mandar mensajes "ligeros", instantáneos y eficientes, óptimos para arquitecturas de baja latencia.
- Ofrece persistencia para evitar la pérdida de mensajes y Point-In-Time-Snapshots
- Permite comunicación en tiempo real
- Se maneja por el protocolo Pub/Sub
- Amazon SQS
- Message broker que se maneja como una cola de mensajería.
- Todo aquel que quiera escuchar lo que se produjo/fue enviado por esa queue debe hacer un
POLL. - Los productores y consumidores están totalmente desacoplados
- Permite escalabilidad horizontal
- Los mensajes pueden ser retenidos hasta 14 días
- Los mensajes que fallan al procesarse después de varios intentos son enviados a una Dead-Letter-Queue (DLQ) para evitar bloquear el workflow principal.
- Soporta 2 tipos de queue:
- FIFO (First In First Out), que ejecuta el
exactly-once-delivery - Estándar, donde los mensajes se procesan en el orden en el que se mandaron y ejecuta el
at-least-once-delivery
- FIFO (First In First Out), que ejecuta el
Ejercicio 2
Listar tres herramientas que sirven para desarrollar o montar Enterprise Application Integration basadas en mensajes.
Respuesta
- Apache Kafka
- RabbitMQ
- Azure Service Bus
Ejercicio 3
Dar un ejemplo concreto de herramientas que nos habiliten cada combinación de tipo de comunicación:
- Sincrónica y transitoria
- Sincrónica y persistente
- Asincrónica y transitoria
- Asincrónica y persistente
Respuesta
- Sincrónica y transitoria: llamadas telefónicas (?)
- Sincrónica y persistente: RPC + sistemas de mensajería persistentes (RabbitMQ, Apache Kafka, etc.)
- Asincrónica y transitoria: UDP
- Asincrónica y persistente: aplicaciones de mensajería (WhatsApp, Telegram, etc.)
Ejercicio 4
Con qué tipo de comunicación diseñaría los siguientes sistemas:
- Trading financiero
- Home banking
- Uber
Explicar su decisión.
Respuesta
- Trading financiero: sincrónico y persistente
- Es necesario que se reintente de manera idempotente (con IDs únicos para evitar operaciones duplicadas) porque estamos hablando de un caso que involucra transacciones con dinero.
- Justamente como tiene que ser transaccional, tengo que poder hacer todo "del tirón" para evitar problemas de consistencia en los balances de las cuentas
- Sería sincrónico por el simple hecho de que tengo que estar esperando la respuesta de si mi transacción fue exitosa o no.
- Home banking: sincrónico y persistente
- Misma justificación que el trading
- Whatsapp: asincrónico y persistente
- Lo mencionamos en puntos anteriores, pero mismo se ve en los casos de usos diarios en WhatsApp
- Me pueden llegar mensajes en background y yo no me entero hasta que establezco una conexión lo suficientemente estable como para recibirlos
- Mismo puedo enviar mensajes que no le terminan de llegar al destinatario/no se terminan de enviar por esas cuestiones de red, pero cuando establezca una conexión estable se procesará dicho envío
- Es necesario para poder asegurar esa consistencia que WhatsApp ofrece
- Uber: asincrónico y persistente
- Misma justificación que WhatsApp pero trasladado a poder ver la ubicación del Uber una vez reabro la aplicación
- Por ahí no quiero estar pendiente constantemente de que el Uber se está moviendo y me quedo haciendo otra cosa con el teléfono (mandarle un mensaje a un amigo, por ejemplo).
- La ubicación del Uber se va a seguir actualizando en background/con la aplicación cerrada, y yo me entero recién cuando vuelvo a entrar. Mi pedido no se cancela si la cierro/pongo en 2do plano.
- Para esto es necesario que sea un esquema asincrónico y persistente.
Guía Coordinación
Relojes lógicos
Ejercicio 1
Explicar por qué los relojes de distintos procesos se desincronizan en un sistema distribuido.
Respuesta
De por sí, cada máquina tiene su propio reloj de hardware con un cuarzo que oscila a una cierta frecuencia, pero tiene su propio sesgo. Esto implica que, por más que 2 relojes iguales arranquen al mismo tiempo, se van a desfasar eventualmente.
Sumado a eso, al querer sincronizarlos con un protocolo como NTP, tenés latencia para comunicarte con el "servidor central que tiene la hora real", por lo que tenés que calcular un cierto offset y, nuevamente, podés caer en otro desfasaje.
Ejercicio 2
Describir los problemas que puede generar esta desincronización en:
- Orden de eventos
- Registro de logs
- Coordinación de acceso a recursos
Respuesta
- Orden de eventos: justamente se puede desencadenar en perder el orden de los eventos entre los procesos que participan en un sistema distribuido, generando inconsistencias en los resultados obtenidos.
- Registro de logs: se puede perder la trazabilidad de los eventos, asegurando que 2 eventos que deberían precederse sucedieron a la misma hora, lo cual debería ser imposible.
- Coordinación de acceso a recursos: pueden haber condiciones de carrera en lo que a los accesos a recursos refiere.
Ejercicio 3
Comparar Lamport clocks y vector clocks ¿Qué problema resuelven cada uno?
Respuesta
Lamport arregla el desfasaje y coordina los distintos relojes de todos los procesos que interactúan en un sistema. Se aseguran que el tiempo en todos los relojes sea correcto.
Los relojes de vectores ignoran por completo el tiempo y se concentran en la precedencia de los diferentes eventos, para poder determinar la causalidad de los eventos.
Exclusión Mutua
Ejercicio 1
Comparar los tres algoritmos de exclusión mutua vistos en clase:
- Centralizado
- Basado en token
- Ricart-Agrawala
Para cada algoritmo, analizar:
- Número de mensajes requeridos
- Tolerancia a fallas
- Latencia
Respuesta
- Centralizado
- Se basa en que todos los nodos que quieren un recurso le piden acceso al nodo dueño del mismo
- En principio, el número de mensajes es:
- 1 de solicitud de acceso por parte del solicitante
- 1 de respuesta por parte del dueño
- En caso de ser positiva, le manda un OK/ACK y le da el acceso al recurso al solicitante
- En caso de ser negativa, le dice "No bro, bancame"

- Depende cómo se piense/implemente, también puede estar el mensaje en el que el dueño le pregunta a quien tiene el acceso al recurso si ya terminó de usarlo.
- Otra variante de este es que quien tiene el acceso lo devuelva apenas termina.
- Entonces, decimos que es
- En lo que a tolerancia a fallas refiere, es baja, dado que se genera un SPoF
- La latencia debería ser baja porque la conexión es directa, es 1-1. Solicitante sólo se comunica con el dueño.
- Token-based
- Hay un token dando vueltas y se va pasando de mano para determinar quién puede operar.
- El número de mensajes es , siendo N la cantidad de nodos.
- Si tengo 10 nodos (del 0 al 9 y suponiendo que los punteros son ), el nodo 0 quiere un recurso y lo tiene el nodo 9 (peor caso), el token tiene que dar toda la vuelta.
- 0 pide el token, le pregunta a 1, no lo tiene; 1 le pregunta a 2, no lo tiene... así hasta llegar al 9, que lo tiene, e inmediatamente se lo pasa al 0.
- Contando, llegamos
- La tolerancia a fallas es baja, puesto que si se pierde el token hay que regenerarlo, y es difícil tanto de regenerar como de determinar quién lo tiene que tener al regenerarse.
- La latencia es alta, puesto que potencialmente se tiene que pasar por todos los nodos.
- El número de mensajes es , siendo N la cantidad de nodos.
- Hay un token dando vueltas y se va pasando de mano para determinar quién puede operar.
- Ricart-Agrawala
- Acá la movida es que cuando un proceso quiere acceder a un recurso, le manda un mensaje a todos los nodos (incluyéndose a sí mismo) diciendo "che, quiero el recurso en tal momento (timestamp)".
- Cada nodo que recibe el mensaje tiene tres opciones:
- Si no le interesa el recurso, responde OK de una.
- Si ya está usando el recurso, encola el pedido y no responde nada hasta que lo libere.
- Si también quiere el recurso pero todavía no lo tiene, compara timestamps: el que tenga el timestamp más chico (o, en caso de empate, el ID más bajo) gana. Si el mensaje entrante gana, responde OK; si no, lo encola.
- El proceso recién puede acceder al recurso cuando recibió OK de todos los otros nodos.
- En cuanto a número de mensajes, es bastante hablador: para cada acceso, cada proceso manda mensajes de pedido y recibe OKs, así que son mensajes por acceso (sin contar los reintentos si hay empates o caídas).
- Tolerancia a fallas: es baja, porque si un nodo se cae y no responde, el resto se queda esperando el OK y nadie accede al recurso. O sea, un nodo caído puede trabar todo el sistema.
- Latencia: depende de la velocidad de respuesta de todos los nodos, pero en el mejor caso es baja porque apenas llegan los OKs ya podés entrar. En el peor caso, si hay muchos compitiendo o alguno lento, se puede hacer eterna la espera.
Algoritmos de elección
Ejercicio 1
Imagine un sistema de 7 nodos que eligen al coordinador usando un algoritmo bully. El nodo 7 deja de funcionar y tanto el nodo 1 y el 4 detectan en simultáneo esta situación. Listar todos los mensajes necesarios para encontrar al nuevo nodo coordinador.
Respuesta
Aclaraciones:
- va a ser el proceso que siga los mensajes que se disparan a partir de que 1 detectó que se cayó 7, y va a seguir a 4.
- y se ejecutarán en paralelo
-
- 1 le manda mensaje a 2 2 le responde OK.
- 1 le manda mensaje a 3 3 le responde OK.
- 1 le manda mensaje a 4 4 le responde OK.
- 1 le manda mensaje a 5 5 le responde OK.
- 1 le manda mensaje a 6 6 le responde OK.
- 1 deja de enviar mensajes.
- 2 le manda mensaje a 3 3 le responde OK.
- 2 le manda mensaje a 4 4 le responde OK.
- 2 le manda mensaje a 5 5 le responde OK.
- 2 le manda mensaje a 6 6 le responde OK.
- 2 deja de enviar mensajes.
- 3 le manda mensaje a 4 4 le responde OK.
- 3 le manda mensaje a 5 5 le responde OK.
- 3 le manda mensaje a 6 6 le responde OK.
- 3 deja de enviar mensajes.
- 4 le manda mensaje a 5 5 le responde OK.
- 4 le manda mensaje a 6 6 le responde OK.
- 4 deja de enviar mensajes.
- 5 le manda mensaje a 6 6 le responde OK.
- 5 deja de enviar mensajes.
- 6 es el nuevo coordinador finaliza la elección.
-
- 4 le manda mensaje a 5 5 le responde OK.
- 4 le manda mensaje a 6 6 le responde OK.
- 4 deja de enviar mensajes.
- 5 le manda mensaje a 6 6 le responde OK.
- 5 deja de enviar mensajes.
- 6 es el nuevo coordinador finaliza la elección.
Ejercicio 2
Explicar por qué la detección de fallos (saber si un coordinador realmente cayó o solo está lento) es un problema difícil en sistemas distribuidos. ¿Qué se sacrifica si queremos siempre un coordinador disponible?
Respuesta
El querer detectar fallos en un sistema distribuido es difícil por el simple hecho de que, en principio, implicaría que todos los nodos se conozcan entre todos y que se comuniquen entre sí para poder determinar el estado del sistema.
Si se lo quiere pensar como un grafo, se requeriría tener un grafo completo no dirigido de conexiones. Si es la cantidad de nodos, requeriría conexiones/vías de comunicación distintas, lo cual resultaría muy costoso.
Dicho eso, podemos decir que, si queremos un coordinador disponible siempre, tenemos que sacrificar el rendimiento del sistema, teniendo una latencia alta.
Ejercicio 3
Comparar el algoritmo de elección de coordinador basado en anillos con el algoritmo bully: ¿qué diferencias hay en número de mensajes y tolerancia a fallas?
- Basado en anillos: un nodo detecta que se cayó el coordinador y inicia una votación, pasando un arreglo con su ID. Pega la vuelta con cada uno appendeando su ID al arreglo y, cuando vuelve a quien arrancó la votación, este comparte un mensaje con el ID del coordinador (el más grande).
- Número de mensajes: El caso normal implica mensajes por cada votación.
- El peor de los casos, en cambio, es en el cual todos los nodos (salvo el que se cayó, claramente) detectan que se cayó el coordinador. Por ende, se requerirían mensajes.
- Tolerancia a fallas: es alta por el hecho de que si se cae un nodo y no le responde, se le envía el mensaje de elección al próximo proceso que esté funcionando dentro del anillo. Si se cae el nodo que había salido ganador en el último mensaje (caso más borde), se reinicia la votación.
- Número de mensajes: El caso normal implica mensajes por cada votación.
- Bully: le pregunto siempre a los nodos más grandes. Si no me responden gano la elección.
- Número de mensajes: suponiendo el peor caso en el que tengo N nodos (del 0 a ) y la votación arranca desde 0, voy a tener:
- 0 le manda a y todos le responden, implicando mensajes
- 1 le manda a y todos le responden, implicando mensajes
- 2 le manda a y todos le responden, implicando mensajes
- 3 le manda a y todos le responden, implicando mensajes
- ...
- le manda a y todos le responden, implicando 2 mensajes
- Con una cierta ecuación de recurrencia obtenida a partir de esta deducción, obtenemos que se define como:
- Que, simplificando en una sola fórmula, sería
- Tolerancia a fallas: es alta, por lo que dijimos antes. Si se cae un nodo coordinador, arranca una nueva votación y se define otro coordinador.
- Si entra un nuevo nodo con ID más alto que el coordinador actual, se vota de vuelta.
- Número de mensajes: suponiendo el peor caso en el que tengo N nodos (del 0 a ) y la votación arranca desde 0, voy a tener:
Precedencia de eventos
Ejercicio 1
Dadas las siguientes marcas de tiempo vectorial de tres eventos distintos:
- Evento A: [2,1,0]
- Evento B: [1,2,0]
- Evento C: [2,2,1]
Responder y justificar:
- ¿A y B son concurrentes, o uno precede al otro?
- ¿Cuál es la relación entre C y A?
- ¿Cuál es la relación entre C y B?
Respuesta
Aclaración: las posiciones de los vectores de cada evento se definen como , siendo X el nombre del evento e i el índice del mismo (para simplicidad lo vamos a hacer 0-based, siendo las posiciones posibles en este caso 0, 1 y 2)
- ¿A y B son concurrentes, o uno precede al otro?
- A y B son concurrentes, porque . No hay forma de determinar si uno ocurrió antes que el otro, por lo que decimos que son concurrentes.
- ¿Cuál es la relación entre C y A?
- A es precedente de C y también puede ser causa, puesto que
- ¿Cuál es la relación entre C y B?
- B es precedente de C y también puede ser causa, puesto que
Si un evento A precede a otro evento B, decimos que puede ser causa, pero no asegurarlo porque no tenemos ninguna garantía de ello.
Que sea precedente quiere decir que pasa antes, nada más.
Guía Naming
Ejercicio 1
Escribir un ejemplo en donde la dirección de una entidad E necesita resolverse dentro de otra dirección para acceder en realidad a E.
Respuesta
Un ejemplo clásico es el acceso a una página web a través de un nombre de dominio, como www.ejemplo.com. El nombre de dominio se resuelve primero en una dirección IP mediante el sistema DNS (Domain Name System). Sin embargo, para realmente entregar la información al usuario, esa dirección IP muchas veces corresponde a un servidor de balanceo de carga (load balancer). El load balancer recibe la solicitud y la redirige internamente a la dirección de uno de los servidores reales donde efectivamente está alojado el recurso E que queremos acceder. Es decir, la resolución del nombre pasa por varias etapas de direcciones hasta llegar a la entidad final.
Otro ejemplo similar es el acceso a un servicio con alta disponibilidad en una red empresarial, donde el acceso se realiza mediante una IP virtual (VIP). Cuando un cliente accede a esa VIP, la dirección se resuelve dinámicamente (por ARP o mediante un software de clustering) al nodo físico que actualmente está activo y puede ofrecer el servicio, ocultando así las direcciones reales de los nodos detrás de una dirección virtual.
Ejercicio 2
En general, ¿cuál es la diferencia en la manera en que se implementan los nombres en sistemas distribuidos y no distribuidos?
Respuesta
Los sistemas distribuidos resuelven los nombres de manera distribuida (valga la redundancia) en múltiples máquinas, mientras que en los no distribuidos los nombres está centralizados en un nodo.
Ejercicio 3
Si no se cuenta con un sistema de nombres, ¿qué ocurre si una entidad ofrece más de un punto de acceso?
Respuesta
El sistema no sabe qué dirección usar como referencia
Ejercicio 4
¿En qué se diferencian el sistema de direccionamiento plano (Flat Naming System) y el sistema de direccionamiento estructurado (Structured Naming System)?
Respuesta
Difieren en los siguientes puntos:
| Característica | Flat Naming | Structured Naming |
|---|---|---|
| Estructura | Plano | Jerárquico |
| Escalabilidad | Local | Global |
| Legibilidad | Para máquinas | Para humanos |
| Resolución | Broadcasting | Consultas distribuidas |
| Uso | Redes P2P | Internet / Redes organizacionales |
Ejercicio 5
En la solución de difusión por broadcast para Flat Naming System:
a. ¿En qué capa del Modelo de referencia OSI operaría? b. ¿Qué limitaciones tiene? c. ¿Cuál es el protocolo más comúnmente utilizado para la difusión por Broadcast en Flat Naming System?
Respuesta
a. Opera en la capa de enlace, puesto que usa direcciones MAC.
b.
- Limitado a redes locales: No puede escalar más allá de las redes de área local (LAN)
- No atraviesa routers: Los routers no reenvían broadcasts, por lo que queda confinado a un segmento de red
- Requiere que todos los procesos escuchen: Todos los dispositivos en la red deben estar escuchando las solicitudes de ubicación entrantes
- Tráfico de red excesivo: Genera mucho tráfico de red al difundir a todos los dispositivos
- Escalabilidad limitada: No es viable para redes grandes o distribuidas geográficamente
c.ARP (Address Resolution Protocol)
Ejercicio 6
De acuerdo al protocolo, ¿Cómo se sabe que dirección MAC está asociada con una dirección IP?
Respuesta
Porque le pregunta uno por uno a cada dispositivo de la red.
Ejercicio 7
De acuerdo al sistema de nombres estructurado, ¿Cómo se denomina el mecanismo para saber cómo y dónde comenzar la resolución de nombres?
Respuesta
Se llama Mecanismo de clasura.
Ejercicio 8
Realizar, en grupo, el laboratorio guiado de ARP con Packet Tracer hasta la parte 2, paso 1.
Packet Tracer: Revisión de la tabla ARP
Tabla de asignación de direcciones
| Dispositivo | Interfaz | Dirección MAC | Interfaz del switch |
|---|---|---|---|
| Router0 | Gg0/0 | 0001.6458.2501 | G0/1 |
| Router0 | S0/0/0 | N/A | N/A |
| Router1 | G0/0 | 00E0.F7B1.8901 | G0/1 |
| Router1 | S0/0/0 | N/A | N/A |
| 10.10.10.2 | Inalámbrica | 0060.2F84.4AB6 | F0/2 |
| 10.10.10.3 | Inalámbrica | 0060.4706.572B | F0/2 |
| 172.16.31.2 | F0 | 000C.85CC.1DA7 | F0/1 |
| 172.16.31.3 | F0 | 0060.7036.2849 | F0/2 |
| 172.16.31.4 | G0 | 0002.1640.8D75 | F0/3 |
Objetivos
Parte 1: Examine una solicitud de ARP
Partee 2: Examine una tabla de direcciones MAC del switch
Parte 3: Examine el proceso ARP en Comunicaciones remotas
Aspectos básicos Esta actividad está optimizada para la visualización de PDU. Los dispositivos ya están configurados. Recopilará información de la PDU en modo de simulación y contestará una serie de preguntas sobre los datos que recopila.
Instrucciones Parte 1: Examine una solicitud de ARP Paso 1: Genere solicitudes de ARP haciendo ping a 172.16.31.3 desde 172.16.31.2. Abra un símbolo del sistema.
a. Haga clic en 172.16.31.2 y abra el símbolo del sistema.
b. Introduzca el comando arp -d para borrar la tabla ARP.
Cierre símbolo del sistema
c. Ingrese al modo Simulation e introduzca el comando ping 172.16.31.3. Se generan dos PDU. El comando ping no puede completar el paquete ICMP sin conocer la dirección MAC del destino. Entonces, la computadora envía una trama de difusión ARP para encontrar la dirección MAC del destino.
d. Haga clic en Capture/Forward una vez. La PDU ARP mueve el Switch1 mientras la PDU ICMP desaparece, esperando la respuesta de ARP. Abra la PDU y registre la dirección MAC de destino.
Pregunta:
¿Esta dirección aparece en la tabla de arriba? No, es 0000.0000.0000.
Pregunta: ¿Cuántas copias de la PDU hizo Switch 1? 3 copias, una para cada dirección dentro de la tabla.
¿Cuál es la dirección IP del dispositivo que aceptó la PDU? 172.16.31.3
e. Abra la PDU y examine la capa 2.
Pregunta: ¿Qué pasó con las direcciones MAC de origen y destino? La de origen es la de la terminal 172.16.31.2, y la de destino es la de broadcast.
f. Haga clic en Capture/Forward hasta que la PDU regrese a 172.16.31.2.
Pregunta: ¿Cuántas copias de la PDU realizó el switch durante la respuesta ARP? Hizo 5 copias.
Paso 2: Examine la tabla ARP. a. Tome en cuenta que el paquete ICMP vuelve a aparecer. Abra la PDU y examine las direcciones MAC.
Pregunta: ¿Las direcciones MAC del origen y el destino se alinean con sus direcciones IP? Sí.
b. Regrese a Realtime y se completa el ping.
c. Haga clic en 172.16.31.2 e ingrese el comando arp –a.
Pregunta: ¿A qué dirección IP corresponde la entrada de la dirección MAC? 172.16.13.3, la que buscábamos.
En general, ¿cuándo emite una terminal una solicitud de ARP? Cuando no tiene la dirección de destino en su tabla de ARP.
Parte 2: Examine en un switch la tabla de direcciones MAC Paso 1: Genere tráfico adicional para llenar la tabla de direcciones MAC del switch. Abra un símbolo del sistema.
a. Desde 172.16.31.2, introduzca el comando 172.16.31.4.
b. Haga clic en 10.10.10.2 y abra el símbolo del sistema..
c. Ingrese el comando ping 10.10.10.3.
Pregunta: ¿Cuántas respuestas fueron enviadas y recibidas? Tanto en el primer caso como en el segundo, 4 y 4.
Cierre símbolo del sistema
Paso 2: Examine la tabla de direcciones MAC en los switches. a. Haga clic en Switch1y luego en la pestaña de CLI. Introduzca el comando show mac-address-table .
Pregunta: ¿Las entradas corresponden a las de la tabla de arriba? Sí, a cada terminal conectada a ese switch.
b. Hag clic en elSwitch0, y luego en la pestaña de CLI. Introduzca el comando show mac-address-table.
Preguntas: ¿Las entradas corresponden a las de la tabla de arriba? Sí, a las 2 terminales inalámbricas y al Router.
¿Por qué hay dos direcciones MAC asociadas a un puerto? Porque es el puerto del Access Point.
Parte 3: Examine el proceso ARP en Comunicaciones Remotas Paso 1: Generar tráfico para producir tráfico ARP. Abra un símbolo del sistema.
a. Haga clic en 172.16.31.2 y abra el símbolo del sistema.
b. Ingrese el comando ping 10.10.10.1.
c. Type arp –a.
Pregunta: ¿Cuál es la dirección IP de la nueva entrada de la tabla ARP? 172.16.13.1
d. Ingrese arp -d para borrar la tabla ARP y cambie al modo de Simulation.
e. Repita el ping a 10.10.10.1.
Pregunta: ¿Cuántas PDU aparecen? 7
Cierre símbolo del sistema
f. Haga clic en Capture/Forward. Haga clic en la PDU que ahora se encuentra en el Switch1.
Pregunta: ¿Cuál es la dirección IP de destino de destino de la solicitud ARP? 172.16.13.1
g. La dirección IP de destino no es 10.10.10.1.
Pregunta: ¿Por qué? Porque 10.10.10.1 está en otra red. ARP solo se usa en la red local, así que el host resuelve la MAC del gateway por defecto (172.16.13.1) y le envía allí el paquete hacia 10.10.10.1.
Paso 2: Examine la tabla ARP en el Router1. a. Cambie al modo Realtime. Haga clic enRouter1 y luego en la pestaña de CLI .
b. Ingrese al modo EXEC privilegiado y luego al comando show mac-address-table.
Pregunta: ¿Cuántas direcciones MAC hay en la tabla? ¿Por qué? Ninguna, porque el Router solo guarda direcciones IP, no MAC.
c. Introduzca el comando show arp.
Preguntas: ¿Existe una entrada para 172.16.31.2? Sí
¿Qué sucede con el primer ping en una situación en la que el router responde a la solicitud de ARP? No tengo ni idea
Guía Consistencia y Replicación
Ejercicio 1
¿Por qué replicar?
Respuesta
Para aumentar la confiabilidad del sistema (ej: replicas un servicio, cosa de que si se cae, el sistema sigue funcionando porque lo reemplazas por su réplica), o para aumentar su rendimiento (ej: replicas un servicio y usas un Load Balancer cosa de que si se llena la instancia principal, redirigis el tráfico a la réplica, pudiendo atender más solicitudes).
Ejercicio 2
¿Qué problema puede ocurrir cuando se tienen múltiples copias?
Respuesta
Yace el problema inherente de mantener la consistencia de las copias, y la coherencia entre las mismas, justamente.
Ejercicio 3
¿Existe alguna relación entre la replicación y la escalabilidad? Explicar.
Respuesta
Colocar copias de datos cerca de los procesos que los usan puede mejorar el rendimiento mediante la reducción del tiempo de acceso. Y entonces se resuelven problemas de escalabilidad.
Sumado a eso, mantener varias copias consistentes puede estar sujeto a problemas de escalabilidad. Entre más copias quiero mantener, más complicado se vuelve mantenerlas consistentes.
Ejercicio 4
Defina brevemente qué es un modelo de consistencia.
Respuesta
Es un contrato entre los procesos y el almacén de datos. Son las "normas" que se van a respetar entre los procesos y el data store para asegurar un cierto tipo de consistencia
Ejercicio 5
En general, ¿en qué se diferencian los modelos de consistencia centrados en datos de aquellos modelos de consistencia centrados en el cliente?
Respuesta
La consistencia centrada en datos intenta mantener la consistencia de todo el sistema para todos los clientes por igual, es decir, la consistencia de todos los datos, mientras que la centrada en el cliente trata de que el cliente que consulta el data store vea algo consistente para él, no importa si para otros clientes es inconsistente.
Ejercicio 6
Actividad no obligatoria:
Actividad de tutorial guiado para el desarrollo de un smart contract en Ethereum “Pet Shop Tutorial”.
- Ingresar al siguiente link, el cual tiene las instrucciones para seguir el tutorial para desarrollar tu primer “Smart Contract” en Ethereum:
- En este tutorial guiado, encontrarás las herramientas: node, git, ganache y los comandos node para descargar el box “pet shop tutorial” con la estructura de directorio lista para empezar a programar.
- Te dejamos los siguientes links que también están en el tutorial guiado, para instalar las herramientas. Si ya tenés node y git instalados, no necesitás instalarlos otra vez.
- Node
- GIT
- Ganache
- Sirve para crear una Blockchain Ethereum interna (solo para desarrollo local y pruebas)
- Realizá el tutorial solo hasta el testing del smart contract en Ethereum. Corré los test, y observá los resultados en Ganache
Respuesta
Guía Tolerancia
Métricas de Disponibilidad y Confiabilidad
Ejercicio 1
Explique la diferencia fundamental entre los conceptos de Availability y Reliability.
A continuación, ilustre estas diferencias proporcionando un ejemplo claro de un sistema o situación de la vida real para cada una de las siguientes combinaciones y justifique:
a) High Reliability and High Availability b) High Reliability and Low Availability
Para el B:(Un ejemplo análogo podría ser un auto de Fórmula 1: Durante la carrera debe ser súper confiable y rendir bien. Pero al término de la carrera puede que tenga que estar en el taller durante un tiempo, lo que produce una baja disponibilidad.)
c) Low Reliability and High Availability d) Low Reliability and Low Availability
Respuesta
a) High Reliability & High Availability: los sistemas informáticos de los hospitales, por ejemplo. Es necesario que estén todo el tiempo disponibles y que los fallos sean mínimos (o que estén bien mitigados), son sensibles. b) High Reliability and Low Availability: sistema bancario. Pueden clavarte un mantenimiento entre las 00:00 y las 03:00 y no pasa natalia. c) Low Reliability and High Availability: como protocolo, UDP en sí mismo respeta estas características; como sistema, un juego en beta/alfa que revienta todo el tiempo, pero está disponible todo el tiempo.
- También el viejo sistema de compra de dólares de la AFIP era poco confiable: lo bajaban cuando querían
- Disponibilidad: Cuánto tiempo digo que voy a estar disponible
- Fiabilidad (reliability): Qué porcentaje del tiempo que digo que voy a estar disponible realmente estoy disponible
d) Low Reliability and Low Availability: el TP1, corre en nuestra máquina, andá a saber qué pasa si hay un fallo, etc.
Ejercicio 2
Durante el último Cyber Monday, el sistema de venta de merchandising de la Universidad Austral tuvo las siguientes caídas. Calcular MTTF, MTTR y MTBF:
| Hora caída | Hora recuperación | Tiempo indisponible |
|---|---|---|
| 08:00 am | 08:30 am | 30 min |
| 10:30 am | 11:30 am | 1 hora |
| 16:15 pm | 16:30 pm | 15 min |
Respuesta
Datos del problema:
- 3 fallos durante el Cyber Monday
- Tiempos de indisponibilidad: 30 min, 60 min, 15 min
Cálculos:
1. MTTR (Mean Time To Repair) - Tiempo promedio de reparación:
2. MTTF (Mean Time To Failure) - Tiempo promedio entre fallos:
Para calcular MTTF, necesitamos el tiempo total de operación y el número de fallos.
Asumiendo que el sistema operó desde las 00:00 hasta las 24:00 (24 horas = 1440 minutos):
- Tiempo total de indisponibilidad = 30 + 60 + 15 = 105 minutos
- Tiempo total de operación = 1440 - 105 = 1335 minutos
- Número de fallos = 3
3. MTBF (Mean Time Between Failures) - Tiempo promedio entre fallos:
Resumen:
- MTTR: 35 minutos
- MTTF: 445 minutos (7h 25min)
- MTBF: 480 minutos (8h)
Disponibilidad del sistema durante el Cyber Monday:
Ejercicio 3
Tengo un sistema que recibe un tráfico de 100.000 RPM (requests per minute).
¿Cuántos requests podrían quedar sin respuesta o recibir un status code 5xx para asegurar un uptime del 99,99% durante el lapso de 1 minuto?
Respuesta
Esto es hacer una regla de 3 simple:
Si el de las requests que me llegan por minuto son , si quiero un uptime del necesito:
Entonces, la respuesta es que puedo dejar 10 solicitudes sin respuesta por minuto.
Redundancia
Ejercicio 4
Manejo de fallos mediante Redundancia.
Busque un ejemplo para cada uno de los 3 tipos de redundancia (Información, tiempo y física) que se utilicen en sistemas reales y especifique dicho sistema.
Respuesta
Según el material de la materia, existen 3 tipos de redundancia para el manejo de fallos:
- Redundancia de información: Se añade información redundante (p. ej. códigos de detección o corrección de errores, como en TCP)
- Redundancia de tiempo: Se realiza una acción varias veces (p. ej. retransmisión de mensajes)
- Redundancia física: Se usan componentes duplicados (p. ej. replicación de procesos o datos)
Ejemplos reales (en tabla):
| Tipo de Redundancia | Sistema / Ejemplo | Mecanismo | Funcionamiento/Descripción | Aplicación |
|---|---|---|---|---|
| Redundancia de Información | Protocolo TCP (Transmission Control Protocol) | Checksums y códigos de corrección de errores | TCP incluye un checksum de 16 bits en cada segmento; si no coincide, se detecta error y se pide retransmisión | Comunicaciones de internet (HTTP, HTTPS, FTP, etc.) |
| Redundancia de Información | Sistemas de almacenamiento RAID (RAID 5/6) | Paridad distribuida y códigos de corrección | RAID 5/6 almacena información de paridad y permite reconstruir datos perdidos si un disco falla | Servidores empresariales y centros de datos |
| Redundancia de Tiempo | Protocolo TCP - Retransmisión de paquetes | Timeout y retransmisión automática | Si no se recibe ACK en un tiempo, se retransmite el paquete automáticamente | Todas las comunicaciones TCP |
| Redundancia de Tiempo | Bases de datos - Transacciones con reintentos | Retry logic, circuit breakers | Si una transacción falla por timeout/error temporal, se reintenta automáticamente (ej: DynamoDB reintenta hasta 3 veces) | Bases de datos distribuidas (DynamoDB, Cassandra…) |
| Redundancia Física | Google Search - Clusters de servidores | Múltiples servidores detrás de load balancer | Si un servidor falla, el balancer redirige el tráfico automáticamente a servidores sanos | Google, YouTube, Gmail |
| Redundancia Física | Amazon Web Services (AWS) - Multi-AZ deployments | Réplicas de bases de datos en varias zonas | Datos replicados entre zonas de disponibilidad; si una falla, se usa la réplica (ej: Amazon RDS promueve la réplica ante un fallo de zona) | Aplicaciones empresariales en AWS (Netflix, Airbnb) |
| Redundancia Física | Sistemas bancarios - Replicación de datos críticos | Múltiples copias en centros de datos | Cada transacción se escribe en múltiples réplicas antes de confirmarse (Visa/Mastercard mantiene réplicas en varios data centers) | Procesamiento de pagos con tarjetas de crédito |
Teorema de CAP
Ejercicio 5
Indique qué tipo de sistema son los siguientes (CP o AP) y justifique:
a) Youtube b) Home banking c) Feed de Instagram d) Red Bitcoin
Respuesta
a) Youtube: es del tipo AP, se prioriza la disponibilidad, lo que querés es poder servir los videos; si falla un frame o si se pierde en el camino medio que no te importa.
- Priorizas que el usuario pueda consumir el servicio b) Home banking: es del tipo CP, se prioriza tener un estado consistente; que si hago una transferencia esté en el mismo estado en todas las bases de datos
c) Feed de Instagram: es del tipo AP, lo que te importa es poder servir todos esos reels de brainrot ![]() , no te importa mucho que el feed sea en todos lados el mismo.
, no te importa mucho que el feed sea en todos lados el mismo.
- Querés verlo de manera inmediata, no te importa si está actualizado o si estás viendo el último estado real.
d) Red Bitcoin: es del tipo CP, se prioriza que toda la red esté en un estado consistente, que siempre muestres el último estado real de la red.
- Sabiendo que es un sistema que se basa en
Proof of Work, terminás esperando a que al menos el 51% de los bloques estén disponibles para ejecutar una transacción.
Resiliencia de Procesos
Ejercicio 6
En la resiliencia de procesos existen dos tipos de grupo.
Explique cuáles y qué ventajas y desventajas tiene cada uno.
Respuesta
Según lo visto en clase, hay 2 formas básicas de organizar grupos de procesos para lograr resiliencia:
-
Grupos sin coordinador (todos los procesos iguales):
- Descripción: Todos los procesos del grupo tienen el mismo rol (en lo que a jerarquía refiere) y toman decisiones de manera colectiva, por ejemplo, a través de votos o protocolos de consenso.
- Ventajas:
- No hay un único punto de falla, ya que todos los procesos pueden continuar incluso si algunos fallan.
- Potencialmente mayor disponibilidad y tolerancia a fallos.
- Desventajas:
- La coordinación suele ser más compleja, ya que todos deben ponerse de acuerdo.
- Puede requerir una mayor cantidad de mensajes y algoritmos más complejos para garantizar la coherencia.
- Mayor dificultad para escalar si el grupo es muy grande.
-
Grupos con coordinador (líder/trabajadores):
- Descripción: Uno de los procesos actúa como coordinador o líder, y los demás como trabajadores (ejemplo: modelo primary-backup, o sistemas como DNS).
- Ventajas:
- La toma de decisiones es simple y más rápida, ya que el coordinador centraliza la coordinación.
- Menor complejidad de sincronización: el líder determina la acción y los demás replican.
- Desventajas:
- Existe un único punto de falla: si el coordinador cae, hay que elegir uno nuevo (pudiendo haber brechas temporales en la disponibilidad).
- El coordinador puede ser cuello de botella si la carga crece mucho.
Resumen:
- Grupos “todos iguales” tienen mejor tolerancia a fallos y disponibilidad, pero son más difíciles de coordinar.
- Grupos con coordinador son más fáciles de manejar y más ágiles, pero arrastran el riesgo del SPoF.
Esto se usa según el tipo de aplicación, el número de procesos y el nivel de tolerancia a fallos requerido por el sistema distribuido.
Algoritmos de Consenso
Ejercicio 7
¿Por qué existen diferentes tipos de algoritmos de consenso?
¿Cuál es la problemática mayor?
¿Podemos conseguir consenso en un sistema asíncrono?
Respuesta
Existen diferentes tipos de algoritmos de consenso porque los sistemas distribuidos pueden enfrentarse a distintos modelos de fallo (fallos por caída, fallos arbitrarios/Byzantinos, fallos detectables, etc.), y cada uno de estos escenarios tiene requisitos y desafíos particulares. Además, varía el grado de tolerancia a fallos que se necesita, la cantidad de procesos, las garantías de rendimiento y el entorno de sincronía (sincrónico, parcialmente sincrónico o asíncrono).
La problemática mayor es cómo lograr que un conjunto de procesos, posiblemente afectados por fallos o mensajes retrasados/perdidos, se ponga de acuerdo en una única decisión (por ejemplo, una operación, un valor de estado o el siguiente bloque de una cadena), garantizando que todos los procesos correctos lleguen al mismo resultado incluso ante fallas. Esto se complica si hay fallos de comunicación, fallas arbitrarias (donde un proceso puede comportarse de manera maliciosa o impredecible), o si los procesos pueden funcionar a distintas velocidades.
Respecto a si podemos conseguir consenso en un sistema asíncrono: no es posible garantizar consenso en un sistema asíncrono puro si existe aunque sea un solo fallo de proceso. Esto es una limitación fundamental demostrada teóricamente (resultado de Fischer, Lynch y Paterson, "el teorema FLP"), porque en un entorno totalmente asíncrono no es posible diferenciar entre un proceso lento y uno caído. Por eso, los algoritmos prácticos suelen asumir algún nivel de sincronía (aunque sea eventual), o utilizan detección de fallos basada en timeouts y otras técnicas.
En resumen:
- Hay diferentes algoritmos de consenso porque los escenarios de fallo y requisitos varían mucho.
- El mayor desafío es coordinar decisiones correctas en presencia de fallos y comunicación incierta.
- En sistemas asíncronos puros no se puede lograr consenso tolerante a fallos; siempre se requieren algunas suposiciones de sincronía o mecanismos extra para avanzar.
Comunicación Cliente-Servidor
Ejercicio 8
Comunicación Cliente-Servidor Confiable
Indique en cuál de las siguientes opciones (consulta a otro microservicio) podría configurar un retry sin más preocupaciones y justifique:
a) Actualizar información del usuario como edad.
b) Obtener la geolocalización a partir de una IP.
c) Realizar pago de un pasaje de avión.
d) Eliminar usuario de la base de datos.
Respuesta
a) No hay problema, siempre estás escribiendo lo mismo.
El problema estaría en caso de que otro proceso quiera leer.
b) Es una operación de lectura, todo pelota
c) No se podría hacer un retry, es algo sensible, involucra plata. Te puede pasar que se concretó el pago pero en una operación posterior falló algo, podrías terminar pagando 2 veces
d) Sí, porque estoy targeteando un usuario en particular. Si el usuario ya se eliminó y reintento, como mucho la query va a fallar porque el usuario no existe más.
Multicast confiable
Ejercicio 9
Defina qué tipo de multicast necesitan cada uno de los siguientes sistemas y justifique:
a) Sistema de sensores que reportan lecturas (ej. temperatura, humedad) de cada una de los espacios de una oficina para poder armar un dashboard sobre la temperatura. Por ejemplo, la temperatura media de la oficina.
b) Un sistema bancario con varias réplicas de la base de datos que gestionan saldos de cuentas. Se envían operaciones como "TRANSFERIR $100 de A a B" y "DEPOSITAR $50 en A".
c) En una sala de chat de grupo, se pueden dar respuestas explícitas a mensajes (el mensaje de Carlos fue una respuesta explícita al mensaje de Horacio). Sin embargo, si dos mensajes no están relacionados, podrían aparecer en un orden diferente en distintas máquinas.
d) Un sistema de edición de documentos colaborativo en tiempo real (como Google Docs). Donde las modificaciones de un usuario pueden basarse en la que realiza otro usuario. Además, si hay dos ediciones concurrentes, se necesita que todas las réplicas del documento converjan al mismo estado final.
e) Un sistema de procesamiento de video con varios workers que van recibiendo tareas. Donde es importante que no se realice una tarea más de una vez. Por ejemplo: Un usuario A envía 1 “cargar video1.mp4” y luego “Transcode video1.mp4”. Al mismo tiempo, usuario 2 envía “Analizar audio video2.mp4”.
f) Un sistema de logging distribuido donde múltiples procesos envían entradas a un grupo de servidores de análisis. Para el usuario final, es fundamental ver los logs en el orden en que se va ejecutando el código en cada proceso.
Respuesta
a) Se puede usar el desordenado (o multicast confiable), por 2 razones:
- Son datos de temperatura, no son críticos
- Si sólo vas a calcular el promedio, el orden en el que te llegan no te importan
b) Acá el orden de las operaciones importa necesariamente; no es lo mismo primero depositar $50 y luego transferir $100 que hacerlo en orden distinto, puedo llegar a no tener saldo en el 2do caso. Por ende, es necesario un tipo de multicast atómico totalmente ordenado.
- Necesito que me llegue todo, todo el tiempo en el mismo orden
- Todas las réplicas de la base de datos deben mantener el mismo estado, la versión final de la BD debe tener la misma versión de los datos en cada réplica.
c) La propia pregunta de lo dice: necesitás multicast causalmente ordenado, no te importa el orden de los mensajes que no están explícitamente relacionados
d) Necesariamente debemos tener ordenamiento atómico, pero acá tanto FIFO como Causal pueden ir:
- Causal puede servir por el hecho de que, por ejemplo, el sistema puede interpretar que una persona escribió un pedazo de texto y luego otro lo modificó
- FIFO medio que se explica solo, modificas en el orden en el que van llegando los mensajes. Los cambios se van encolando.
- Este termina teniendo más sentido, porque la relación no es tan clara como en el caso anterior de los mensajes.
e) Se requiere un multicast ordenado, primordialmente FIFO Atomic.
- Causal no es tan necesario porque no necesariamente la carga del video te va a generar el
transcode
f) Es imperativo que estén ordenados para mantener trazabilidad, y lo ideal sería usar un ordenamiento FIFO atómico
- No se requiere tanto el causal puesto que un log no necesariamente dispara otro
Atomic es necesariamente Ordenado El causal puede estar desordenado, mientras quede clara la relación causal
Guía Seguridad
Protocolos y Herramientas de Seguridad
Ejercicio 1
¿Qué protocolos o herramientas de seguridad se pueden utilizar para superar los siguientes desafíos?
a. Garantizar la integridad del mensaje.
b. Autenticación mutua.
c. Suplantación de identidad.
d. Ataques de replicación.
e. Gestionar eficientemente las claves secretas compartidas en sistemas grandes.
f. Autenticidad de las claves públicas.
g. No revelar información sensible antes de la autenticación de las partes.
Respuesta
a. Garantizar la integridad del mensaje: comparar hashes
b. Autenticación mutua: challenge-response, KDC, criptografía de clave pública
c. Suplantación de identidad: MFA/2FA; tenés que tener alguna manera de asegurarle al sistema que sos vos.
d. Ataques de replicación: números de secuencia/nonce. Evito que el mensaje se pueda volver a enviar, o le doy una validez al mensaje. También se pueden usar claves de sesión, porque duran un tiempo limitado.
e. Gestionar eficientemente las claves secretas compartidas en sistemas grandes: KDC
f. Autenticidad de las claves públicas: se utiliza una infraestructura de clave pública (PKI) donde las claves públicas son firmadas por una autoridad certificadora (CA) confiable mediante certificados digitales. Así, los usuarios pueden verificar que una clave pública realmente pertenece a quien dice ser su dueño.
g. No revelar información sensible antes de la autenticación de las partes: autenticar primero, o también usar criptografía de clave pública.
- En esta última no te tenés que asegurar de que estas hablando con X, sino que directamente cifrás con su clave pública; lo va a poder descifrar esa persona y nadie más.
- Es débil ante ataques de suplantación de identidad
Claves de Sesión
Ejercicio 2
¿Por qué se usan claves de sesión? ¿Qué beneficios tiene?
Respuesta
Se usan solo durante el tiempo de vida del canal; cuando termina, se destruyen. Se usan en casos donde se quiere dar acceso durante un tiempo limitado a un recurso, tiempo después del cual es necesario volver a autenticarse.
Políticas de Acceso
Ejercicio 3
Identifique la política de acceso que aplica a cada escenario:
a. Un alumno crea un nuevo archivo con el informe de Física III. Por defecto, solo él puede leer y modificar el archivo. Decide otorgar permisos de lectura y escritura a todo su equipo y, además, da permiso de comentar a los profesores.
b. En un hospital, el acceso a los sistemas de información está estrictamente organizado. Un usuario con el perfil de "Médico" puede acceder a los historiales clínicos de los pacientes que tiene asignados, solicitar pruebas y ver sus resultados. Un usuario con el perfil de "Administrativo" puede acceder a la información de facturación de los pacientes y gestionar las citas, pero no puede ver los detalles clínicos del historial. Por último, un usuario con el perfil de "Director de Hospital" puede ver reportes estadísticos y de gestión, pero no tiene acceso a los historiales individuales de los pacientes.
c. En una agencia de seguridad nacional, todos los documentos y usuarios están clasificados con etiquetas de seguridad como "Público", "Confidencial", "Secreto" y "Top Secret". Un usuario con autorización "Secreto" puede acceder libremente a documentos clasificados como "Público" y "Confidencial", pero el sistema le denegará automáticamente el acceso a cualquier documento etiquetado como "Top Secret". Estas reglas son configuradas por un administrador central de seguridad y no pueden ser modificadas por los usuarios.
d. Una aplicación bancaria moderna implementa políticas de seguridad muy dinámicas. Por ejemplo, un cliente puede realizar transferencias de hasta 1.000 € desde su propia red Wi-Fi registrada y durante el horario diurno (9:00 a 20:00). Sin embargo, si el mismo cliente intenta realizar una transferencia de más de 500 € mientras está conectado a una red Wi-Fi pública en otro país, el sistema bloquea la operación y solicita una segunda forma de autenticación (ej. una llamada de confirmación). La política evalúa el rol del usuario (cliente), la ubicación, la seguridad de la red, la cantidad de la transacción y la hora del día antes de permitir o denegar la operación.
Respuesta
a. DAC b. RBAC c. MAC d. ABAC
Firewalls y Gateways
Ejercicio 4
¿Cuál es la principal diferencia entre un firewall de filtrado de paquetes y un gateway a nivel de aplicación? De un ejemplo de ambos.
Respuesta
La diferencia principal es el criterio de elección:
- El de filtrado de paquetes elige según el contenido de los headers o del paquete en sí mismo
- Ejemplo: un router que permite el tráfico HTTP por el puerto 80 para navegación web, pero bloquea el tráfico FTP por el puerto 21 para prevenir transferencias de archivos.
- El gateway a nivel de aplicación elige según el contenido del mensaje
- Ejemplo: Un proxy HTTP como Squid actúa como gateway a nivel de aplicación, inspeccionando el contenido de las solicitudes y respuestas HTTP. Por ejemplo, puede bloquear descargas de archivos ejecutables o filtrar contenido web específico según el texto presente en la página.
Sistemas de Detección de Intrusos
Ejercicio 5
Busque ejemplos reales de mecanismos de Detection Intrusion Para signature-based Intrusion Detection Systems y Anomaly-based Intrusion Detection Systems
Respuesta:
Signature-based Intrusion Detection Systems (IDS)
Los sistemas de detección basados en firmas identifican ataques conocidos comparando el tráfico de red o eventos del sistema con patrones predefinidos (firmas) de ataques conocidos.
Ejemplos reales:
-
Snort - Sistema de detección de intrusiones de código abierto más popular:
- Detecta ataques como SQL injection, buffer overflows, y malware
- Ejemplo de regla:
alert tcp any any -> any 80 (content:"GET /admin"; msg:"Admin access attempt";) - Usado por empresas como Cisco, Sourcefire
-
Suricata - Motor de detección de intrusiones de alto rendimiento:
- Detecta ataques DDoS, exploits, y malware
- Utilizado por organizaciones gubernamentales y empresas
- Soporte para protocolos como HTTP, DNS, TLS
-
OSSEC - Sistema de detección de intrusiones basado en host:
- Monitorea logs del sistema, integridad de archivos
- Detecta cambios no autorizados en archivos críticos
- Usado en servidores web y sistemas críticos
-
Cisco FirePOWER - Solución empresarial:
- Detecta malware, exploits, y ataques dirigidos
- Integración con firewalls Cisco
- Usado en redes corporativas grandes
Anomaly-based Intrusion Detection Systems (IDS)
Los sistemas de detección basados en anomalías identifican comportamientos inusuales comparando la actividad actual con un modelo de comportamiento "normal" establecido.
Ejemplos reales:
-
IBM QRadar - Plataforma de seguridad empresarial:
- Utiliza machine learning para detectar anomalías
- Detecta comportamientos inusuales en usuarios y sistemas
- Usado por bancos y organizaciones financieras
-
Splunk Enterprise Security - Plataforma SIEM:
- Análisis de comportamiento de usuarios (UEBA)
- Detecta accesos anómalos, transferencias de datos inusuales
- Usado por empresas Fortune 500
-
Darktrace - Inteligencia artificial para ciberseguridad:
- Utiliza machine learning para detectar amenazas internas
- Detecta comportamientos anómalos en tiempo real
- Usado por organizaciones gubernamentales y empresas
-
Vectra AI - Detección de amenazas en tiempo real:
- Análisis de comportamiento de red
- Detecta ataques avanzados persistentes (APT)
- Usado en infraestructuras críticas
-
Microsoft Defender for Identity - Protección de identidades:
- Detecta movimientos laterales y escalación de privilegios
- Análisis de comportamiento de usuarios
- Integrado en ecosistemas Microsoft
Diferencias clave:
- Signature-based: Efectivo contra ataques conocidos, bajo falso positivo, requiere actualizaciones constantes
- Anomaly-based: Detecta ataques desconocidos, puede generar falsos positivos, requiere entrenamiento inicial
TP 1 - Weather App
Existen servicios gratuitos de API para determinar locación a partir de una IP. También existen APIs gratuitas (con algunas limitaciones) para determinar el clima en función de una locación.
Tienen que desarrollar una aplicación a la que se le pueda pedir el clima, ya sea pasándole una IP o utilizando la IP de la request.
Para eso deben armar:
- Un servicio dedicado únicamente a determinar la locación en función de la IP, implementado en Python.
- Un servicio dedicado a determinar el clima en función de la locación, implementado en Python.
- Un servicio integrador o Gateway que coordinará los llamados a los otros servicios, implementado en JavaScript/TypeScript.
Los servicios se deben ejecutar con Docker Compose. Las interacciones entre servicios tienen que hacerse usando gRPC. Únicamente el Gateway debe exponer una API HTTP
Pasos lógicos:
- Paso la URL y le pido su IP a algún DNS, que es inherentemente distribuido.
- Resolver la región de esa IP.
- Una vez obtenida la región, devuelvo el tiempo en esa región.
Parcial 1 2024
-
En los sistemas distribuidos generalmente se consideran las capas del stack OSI:
- a. Capa de enlace
- b. Capa física
- c. Capa de red
- d. Capa de transporte/sesión/presentación y aplicación
Justificación:
-
El protocolo "Transmission Control Protocol" se usa en los S.D porque permite:
- a. Minimizar el número de paquetes que se envían por las redes
- b. Minimizar la latencia en las comunicaciones
- c. Disminuir los errores en las comunicaciones
- d. Garantizar la seguridad
Justificación:
-
Cuando se menciona que un middleware puede ser usado por muchas aplicaciones diferentes, esto implica:
- a. Los protocolos de la capa física no son necesarios.
- b. Tener la capacidad de poder usar/integrar distintos tipos de protocolos
- c. Las aplicaciones deben usar los mismos protocolos de comunicación
- d. Los sistemas donde se ejecutan esas aplicaciones tienen la misma capacidad y tipo
Justificación:
-
Cuando se trabaja con un protocolo
host-to-hostse establece una comunicación entre:- a. Distintos protocolos
- b. Distintas aplicaciones
- c. Sistemas operativos del mismo o diferentes tipos
- d. Middlewares
Justificación:
-
Una comunicación síncrona implica
- a. Establecer 3 momentos o etapas: envío, entrega y procesamiento
- b. Evitar la espera de la respuesta del servidor o del cliente
- c. Contar con sistemas de almacenamiento que registren el estado y datos de la comunicación
- d. Que las comunicaciones sean obligatoriamente persistentes
Justificación: "almacenamiento" no implica que haya persistencia de la comunicación. Puede quedar en memoria y luego esfumarse.
-
Para el esquema de comunicación cliente/servidor se establecen:
- a. Comunicaciones persistentes
- b. Comunicaciones síncronas
- c. Comunicaciones transitorias
- d. Bloqueos durante la comunicación de parte del cliente y no del servidor
Justificación: si bien son cosas típicas del modelo cliente/servidor, no necesariamente lo van a incluir siempre
-
Una comunicación persistente y asíncrona implica
- a. Gestión de colas de mensajes
- b. Dependencias de aplicaciones intermedias que aseguren la tolerancia a fallas
- c. Modelo Cliente/Servidor
- d. Bloqueo para espera de confirmación de envío o recepción
Justificación: No necesariamente tienen que asegurar la tolerancia a fallas, mucho menos ser parte del modelo cliente servidor. Puede haber un esquema Pub/Sub donde ningún nodo es un servidor, y las colas de mensajería administran los mensajes enviados en este tipo de comunicación. Como es asíncrona, no hay bloqueo por espera de confirmación de envío ni recepción
-
RPC involucra:
- a. Comunicación síncrona
- b. Sockets
- c. Gestión de conversión o adaptación de las funciones invocadas
- d. No se permite el uso de variables globales
Justificación: Permiten el uso de variables globales, justamente, teniendo referencias a objetos.
-
MPI involucra:
- a. Intercambio de objetos
- b. Gestión de MQ (colas de mensajes)
- c. Ejecución de tareas en varios cores y/o computadoras
- d. Comunicaciones síncronas o asíncronas
Justificación: MPI permite sincronización de tareas ejecutadas en varios dispositivos, pero no la ejecución en sí
-
Una comunicación asíncrona persistente incluye:
- a. Intercambio de mensajes
- b. Middlewares para la gestión de mensajes
- c. Buffers para la comunicación
- d. Operaciones básicas para el envío y recepción
Justificación: Si se quiere asincronismo y persistencia, necesariamente tiene que haber un buffer de comunicación, que puede ser interpretado de alguna manera como middleware. Las otras 2 son básicas de cualquier tipo de comunicación.
-
El intercambio de mensajes basado en brokers:
- a. Se usa para aplicaciones homogéneas
- b. Se usa en modelos Pub/Sub
- c. Se usa para aplicaciones heterogéneas
- d. La gestión de MQ se realiza en nodos que se comunican
Justificación: Los brokers siguen como capa de abstracción de alguna manera. Justamente las colas de mensajería son procesos/nodos aparte de los nodos que quieren comunicarse. Si la aplicación es homogénea, ¿para qué querés una cola de mensajería?
-
Para establecer un envío multicast:
- a. Solo se pueden usar arquitecturas de computadoras en forma de árbol
- b. Siempre se requiere un sistema de routing
- c. Es posible aumentar la latencia por saturación de los canales de comunicación
- d. Se necesita comunicación directa entre nodos
Justificación: No siempre tienen que ser arquitecturas en forma de árbol. El enrutamiento se requiere si la arquitectura es de tipo mesh
-
Un esquema de comunicación basado en flooding:
- a. Es más eficiente mientras más nodos contenga la red
- b. Siempre debe contener nodos edge
- c. El envío de mensajes se hace solo al nodo más cercano
- d. Se seleccionan los vecinos según el desempeño de la comunicación entre nodos
Justificación: Flooding toma un nodo, ese nodo le envía mensajes a todos sus vecinos excepto a quien le haya mandado el mensaje, lo cual está directamente relacionado con el desempeño de la red
-
Un sistema distribuido centralizado
- a. Usa varios nodos centrales para controlar las comunicaciones
- b. Usa una estructura en malla para establecer las comunicaciones
- c. No es un sistema distribuido
- d. La centralización se basa en la forma en cómo se estructura la red de comunicación
Justificación: No necesariamente van a usar varios nodos centrales, no es condición necesaria. La estructura en malla no tiene nada que ver. Justamente es un sistema distribuido.
-
¿Qué significa que un sistema distribuido es un sistema informático en red en el que los procesos y recursos están suficientemente distribuidos entre varias computadoras?
- a. Que todos los procesos pertenecen a diferentes computadoras
- b. Que todos los recursos están en diferentes computadoras
- c. Que algunos de los procesos y recursos están en diferentes computadoras o dispositivos
- d. Que una computadora ejecute un solo proceso o contenga un solo recurso
Justificación:
-
El escalamiento en un S.D depende de:
- a. Los protocolos de comunicación que se usen
- b. De las aplicaciones que se usen
- c. Del tipo de usuario que se considere
- d. De las APIs con las que se cuente
Justificación: Del tipo de usuario no depende en absoluto, pero sí de su cantidad. Es decir, la escala depende mucho del tráfico y uso del sistema.
-
La distribución lógica y física considera:
- a. La forma en que las organizaciones (individuos) participan
- b. Las aplicaciones utilizadas
- c. El tipo de red utilizado
- d. Los protocolos de comunicación
Justificación:
-
Cuando las aplicaciones son independientes a los algoritmos
- a. Se pueden usar diferentes arquitecturas de computadoras para el mismo algoritmo
- b. Todos los algoritmos son independientes a todas las aplicaciones
- c. Todas las aplicaciones son independientes de cualquier algoritmo
- d. Un algoritmo puede ser implementado en diferentes aplicaciones
Justificación:
-
La transparencia en la distribución implica:
- a. Tener un middleware
- b. Tener una sola aplicación que le permita al usuario integrar todos los recursos y procesos, en una única interfaz visual.
- c. Que el usuario no conozca los detalles de la forma en que se comunican los procesos
- d. Que el usuario administre cada recurso de forma transparente
Justificación:
-
Para distinguir entre la latencia y las fallas, se puede usar:
- a. El tiempo como única métrica de detección
- b. Protocolos que usen estrategias de confirmación de recepción de mensajes
- c. Un registro de los tiempos de respuesta
- d. Un tiempo máximo de espera
Justificación:
-
Entre las similitudes entre políticas y mecanismos están
- a. La política y el mecanismo proviene de una decisión organizacional
- b. La forma de implementación
- c. Se usan como conceptos análogos
- d. Ninguna de las anteriores
Justificación:
-
Cuando un S.D permite agregar dominios de forma transparente al usuario se está refiriendo a:
- a. Escalabilidad administrativa
- b. Escalabilidad geográfica
- c. Escalabilidad de procesos
- d. Todas las anteriores
Justificación:
-
Entre las semejanzas entre un S.D y uno paralelo están:
- a. Tener diferentes clocks
- b. Tener el mismo clock
- c. Tener múltiples procesadores o cores en una o varias computadoras
- d. Tener procesadores de alto rendimiento en todos los sistemas
Justificación: No necesariamente vas a tener procesadores de alto rendimiento. Podes tener un sistema distribuido o paralelo tomando tu máquina personal como nodo. Los S.D tienen distintos clocks, mientras que los paralelos lo comparten.
-
La memoria virtual sirve para:
- a. Implementar memoria compartida
- b. Extender la capacidad real de la memoria física
- c. Virtualizar el almacenamiento secundario
- d. Todas las anteriores
Justificación:
-
Un S.D local o clúster cuenta con:
- a. Un mismo clock para todos los nodos
- b. Un clock diferente para c/nodo
- c. Un nodo coordinador
- d. Distribución de datos y/o instrucciones
Justificación:
-
En un S.D se usa una arquitectura multicapa para:
- a. Disminuir la cantidad de protocolos de comunicación
- b. Descomponer el proceso de comunicación en tareas más simples
- c. Aumentar el grado de confiabilidad en las comunicaciones
- d. Tener un mejor control en el manejo de errores
Justificación: Justamente si tenés muchas capas podrías terminar teniendo varios protocolos de comunicación
-
En una arquitectura orientada o basada en objetos:
- a. Un objeto representa un solo nodo o computadora en el sistema
- b. Un dispositivo en el sistema puede manejar varios objetos
- c. La estrategia es distribuir las tareas entre objetos independientemente de los nodos del sistema
- d. Un objeto puede resolver una única tarea particular solamente
Justificación:
-
En una arquitectura REST se busca:
- a. Disminuir la cantidad de tipos de operaciones para facilitar la integración entre nodos en el sistema
- b. Los recursos son manejados y controlados de forma compartida
- c. Los recursos están distribuidos y se acceden a través de protocolos compatibles con REST
- d. Ninguna de las anteriores
Justificación: La idea es que los nodos de esta arquitectura se acoplen a una cierta interfaz, y que las operaciones a realizar se limiten a los distintos métodos de HTTP. No necesariamente los recursos van a estar manejados y controlados de manera compartida, puesto que puedo tener una arquitectura REST con 1 solo servidor y N clientes, donde los recursos los termina manejando solo el server. La 3ra opción es solo una implicancia de una arquitectura REST
-
En un S.D una interfaz permite
- a. Comunicación entre aplicaciones del mismo tipo
- b. Comunicación entre aplicaciones de distinto tipo
- c. Comunicación entre dispositivos iguales
- d. Comunicación entre dispositivos diferentes
Justificación: Justamente se ponen estos contratos para abstraerse tanto del tipo de aplicación como del tipo de dispositivo.
-
Entre las ventajas de tener un coordinador en un S.D están:
- a. Aumentar el control de la comunicación entre nodos
- b. Aumentar la seguridad del sistema
- c. Aumentar la coherencia de datos
- d. Evitar SPoFs (Single Points of Failure)
Justificación: Claramente provocás un SPoF. La comunicación está más controlada porque todo pasa por el coordinador, lo cual te da una arquitectura más robusta y más sencilla de implementar. Lo mismo aplica para la seguridad y la coherencia de datos (todo pasa por el coordinador)
-
En cuanto a un middleware, se puede afirmar:
- a. Que es un intermediario entre HW y SW.
- b. Que es un sistema compuesto por varias aplicaciones
- c. Que es un sistema que ofrece al usuario la capacidad de uso de diferentes sistemas operativos
- d. Todas las anteriores
Justificación: Lo de los sistema operativos es cierto en el caso del Hypervisor de las máquinas virtuales, el cual es un middleware entre el Host OS y las distintas VM. No necesariamente tiene que estar compuesto por varias apps, pero se puede implementar de esta manera.
-
Un wrapper siempre usa:
- a. Un nodo broker que intermedia entre aplicaciones que no están diseñadas para la comunicación entre nodos o dispositivos
- b. Un hardware o software intermediario entre aplicaciones que carecen de APIs para proveer interacción con otros nodos
- c. Una capa de software adicional que le permite a una aplicación interactuar con otra
- d. Una capa de hardware adicional que le permite a un nodo interactuar con otro
Justificación: Es un tipo de middleware que encapsula otro cacho de software/hardware y le agrega comportamiento, lo cual puede derivar en las opciones seleccionadas.
-
Un modelo cliente/servidor puede ser considerado como:
- a. Una arquitectura descentralizada
- b. Una arquitectura centralizada
- c. Un modelo diseñado para la comunicación entre varios nodos clientes y varias réplicas de un servidor.
- d. Un modelo diseñado para proveer servicios a varios nodos clientes
Nota: Esta es la única que me genera duda, porque en clase dijeron que no es una arquitectura descentralizada, ya que por definición el modelo cliente/servidor es centralizado, pero al Tiny le marcaron que es descentralizado
-
En cuanto a una arquitectura NFS:
- a. Se la puede considerar P2P
- b. Se puede considerar un modelo cliente/servidor de uso particular
- c. Se le puede considerar un modelo en capas
- d. Todas las anteriores
Justificación: Es un sistema de archivos en la red, no es P2P.
-
Un sistema P2P desestructurado se usa para:
- a. Conformar un anillo de comunicación entre nodos para tomar una decisión entre los mismos
- b. Seleccionar un nodo líder o coordinador
- c. Sincronizar el tiempo entre todos los nodos
- d. Todas las anteriores
Justificación:
-
Un sistema de Cloud Computing ofrece servicios:
- a. Orientados a Infraestructura
- b. Orientados a Middleware
- c. Orientados a Software
- d. Orientados a Plataforma
Justificación: Lo vimos en AWS pero no me acuerdo
-
Los sistemas edge:
- a. Son estructurados en forma de hipercubos o mallas
- b. El nivel de latencia es alto, el nivel de confiabilidad y seguridad es bajo
- c. Son estructurados en forma de anillo
- d. Ninguna de las anteriores
Justificación: La respuesta "b" no está comparando con nada, por lo que no se puede afirmar esto
-
Para un sistema basado en blockchain
- a. Se usan cadenas de bloques independientes y totalmente diferentes en varios nodos
- b. Procura mantener una sola versión válida de la cadena de bloques distribuida (replicada)
- c. Un nodo coordinador decide sobre la validez de los bloques en la cadena
- d. Se hacen réplicas de la cadena de bloques en diferentes nodos
Justificación:
-
Se puede afirmar que un proceso y un thread
- a. Pueden ejecutar un mismo programa
- b. Son conceptos totalmente separados
- c. Los threads representan varias ejecuciones de un mismo proceso
- d. Un proceso puede compartir sus recursos entre los threads del mismo proceso
Justificación:
-
Un S.D tiene entre sus objetivos principales
- a. Disminuir la latencia en la ejecución de un thread
- b. Aumentar el rendimiento de aplicaciones no paralelizables
- c. Mejorar la performance de la ejecución de tareas
- d. Aumentar la capacidad de cómputo y almacenamiento
Justificación: No tiene sentido hacer un sistema distribuido para aplicaciones no paralelizables. Tampoco tiene sentido disminuir la latencia de un thread puesto que la latencia es propia de la red.