Resumen de Programación Concurrente
Esta página, creada con mdbook, recopila las explicaciones y apuntes de los conceptos clave vistos en la materia de Programación Concurrente. A continuación se listan los temas principales. También puedes consultar ejemplos de código en la Carpeta de Práctica, donde encontrarás implementaciones y ejercicios resueltos.
Temas vistos
-
Thread Programming
Introducción a la creación y manejo de hilos (threads), su ciclo de vida, sincronización básica y comunicación entre hilos. -
Parallelism
Estrategias para dividir un problema en subproblemas que puedan ejecutarse en paralelo y aprovechar varios núcleos de CPU. -
Mutual Exclusion
Exclusión mutua para evitar condiciones de carrera: secciones críticas y protocolos básicos como test-and-set. -
Concurrency Abstractions
Mecanismos de más alto nivel para coordinar hilos:- Locks
Cerraduras simples para proteger secciones críticas. - Reader‐Writer Locks
Locks que permiten múltiples lectores simultáneos o un único escritor. - Semaphores
Contadores sincronizados que controlan el acceso a recursos compartidos. - Condition Variables
Variables de condición que permiten a un hilo esperar hasta que se cumpla cierta condición, liberando antes el mutex. - Monitors
Abstracción que combina mutex y condition variables en un solo bloque para proteger datos compartidos. - Messages
Comunicación mediante envío y recepción de mensajes entre hilos, evitando acceso directo a variables compartidas.
- Locks
-
Mutex Implementation
Ejemplos de implementación de mutex en bajo nivel usando operaciones atómicas (test-and-set,compare-and-swap). -
Non Blocking Algorithms
Algoritmos lock-free y wait-free: pilas y colas no bloqueantes, contadores atómicos y estructuras de datos concurrentes sin mutex. -
Asynchronicity
Programación asíncrona con corutinas (en Kotlin):suspend fun,async/awaitFutures- Timeouts y manejo de errores
-
Actors (en Scala)
Modelo de actores usandoAkka: cada actor mantiene su propio estado y coordina con otros mediante mensajes, evitando la necesidad de memoria compartida.
Ejemplos de código en la Carpeta de Práctica
Para ver implementaciones concretas y ejercicios resueltos en cada uno de los temas anteriores, visita la siguiente ruta dentro de este sitio:
Allí encontrarás carpetas organizadas por tema con el código fuente y las explicaciones correspondientes.
Introducción
Definición
La programación concurrente es un paradigma en el desarrollo de software que permite ejecutar múltiples tareas o procesos simultáneamente, ya sea mediante una ejecución paralela real (como en sistemas multicore o multiprocesador) o intercalando tareas de manera que parezca que se ejecutan al mismo tiempo.
Nota: Es importante diferenciar un sistema multicore de uno multiprocesador, siendo el primero un sistema que tiene múltiples núcleos de procesamiento en un solo chip, mientras que el segundo tiene múltiples chips, cada uno con su propio núcleo.
En ambos casos, la programación concurrente permite aprovechar al máximo los recursos del sistema y mejorar el rendimiento de las aplicaciones.
Todo esto de teoría va a ser un bodrio, va a estar mucho más simplificada la práctica
¿Por qué surge?
- La necesidad de mejorar el rendimiento y la eficiencia de los sistemas informáticos.
- La mayoría de los programas y sistemas eran single-threaded, por lo que había que reducir tiempos de ejecución.
Previo a hablar de programación concurrente, es importante entender el concepto de multiprogramming.
Multiprogramming
- Permite que varios programas se carguen en memoria y se ejecuten de manera concurrente.
- El sistema operativo gestiona la ejecución de los programas, asignando tiempo de CPU a cada uno de ellos.
- Gestiona el tiempo de ejecución de cada programa con tal de que la CPU siempre esté ocupada.
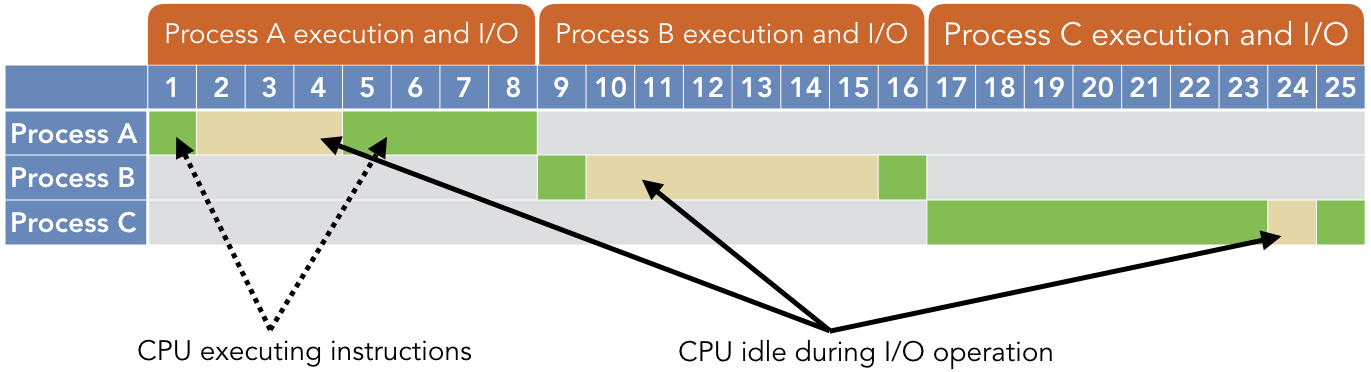
Sistemas Operativos y Time-Sharing
- Time-sharing: una extensión lógica de multiprogramación.
- El tiempo del procesador se comparte entre varios usuarios al mismo tiempo
- Se crea la ilusión de una máquina rápida y dedicada para cada usuario
¿Por qué aplicamos programación concurrente?
- Uso de recursos: uso eficiente del tiempo de inactividad durante operaciones de entrada/salida.
- Equidad: compartición equitativa de recursos entre múltiples usuarios o programas.
- Conveniencia: facilita la gestión de múltiples tareas o procesos.
Scheduling
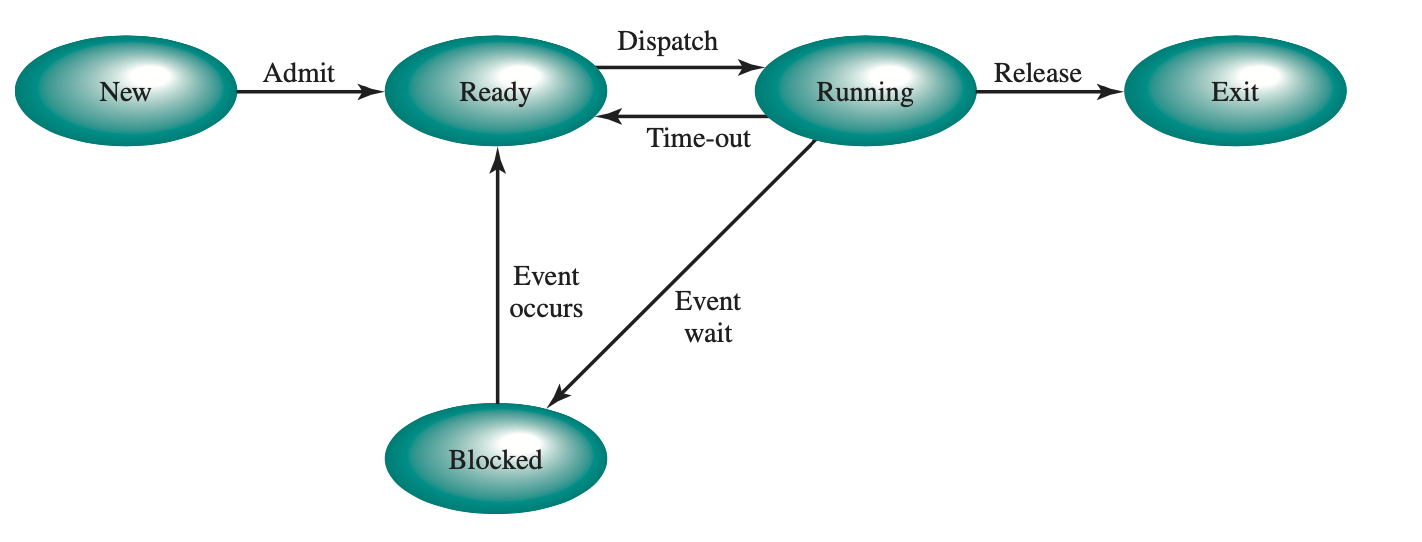
Cooperativo
Las tareas ceden voluntariamente el control de la CPU, permitiendo que otras tareas se ejecuten.
Características Clave
-
Control de Tarea: Las tareas controlan su propia cesión de la CPU.
-
Cesión: Una tarea cede la CPU cuando está inactiva o cuando decide permitir que otras tareas se ejecuten.
-
Ventajas: Simplicidad, baja sobrecarga, utilización predecible de recursos.
-
Desafíos:
-
Depende de que las tareas se comporten correctamente.
-
Una sola tarea mal comportada puede acaparar la CPU, afectando la capacidad de respuesta del sistema.
-
Casos de Uso Ideales
-
Entornos donde las tareas pueden ser confiables para ceder regularmente.
-
Sistemas que priorizan la simplicidad sobre la eficiencia del multitarea.
Preventivo
El sistema operativo controla la ejecución de las tareas, interrumpiendo y reanudándolas por la fuerza según sea necesario para garantizar una asignación justa y eficiente de recursos.
Características Clave
-
Controlado por SO: El SO decide cuándo una tarea debe ceder la CPU.
-
Partición de Tiempo: Las tareas tienen porciones de tiempo de CPU y son preemptadas cuando las exceden.
-
Ventajas: Mejor capacidad de respuesta, equidad, mejor manejo de tiempo real.
-
Desafíos:
-
Mayor complejidad en la implementación.
-
Potencial para contención de recursos y sobrecarga asociada.
-
Casos de Uso Ideales
-
Sistemas operativos de propósito general.
-
Entornos donde las tareas no pueden ser confiables para ceder regularmente.
-
Sistemas de tiempo real que necesitan tiempos de respuesta garantizados.
Cambio de Contexto
- El proceso de guardar el estado de una tarea actualmente en ejecución y cargar el estado de otra tarea.
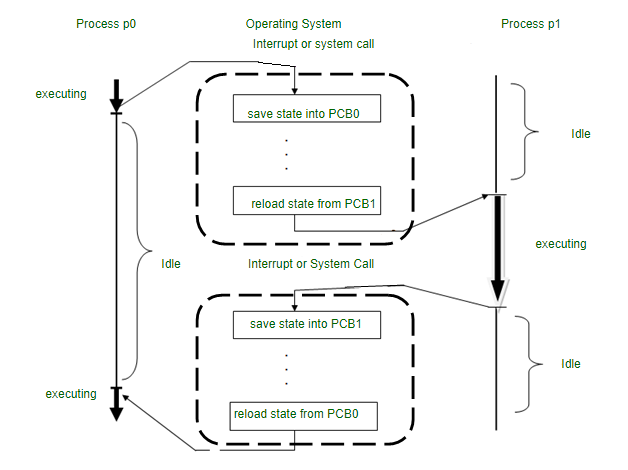
¿Qué guarda como estado?
- Program Counter: dirección de la siguiente instrucción
- Registros de la CPU en ese momento
- Stack: variables locales, parámetros de funciones, y direcciones de retorno
- Información de manejo de memoria y otros.
Concurrencia vs Paralelismo vs Interleaving
Concurrencia
- La concurrencia se refiere a la capacidad de un sistema para gestionar múltiples tareas u operaciones al mismo tiempo.
- No significa necesariamente que estas operaciones se estén ejecutando simultáneamente.
- En los sistemas concurrentes, diferentes partes de una tarea o múltiples tareas pueden estar en progreso al mismo tiempo, pero no necesariamente tienen que estar ejecutándose en el mismo momento exacto.
La concurrencia trata sobre la estructura.
Paralelismo
- El paralelismo se refiere a la ejecución de múltiples tareas o procesos simultáneamente.
- Esto requiere hardware con múltiples unidades de procesamiento, como procesadores multi-núcleo.
- En los sistemas paralelos, las tareas se ejecutan literalmente al mismo tiempo, como líneas de ensamblaje paralelas en una fábrica trabajando simultáneamente.
El paralelismo trata sobre la ejecución.
Interleaving / Intercalado
Una técnica para alternar rápidamente entre tareas, ejecutándolas en pequeños fragmentos.
Características clave
- Simula el paralelismo.
- Enfoque de compartición de tiempo: el tiempo de CPU se divide entre múltiples procesos en sucesión rápida.
- Eficiencia: proporciona una utilización eficiente de la CPU al reducir el tiempo de inactividad durante las tareas, como las operaciones de entrada/salida.
- Ejemplo: un chef que prepara múltiples platos alternando entre ellos, en lugar de cocinar cada uno de principio a fin.
Contraste con Overlapping

Procesos vs. Threads
- Programa
Una colección de instrucciones y datos que pueden ser ejecutados por una computadora para realizar una tarea o función específica.
- Proceso
Una instancia en ejecución de un programa. Es una unidad independiente que consiste en su propio espacio de direcciones, memoria, datos y recursos del sistema.
- Thread
La unidad más pequeña de ejecución dentro de un proceso.
Representa una secuencia única de instrucciones que puede ser programada por el scheduler del sistema.
Múltiples hilos dentro de un proceso comparten el mismo espacio de memoria pero tienen su propio
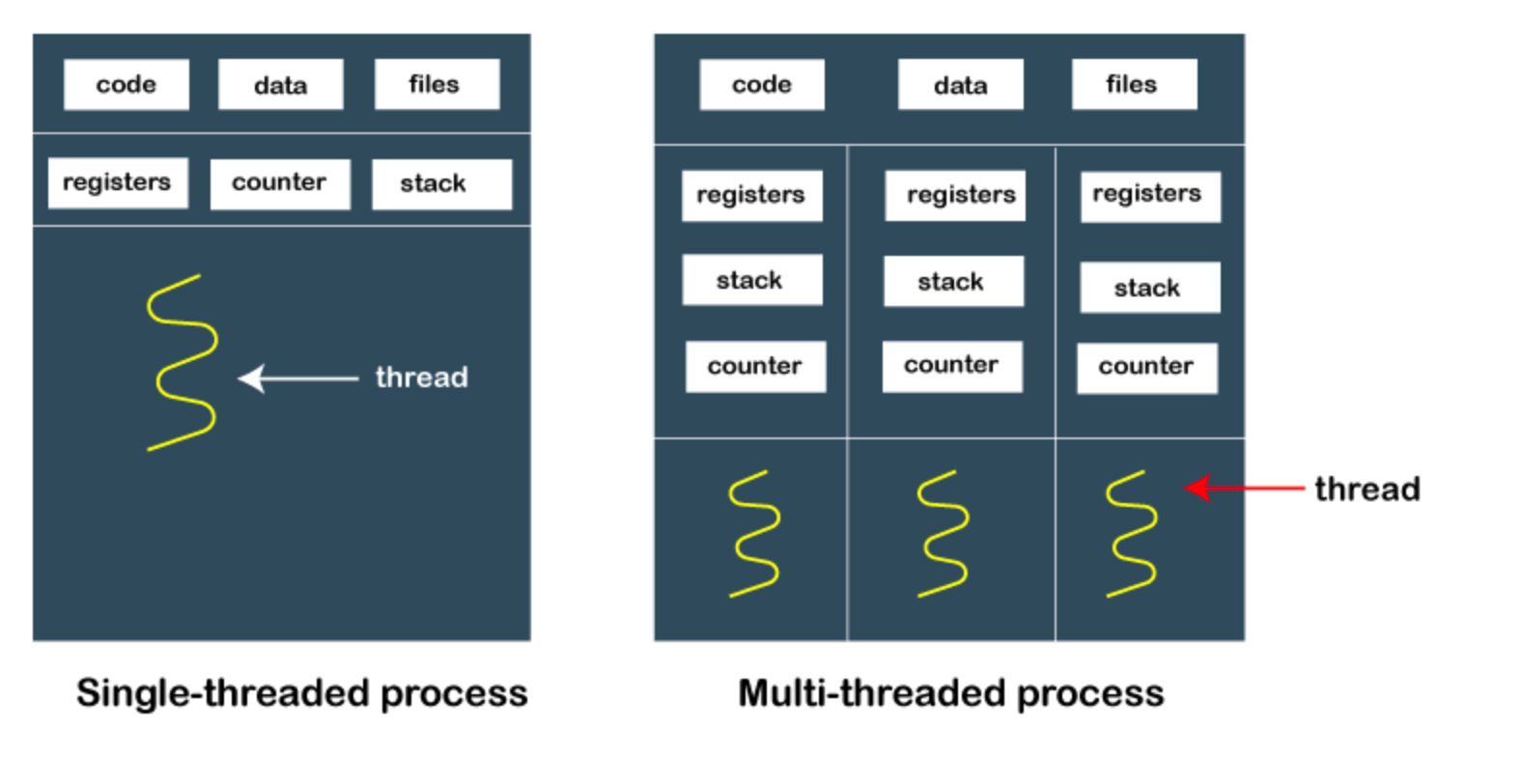
Tipos de threads
- User-Level: El trabajo de gestión de hilos lo hace la aplicación y el kernel no es consciente de la existencia de estos hilos.
- Kernel-Level: Todo el trabajo de gestión de hilos lo realiza el kernel. A nivel de aplicación hay una API para la funcionalidad de hilos del kernel.
| Característica | Hilos a Nivel de Usuario | Hilos a Nivel de Kernel |
|---|---|---|
| Implementación | En espacio de usuario | En espacio de kernel |
| Tiempo de Cambio de Contexto | Rápido | Más lento |
| Sobrecarga/Consumo de Memoria | Bajo | Mayor |
| Reconocimiento del SO | No reconocidos | Reconocidos |
| Programación | Por biblioteca de nivel de usuario | Por kernel del SO |
| Asignación de Recursos | No directa | Directa |
| Bloqueo | Un hilo puede bloquear todo el proceso | Bloqueo independiente |
| Rendimiento en Multi CPU | Limitado | Mejor |
Thread Programming
Hay que saber cómo levantar un thread en los lenguajes que vayamos a usar,
para entender cómo los tratan por abajo.
Java
private static void hello() {
var t1 = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Hello from thread 1");
}
});
var t2 = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Hello from thread 2");
}
});
t1.start();
t2.start();
}
// Con Lambdas
private static void helloLambda() {
var t1 = new Thread(() -> System.out.println("Hello from thread 1"));
var t2 = new Thread(() -> System.out.println("Hello from thread 1"));
t1.start();
t2.start();
}
Cabe destacar que lo anterior simplemente levanta los threads, que se ejecutarán como el procesador los quiera ejecutar.
Administrar manualmente la ejecución
private static void hello() throws InterruptedException {
var t1 = new Thread(() -> System.out.println("Hello from thread 1"));
var t2 = new Thread(() -> System.out.println("Hello from thread 2"));
t1.start();
t2.start();
t1.join();
t2.join();
}
El método join espera a que el thread termine su ejecución.
Si no se llama a join, el thread principal puede terminar antes que los threads secundarios.
Denle importancia al
throws InterruptedException. La firma de esta función es así porque, al querer unir los threads al principal (o esperar a que terminen), puede haber una interrupción.
Al llamar a este método, se habilita a que cualquier thread interrumpa el actual (donde se está ejecutando esta función) por la razón que sea.
Rust
#![allow(unused)] fn main() { fn hello() { thread::spawn(|| println!("Hello from thread 1")); thread::spawn(|| println!("Hello from thread 2")); } }
Esperar a que termine la ejecución
#![allow(unused)] fn main() { fn hello() { let t1 = thread::spawn(|| println!("Hello from thread 1")); let t2 = thread::spawn(|| println!("Hello from thread 2")); // Esperar a que los threads se completen t1.join().expect("t1 failed"); t2.join().expect("t2 failed"); } }
Thread Scope
El Scope es una forma de agrupar threads, de forma tal que se ejecuten en un mismo contexto.
Además, el Scope permite que los threads se compartan variables entre ellos, sin necesidad de usar Arc o Mutex (para
casos de solo lectura).
Una vez termina el Scope, los threads se unen automáticamente, por lo que no es necesario llamar a join manualmente.
#![allow(unused)] fn main() { fn hello() { thread::scope(|s| { s.spawn(|| println!("Hello from thread 1")); s.spawn(|| println!("Hello from thread 2")); }); } }
Lifetime
Sabiendo que Rust sabe que los threads no escapan del scope:
- Las reglas de Lifetime son más simples
- Podemos usar variables del scope externo
#![allow(unused)] fn main() { fn hello() { let n = 10; let mut m = 10; thread::scope(|s| { s.spawn(|| { m += 1; println!("Hello from thread 1, n = {n}") }); s.spawn(|| println!("Hello from thread 2, n = {n}")); }); println!("{m}"); } // Output: 11 }
Paralelismo
Esta clase todo lo que hace es mostrar implementaciones concurrentes de resolver algoritmos iterativos, que terminan siendo dividir los cálculos en algún punto, spawnear un thread en esa división y seguir calculando.
Después de eso se espera que el thread termine y se junten los resultados.
Ejemplo
Si queremos calcular , podemos:
- Primero calcular
- Después calcular
- Finalmente, multiplicar los resultados de los dos pasos anteriores.
Implementación secuencial
#![allow(unused)] fn main() { fn evaluate_sequential(k: f64, a: f64, t: f64) -> f64 { let a = 2.0 * k * a * t; let b = f64::exp(-a * t * t); return a * b; } }
Implementación concurrente
#![allow(unused)] fn main() { use std::thread; fn evaluate_parallel(k: f64, a: f64, t: f64) -> f64 { let thread1 = thread::spawn( || 2.0 * k * a * t ); let thread2 = thread::spawn( || f64::exp(-a * t) ); let a = thread1.join().unwrap(); let b = thread2.join().unwrap(); return a * b; } }
Se puede hacer una pequena optimización, en vez de crear dos threads, podemos crear uno solo y hacer el cálculo de dentro del thread. Esto es para que el thread principal no se quede esperando a que termine el otro thread, con tal de seguir ejecutando el resto del código.
#![allow(unused)] fn main() { use std::thread; fn evaluate_parallel_opt(k: f64, a: f64, t: f64) -> f64 { let first_half = 2.0 * k * a * t; let thread2 = thread::spawn(|| f64::exp(-a * t)); let second_half = thread2.join().unwrap(); return first_half * second_half; } }
Observación importante
A veces, no siempre es mejor hacer implementaciones paralelas, dado que puede suponer un overhead a partir de los cambios de contexto.
Si el cálculo es muy rápido, el overhead de crear un thread puede ser mayor que el tiempo que se tarda en calcular el resultado de manera iterativa.
Ejemplo - MergeSort
#![allow(unused)] fn main() { pub fn merge(first: &[i32], second: &[i32]) -> Vec<i32>{ let mut result = Vec::new(); let mut i = 0; let mut j = 0; // Merge until one of the inputs is exhausted while i < first.len() && j < second.len() { if first[i] <= second[j] { result.push(first[i]); i += 1 } else { result.push(second[j]); j += 1 } } // Copy the remaining items result.extend_from_slice(&first[i..]); result.extend_from_slice(&second[j..]); result } pub fn sort(array: &[i32]) -> Vec<i32> { let len = array.len(); if len <= 1 { array.to_vec() } else { let (first, second) = thread::scope(|s| { let x = sort(&array[..len / 2]); // First half let y = s.spawn(|| sort(&array[(len / 2) + 1..])); // Second half (x, y.join().unwrap()) // <-- Scope also returns a value }); merge(&first, &second) } } }
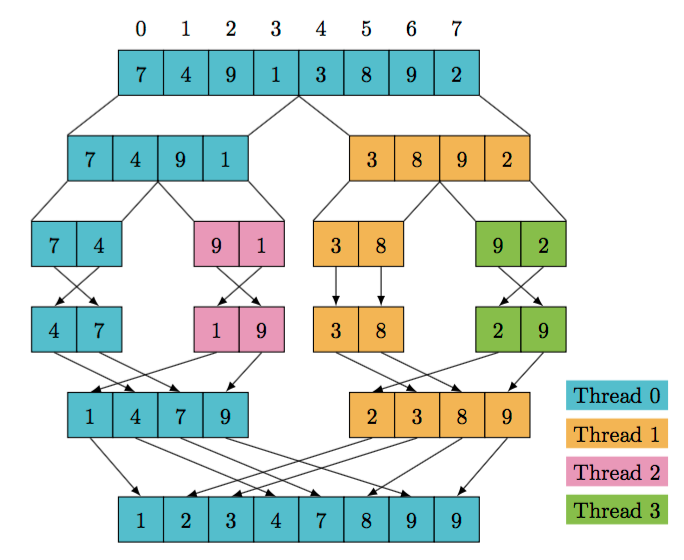
Por lo general se optimiza de la siguiente manera (conceptualmente):
- Se implementan ambos métodos de cálculo (secuencial y concurrente)
- Si se supera un cierto threshold o límite, se llama al método concurrente
- Este threshold va a variar dependiendo del caso y del algoritmo a implementar
- Inclusive puede variar según la máquina donde se esté corriendo
- Si no, se opera con el método secuencial.
Esto se hace para evitar cambios de contexto innecesarios. Los threshold se obtienen/determinan a prueba y error.
Más ejemplos
Matriz
#![allow(unused)] fn main() { #[derive(Debug, Clone)] pub struct Matrix(pub Vec<Vec<f64>>); impl Matrix { pub fn rows(&self) -> usize { self.0.len() } pub fn columns(&self) -> usize { self.0[0].len() } } }
#![allow(unused)] fn main() { // Suma de matrices pub fn add_serial(&self, other: &Matrix) -> Matrix { let rows = self.rows(); let cols = self.columns(); let mut result = Vec::new(); for i in 0..rows { let mut row = Vec::new(); for j in 0..cols { row.push(self.0[i][j] + other.0[i][j]); } result.push(row); } Matrix(result) } // Secuencial con map pub fn add_serial(&self, other: &Matrix) -> Matrix { let rows = self.rows(); let cols = self.columns(); let result = (0..rows) .map(|i| (0..cols) .map(|j| self.0[i][j] + other.0[i][j]) .collect() ) .collect(); Matrix(result) } }
#![allow(unused)] fn main() { // Paralelo, fila por fila pub fn add_parallel(&self, other: &Matrix) -> Matrix { let rows = self.rows(); let cols = self.columns(); thread::scope(|s| { let threads: Vec<_> = (0..rows) .map(|i| { s.spawn(move || { (0..cols).map(|j| self.0[i][j] + other.0[i][j]).collect() }) }) .collect(); Matrix(threads.into_iter() .map(|t| t.join().unwrap()) .collect()) }) } }
Exclusión Mutua
La raíz del problema
- No determinismo causado por hilos concurrentes accediendo a un estado mutable compartido.
- Ayuda encapsular el estado en actores o transacciones, pero el problema fundamental sigue siendo el mismo.
No determinismo = procesamiento paralelo + estado mutable.
- Para obtener un procesamiento determinista, ¡evita el estado mutable!
- Evitar el estado mutable significa programar funcionalmente.
Condición de carrera
Una condición de carrera ocurre cuando dos o más operaciones deben ejecutarse en una secuencia específica, pero el comportamiento sustancial del sistema no está garantizado, llevando a resultados erráticos e impredecibles.
Ejemplo en Java
public class Counter {
int value = 0;
void increment() {
int localCounter = value;
System.out.println(threadName() + " reads counter as: " + localCounter);
localCounter = localCounter + 1;
value = localCounter;
System.out.println(threadName() + " updated counter to: " + value);
}
}
public class Main {
public static void main(String[] args) {
var counter = new Counter();
// Two threads trying to increment the counter simultaneously
Thread t1 = new Thread(counter::increment, "Thread 1");
Thread t2 = new Thread(counter::increment, "Thread 2");
startAll(t1, t2);
joinAll(t1, t2);
System.out.println("Expected value: 2, actual value: " + counter.value);
}
}
Output:
Thread 1 reads counter as: 0
Thread 2 reads counter as: 0
Thread 1 updated counter to: 1
Thread 2 updated counter to: 1
Expected value: 2, actual value: 1

Solución: Forzar Acceso Único
Si forzamos una regla de que solo un proceso puede entrar al método incrementar a la vez entonces:
- Thread1 entra a incrementar primero y crea un bloqueo
- Thread2 intenta entrar pero es bloqueado
- Thread1 completa la ejecución y libera el bloqueo
- Thread2 se reanuda y ejecuta incrementar
public class Counter {
int value = 0;
synchronized void increment() {
int localCounter = value;
System.out.println(threadName() + " reads counter as: " + localCounter);
localCounter = localCounter + 1;
value = localCounter;
System.out.println(threadName() + " updated counter to: " + value);
}
}
Nótese que el keyword synchronized en Java es un ejemplo básico de un lock (específicamente de un Mutex).
- Si se hace sobre un método, el lock es sobre el objeto que contiene el método.
- Si se hace sobre un bloque, el lock es sobre el objeto que se le pasa al bloque.
- Si se hace sobre una variable o atributo de la clase, el lock es sobre la variable o atributo.
- Si se hace sobre un método estático, el lock es sobre la clase.
Memoria compartida entre hilos
public class Test {
boolean a = false, b = false;
int x = -1, y = -1;
void test(int execution) {
var t1 = new Thread(() -> {
sleep(1);
a = true;
y = b ? 0 : 1;
});
var t2 = new Thread(() -> {
sleep(1);
b = true;
x = a ? 0 : 1;
});
startAll(t1, t2);
joinAll(t1, t2);
if (x == 1 && y == 1)
throw new RuntimeException("Failed at execution number : " + execution);
}
}
Posibles casos para el programa anterior:
-
Primera alternativa:
t1corre primero
t1escribetrueena, luego leeby vefalse→ escribe1eny
t2escribetrueenb, luego leeay vetrue→ escribe0enx
Resultado:x == 0yy == 1 -
Segunda alternativa:
t2corre primero
t2escribetrueenb, luego leeay vefalse→ escribe1enx
t1escribetrueena, luego leeby vetrue→ escribe0eny
Resultado:x == 1yy == 0 -
Tercera alternativa: Ejecución parcial
t1escribetrueenay es interrumpido
t2escribetrueenb
Luego, tantot1comot2ven ambos valores entrue, así que escriben0enxey
Resultado:x == 0yy == 0
Conclusión: No existe ninguna ejecución en la que x == 1 y y == 1
Pongámoslo a prueba
public static void main(String[] args) {
for (var i = 0; i < 10_000; i++)
new Test().test(i);
}
Output:
Exception in thread "main" java.lang.RuntimeException: Failed at execution number : 880
at org.example.counter.Test.test(Test.java:25)
at org.example.counter.Test.main(Test.java:30)
¿Por qué falló?
Los hilos pueden correr en distintos núcleos usando su propia memoria (por ejemplo, L1 cache).
Los threads se sincronizan a través de la memoria compartida, por ejemplo, después de hacer join.
Entonces, esto es posible:
t1escribetrueena, luego leeby vefalse→ escribe1enyt2escribetrueenb, luego leeay vefalse→ escribe1enxPorquet2tiene su propio valor deaque todavía no fue sincronizado.
En el ejemplo anterior en el que es virtualmente imposible que falle, la falla se da porque el thread que falló leyó memoria vieja (que ya no existe) respecto a una de las 2 variables, y actualizó la otra.
Es difícil compartir la memoria entre threads debido a estas cuestiones, por lo que en distintos lenguajes se implementan distintas formas de hacerlo.
En Java, se usa el keyword volatile. En este caso se declaran a y b con este keyword.
Esto fuerza a la JVM a sincronizar la variable hacia y desde la memoria compartida. volatile es ligero y más rápido que el bloqueo.
Competencia por recursos
Ahora, otro de los problemas principales de la memoria compartida es que los procesos van a competir por recursos, lo que genera las siguientes necesidades y problemas:
- Necesidad de Exclusión Mutua. Sólo un proceso a la vez debe ser permitido en la sección crítica del programa.
- Deadlock
- Starvation
Deadlock
Deadlock puede ser definido como el bloqueo permanente de un conjunto de procesos que compiten por recursos.
Un conjunto de procesos está en deadlock cuando cada proceso en el conjunto está bloqueado
esperando por un recurso que está retenido por otro proceso bloqueado en el conjunto.
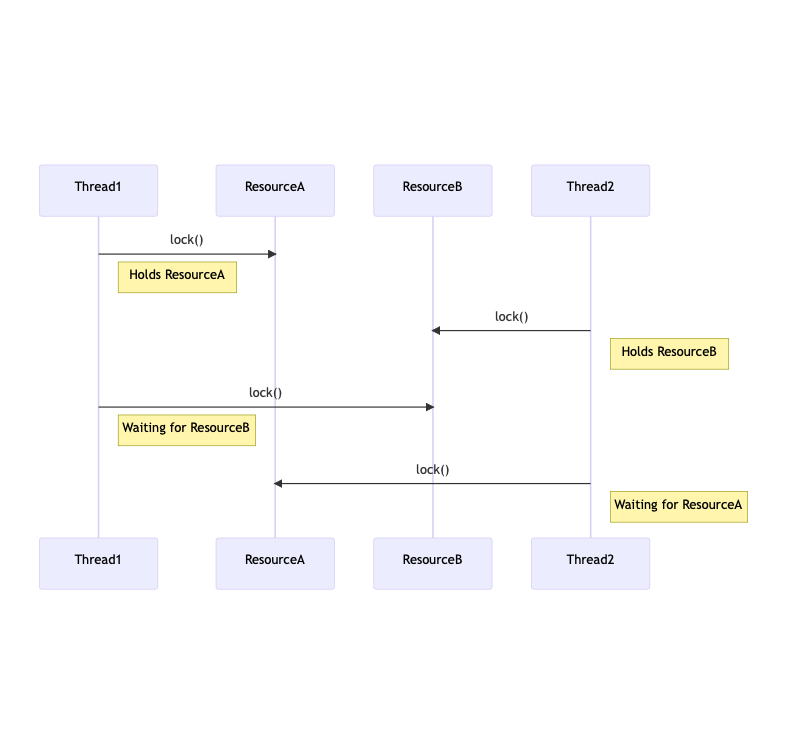
Ejemplo
public void transferTo(BankAccountSync to, double amount) {
synchronized (this) {
// Lock over 'this' acquired
// Try to lock 'to'
synchronized (to) {
// Lock over 't0' acquired.
withdraw(amount);
to.deposit(amount);
}
// lock over 'to' released
}
// lock over 'this' released
}
Starvation
Una situación donde a un proceso se le niegan perpetuamente los recursos que necesita para progresar, mientras que otros procesos son favorecidos, llevando a una espera indefinida.
En resumen, un proceso se muere de hambre porque quiere acceder a un recurso y siempre se le deniega dicho acceso.
Ejemplo de solución de Starvation
public class Counter {
int value = 0;
void increment() {
disableInterruptions();
int localCounter = value;
localCounter = localCounter + 1;
value = localCounter;
enableInterruptions();
}
}
- Esto sólo funciona en uni-procesadores
- Generalmente es ineficiente
Otro ejemplo
volatile boolean lock = false;
void increment() {
while (lock) {
// Busy Loop
}
lock = true;
// Begin Critical Section
int localCounter = value;
System.out.println(threadName() + " reads counter as: " + localCounter);
localCounter = localCounter + 1;
value = localCounter;
// End Critical Section
lock = false;
System.out.println(threadName() + " updated counter to: " + value);
}
- Necesito del keyword
volatilepara el lock justamente por estas cuestiones de sincronización. - El problema radica acá:
while (lock) {
// Busy Loop
}
// Puedo tener un Context Switch acá !
lock = true;
La alternativa para estos casos es el uso de variables atómicas, otorgadas por el hardware (que veremos más adelante en Non-Blocking Algorithms):
void increment() {
while (v.compareAndSet(false, true)) {
// busyLoop
}
// Critical section
// ...
}
- Lo bueno: Aplicable a cualquier cantidad de procesos.
- Lo malo: El busy-waiting consume tiempo de procesador.
- Solución:
- Después de girar un poco (spinning), devolver el control al sistema operativo.
while (lock.compareAndSet(false, true)) Thread.yield();
Por último, en clase vimos que Rust no puede tener condiciones de carrera porque es un lenguaje de verdad y el borrow checker lo evita (al menos con una variable mutable).
En casos más complejos lo resuelve de otra manera.
#![allow(unused)] fn main() { fn counter() -> i32 { let mut counter = 0; thread::scope(|s| { s.spawn(|| counter += 1); s.spawn(|| counter += 1); }); return counter } }
Output:
error[E0499]: cannot borrow `counter` as mutable more than once at a time
... Etc..
Sin embargo, según la documentación de Rust, el lenguaje previene específicamente Data Races, un subtipo de condiciones de carrera donde:
- Dos o más threads acceden concurrentemente un espacio de memoria
- Uno o más de ellos realiza una operación de escritura
- Uno o más de ellos no está sincronizado
Y dicha prevención proviene justamente de lo explicado anteriormente respecto al borrow checker.
Sin embargo, no nos protege de condiciones de carrera en general. Por ejemplo, veamos el siguiente caso:
fn main() { let data = vec![1, 2, 3, 4]; let idx_mutex = Arc::new(Mutex::new(0)); let other_idx_mutex = Arc::clone(&idx_mutex); let _ = thread::spawn(move || { let mut current_idx = other_idx_mutex.lock().unwrap(); *current_idx += 10; }); let current_index_value; { let idx_guard = idx_mutex.lock().unwrap(); current_index_value = *idx_guard; } println!("{}", data[current_index_value]); }
- Si el thread principal se termina de ejecutar y luego corre el thread que él mismo inicializa, el print funciona, mostrando el primer elemento del Vec.
- En cambio, si ese segundo thread logra ejecutarse primero, entonces
current_index_value = 10. Esto provoca un panic en el print, ya que se intenta acceder al elemento 10 del Vec, pero solo tiene 4 elementos.
En consecuencia, se da una condición de carrera porque el programa puede ser exitoso o fallar dependiendo del orden de ejecución de los threads.
Abstracciones de Concurrencia - Parte I
Lock
Un lock (o mutex de exclusión mutua) es una primitiva de sincronización que previene que el estado sea modificado o accedido por múltiples hilos de ejecución a la vez.
- Cuando un hilo quiere acceder a un recurso compartido, primero intenta adquirir el lock asociado con ese recurso.
- Si el lock está disponible (i.e., no está siendo retenido por otro hilo), el hilo adquiere el lock, accede al recurso, y luego libera el lock cuando termina.
- Si el lock no está disponible (i.e., actualmente retenido por otro hilo), el hilo que lo solicita es bloqueado para proceder hasta que el lock esté disponible.
Tipos de Lock
- Mutex (Exclusión Mutua) : Un lock básico que permite que solo un hilo acceda a un recurso a la vez.
- Reentrant Lock: Puede ser adquirido múltiples veces por el mismo hilo sin causar un deadlock.
- Read/Write Locks: Permite que múltiples lectores accedan al recurso simultáneamente, pero requiere acceso exclusivo para escritura.
Ejemplos
- Con
synchronizedsobre un objeto:
class BankAccountSync {
private double balance;
private final Object lock = new Object();
public BankAccountSync(double initialBalance) {
this.balance = initialBalance;
}
// Synchronized method to deposit money
public void deposit(double amount) {
synchronized (lock) {
if (amount > 0) {
balance += amount;
System.out.println("Deposited: " + amount);
}
}
}
// Synchronized method to withdraw money
public void withdraw(double amount) {
synchronized (lock) {
if (amount > 0 && balance >= amount) {
balance -= amount;
System.out.println("Withdrawn: " + amount);
} else {
System.out.println("Insufficient balance for withdrawal");
}
}
}
public double getBalance() {
synchronized (lock) {
return balance;
}
}
}
synchronizedsobre un método:
class BankAccountSync {
private double balance;
public BankAccountSync(double initialBalance) {
this.balance = initialBalance;
}
// Synchronized method to deposit money
public synchronized void deposit(double amount) {
if (amount > 0) {
balance += amount;
System.out.println("Deposited: " + amount);
}
}
// Synchronized method to withdraw money
public synchronized void withdraw(double amount) {
if (amount > 0 && balance >= amount) {
balance -= amount;
System.out.println("Withdrawn: " + amount);
} else {
System.out.println("Insufficient balance for withdrawal");
}
}
public double getBalance() {
synchronized (this) {
return balance;
}
}
}
- Con
Lockdel API deJava:
class BankAccountWithLock implements BankAccount {
private double balance;
private final Lock lock = new ReentrantLock();
public BankAccountWithLock(double initialBalance) {
this.balance = initialBalance;
}
// Method to deposit money using Lock
public void deposit(double amount) {
lock.lock();
try {
if (amount > 0) {
balance += amount;
System.out.println("Deposited: " + amount);
}
} finally {
lock.unlock();
}
}
// ... etc
}

En un lenguaje de verdad...
- Un mutex en Rust es un dato con un lock que protege su acceso.
- Para acceder al dato dentro del mutex, un thread tiene que avisar que quiere acceder pidiendo adquirir el lock del mutex.
lockdevuelve un Smart Pointer al valor dentro del Mutex.- Devuelve un
MutexGuard<T>
- Devuelve un
- Mutex sólo le permite a un thread a la vez acceder al dato.
#![allow(unused)] fn main() { use std::sync::Mutex; pub struct BankAccount { balance: Mutex<f64> } impl BankAccount { pub fn new(initial_balance: f64) -> BankAccount { BankAccount { balance: Mutex::new(initial_balance) } } pub fn deposit(&self, amount: f64) { let mut balance = self.balance.lock().unwrap(); *balance += amount; println!("Deposited: {}", amount); } pub fn withdraw(&self, amount: f64) { if let Ok(mut balance) = self.balance.lock() { if *balance >= amount { *balance -= amount; println!("Withdrawn: {}", amount); } else { println!("Insufficient balance for withdrawal"); } } } pub fn get_balance(&self) -> f64 { *self.balance.lock().unwrap() } } }
Livelock
Es una condición que tiene lugar cuando 2 o más threads cambian su estado continuamente, sin que ninguno de ellos haga progreso.
Esto lo hace ver con el ejemplo del problema de los filósofos, en la variante donde todos agarran primero el tenedor derecho y el último lo da vuelta (agarra el izquierdo).
Recordemos que en el caso donde todos intentan agarrar primero el derecho se produce un deadlock.
Reader Writer Lock
También conocido como un lock compartido-exclusivo o un lock de múltiples lectores/un único escritor.
- Es un mecanismo de sincronización para manejar situaciones donde un recurso puede ser accedido por múltiples hilos simultáneamente.
- Este tipo de lock permite acceso concurrente de solo lectura al recurso compartido, mientras que las operaciones de escritura requieren acceso exclusivo.
Son útiles en escenarios de alta concurrencia donde las lecturas son frecuentes y las escrituras son poco frecuentes.
- Múltiples threads pueden sostener el lock de lectura simultáneamente, siempre y cuando ningún thread sostenga el lock de escritura.
- Solo un thread puede sostener el lock de escritura a la vez. Cuando un thread sostiene el lock de escritura, ningún otro thread puede sostener el lock de lectura o escritura.
- Se pueden implementar con diferentes políticas de prioridad, como dar preferencia a los lectores, escritores o ninguno.
- La elección de la política puede afectar el comportamiento del lock en términos de equidad y potencial de
Starvation.
Ejemplo
#![allow(unused)] fn main() { impl BankAccountRW { pub fn new(initial_balance: f64) -> BankAccountRW { BankAccountRW { balance: RwLock::new(initial_balance) } } pub fn deposit(&self, amount: f64) { if let Ok(mut balance) = self.balance.write() { *balance += amount; println!("Deposited: {}", amount); } } pub fn get_balance(&self) -> f64 { *self.balance.read().unwrap() } } }
Semáforos
Son una primitiva de sincronización usada en programación concurrente.
Proveen un mecanismo para controlar el acceso a recursos compartidos por múltiples procesos o hilos.
En definitiva, es un contador con 2 operaciones principales:
down (P)oacquire: Decrementa el contador. Si el contador es menor a 0, el hilo se bloquea hasta que se libere.up (V)orelease: Incrementa el contador. Si el contador era 0 o menor, despierta a un hilo bloqueado.
Tipos de semáforos
- Semáforo binario: Puede tomar solo los valores 0 o 1. Se usa para implementar exclusión mutua.
- El
MutexoLockcomún que conocemos es de este tipo.Mutexde Rust yLockde Java
- El
- Semáforo contable: Puede tomar cualquier valor entero no negativo. Se usa para controlar el acceso a un número limitado de recursos.
public class Counter {
int value = 0;
Semaphore semaphore = new Semaphore(1, true);
void increment() {
semaphore.acquire(); // wait or down or P
int local_counter = value;
local_counter = local_counter + 1;
value = local_counter;
semaphore.release(); // signal or up or V
}
}
Implementación de un semáforo
class Semaphore {
private boolean lock;
private int count;
private Queue<Thread> q;
public Semaphore(int init) {
lock = false;
count = init;
q = new Queue();
}
public void down() {
while (lock.testAndSet()) { /* just spin */ }
if (count > 0) {
count--;
lock = false;
}
else {
q.add(currrentThread);
lock = false;
suspend();
}
}
public up() {
while (lock.testAndSet()) { /* just spin */ }
if (q == empty) count ++;
else q.pop().wakeUp();
lock = false;
}
}
Abstracciones de Concurrencia - Parte II
Variables de Condición
Tienen como propósito hacer que los threads esperen una condición específica sin consumir recursos. Similar a los semáforos, tienen 2 operaciones principales:
- Esperar: un thread espera a que una condición se cumpla. Si no se cumple, libera el Mutex asociado de manera atómica para evitar condiciones de carrera.
- Señalizar: un thread notifica a otro que la condición se ha cumplido. Esto despierta al thread que estaba esperando.
Ejemplo de uso
// Sin condvar: use std::sync::{Mutex, Arc}; fn main() { let queue = Mutex::new(VecDeque::new()); thread::scope(|s| { s.spawn(|| { loop { // Busy loop !! let mut q = queue.lock().unwrap(); if let Some(item) = q.pop_front() { println!("Popped: {item}", ); } } }); for i in 0.. { queue.lock().unwrap().push_back(i); thread::sleep(Duration::from_secs(1)); } } ); }
// Con condvar: use std::sync::{Mutex, Condvar}; fn main() { let queue = Mutex::new(VecDeque::new()); let not_empty = Condvar::new(); thread::spawn(|| { loop { let mut q = queue.lock().unwrap(); if let Some(item) = q.pop_front() { println!("Popped: {item}", ); } else { q = not_empty.wait(q).unwrap(); // <--- Wait } } }); // Pushear elementos: for i in 0.. { queue.lock().unwrap().push_back(i); not_empty.notify_one(); // <-- notify the first thread waiting thread::sleep(Duration::from_secs(1)); } }
Beneficios
- Mecanismo de espera eficiente en programación concurrente
- Facilita escenarios de sincronización compleja
Problema de Producers-Consumers
Involcura 2 tipos de hilos: Productores y Consumidores
- Los productores generan datos y los pushean a un buffer de memoria compartido.
- Los consumidores consumen esos datos y los procesan.
Implementación en Rust
#![allow(unused)] fn main() { struct CircularBuffer<T> { buffer: Vec<Option<T>>, capacity: usize, head: usize, tail: usize, size: usize, } impl<T> CircularBuffer<T> { pub fn add(&mut self, element: T) -> bool { if self.size == self.capacity { return false } let i = self.head; self.buffer[i] = Some(element); self.head = (i + 1) % self.capacity; self.size += 1; return true; } pub fn remove(&mut self) -> Option<T> { if self.size == 0 { return None } let i = self.tail; let result = self.buffer[i].take(); self.tail = (i + 1) % self.capacity; self.size -= 1; result } } }
Implementación concurrente
#![allow(unused)] fn main() { struct Data<T> { buffer: Vec<Option<T>>, capacity: usize, head: usize, tail: usize, size: usize, } pub struct CircularBuffer<T> { data: Mutex<Data<T>>, // Se wrappean los datos en un mutex por cuestiones de sincronización // Se usan 2 variables de condición para notificar a cada tipo de hilo not_empty: Condvar, // Para consumidores not_full: Condvar // Para productores } impl<T> CircularBuffer<T>{ pub fn add(&self, element: T) { let mut data = self.data.lock().unwrap(); // Lock the Mutex while data.size == data.capacity { data = self.not_full.wait(data).unwrap(); // Wait until not full } data.buffer[data.head] = Some(element); data.head = (data.head + 1) % data.capacity; data.size += 1; self.not_empty.notify_one(); // notify that is not empty } pub fn remove(&self) -> T { let mut data = self.data.lock().unwrap(); // Lock the mutex while data.size == 0 { data = self.not_empty.wait(data).unwrap(); // Wait until not empty } let result = data.buffer[data.tail].take(); data.tail = (data.tail + 1) % data.capacity; data.size -= 1; self.not_full.notify_one(); // Notify that is not full result.unwrap() } } }
Monitores
Es una primitiva de sincronización que le permite a los threads tener:
- Exclusión mutua
- La capacidad de bloquear la ejecución si no se cumple una condición específica
- Un mecanismo de señalización para despertar threads que están esperando por la misma condición
En resumen, es un Mutex + una CondVar
En Rust no existen los monitores como tal, pero se pueden implementar usando Mutex y Condvar.
En Java sí están built-in, pero no como objeto, sino mediante el uso del keyword synchronized y los métodos wait(),
notify() y notifyAll().
class Account {
double balance;
synchronized public void withdraw(double amount) throws InterruptedException {
if (amount <= 0) return;
while (balance < amount) {
// Wait for enough balance");
wait();
}
balance -= amount;
}
synchronized public void deposit(double amount) {
if (amount > 0) {
balance += amount;
notify(); // Notify that some money have been deposited
}
}
}
Problema de Producer-Consumer en Java con Monitores
public class CircularBuffer<T> {
List<T> buffer;
int capacity, head, tail, size;
public CircularBuffer(int capacity) {
buffer = new ArrayList<>(capacity);
this.capacity = capacity;
}
public synchronized void add(T element) throws InterruptedException {
while (size == capacity) wait();
buffer.set(head, element);
head = (head + 1) % capacity;
size += 1;
notifyAll();
}
public synchronized T remove() throws InterruptedException {
while (size == 0) wait();
var result = buffer.get(tail);
tail = (tail + 1) % capacity;
size -= 1;
notifyAll();
return result;
}
}
Pasaje de mensajes
La idea de los mensajes es evitar la comunicación entre threads mediante la compartición de memoria. Esto lo logra "intentándolo al revés", es decir, compartiendo memoria a través de la comunicación.
Pasar de esto:

A esto:

- En el pasaje de mensajes, la información a compartir es copiada físicamente desde el espacio de direcciones del proceso remitente a los espacios de direcciones de todos los procesos destinatarios
- Esto se logra transmitiendo los datos en forma de mensaje
- Un mensaje es simplemente un bloque de información
Mensajes síncronos vs. asíncronos

| Característica | Síncrono | Asíncrono |
|---|---|---|
| Sincronización | El emisor espera a que el receptor obtenga el mensaje | El emisor continúa sin esperar |
| Control de Flujo | Automático mediante el bloqueo del emisor | Requiere gestión explícita |
| Complejidad | Menor, debido a la coordinación directa | Mayor, debido al manejo indirecto |
| Caso de Uso | Ideal para tareas estrechamente acopladas | Ideal para tareas independientes |
| Rendimiento | Puede ser más lento debido a las esperas | Mayor, ya que no implica esperas |
| Utilización de Recursos | Menor durante las esperas | Mayor, ya que las tareas siguen ejecutándose |
En Rust esto se logra a través de los channels, que vienen de la librería std::mpsc.
#![allow(unused)] fn main() { fn channels_example() { // Create a channel let (sender, receiver) = mpsc::channel(); // MPSC = Multiple Producer, Single Consumer // Spawn a new thread thread::spawn(move || { // Send a message to the channel let msg = "Hello from the spawned thread!"; sender.send(msg).unwrap(); println!("Sent message: '{}'", msg); }); // Receive the message in the main thread let received = receiver.recv().unwrap(); println!("Received message: '{}'", received); } }
#![allow(unused)] fn main() { fn other_example() { // Create a Channel: let (sender, receiver) = mpsc::channel(); // Spawn many threads for tid in 0..10 { let s = sender.clone(); // <--- Clone the sender part thread::spawn(move || { // Send a message to the channel let msg = format!("Hello from thread! {tid}"); println!("Sent message: '{}'", msg); s.send(msg).unwrap(); }); } } }
Algoritmos No Bloqueantes
Hasta ahora bloqueábamos el acceso (Mutex, Condvars, Locks) al resto de hilos para evitar condiciones de carrera.
Con este tipo de algoritmos vamos a tratar de resolver los problemas de los algoritmos bloqueantes, que son:
- Performance: se reduce la performance bajo alta concurrencia, debido a tener que contener el Lock
- Deadlocks
- Uso de recursos: teniendo threads esperando, se puede dar un uso ineficiente de los recursos del sistema.
Ventajas de algoritmos no bloqueantes
- Aumento de eficiencia: operaciones más granulares
- Escalabilidad: operaciones concurrentes sin locks
- Inexistencia de Deadlocks
Variables Atómicas
Rol
- Operaciones atómicas
- Se hacen en un único paso no divisible. No puedo tener el problema del lock porque no lo puedo "partir al medio".
- Integridad de los datos: asegura integridad sin usar locks
- Utilidad:
- Contadores y estadísticas
- Implementaciones concurrentes "lockless" de estructuras de datos
Implementación de un counter usando AtomicInteger
// Sin usar Atomic, deberíamos usar el keyword synchronized.
public class AtomicCounter {
AtomicInteger value = new AtomicInteger(0);
void increment() {
value.incrementAndGet(); // Análogo a un value++
}
int getValue() {
return value.get(); // return value
}
}
Operaciones típicas sobre variables atómicas:
get(),set(int newValue),getAndSet(int newValue)compareAndSet(int expect, int update): compara el valor actual con el esperado y si son iguales lo cambia al nuevo valor.getAndIncrement(),getAndDecrement(),getAndAdd(int delta)getAndUpdate(IntUnaryOperator lambda):IntUnaryOperatores una interfaz funcional que recibe un int y devuelve un int.- Tiene una estructura como esta:
int func(int x)
- Tiene una estructura como esta:
getAndUpdateaplica la función al valor actual y lo actualiza.
En un lenguaje de verdad como Rust
#![allow(unused)] fn main() { struct Counter { value: AtomicU64 } impl Counter { // Initialize a new counter fn new() -> Counter { Counter { value: AtomicU64::new(0) } } // Increment the counter by 1 fn increment(&self) { // Relaxed ordering is often sufficient for simple counters. self.value.fetch_add(1, Ordering::Relaxed); } // Get the current value of the counter fn get(&self) -> usize { self.value.load(Ordering::Relaxed) } } }
Ordering
Es más de bajo nivel, justamente porque Rust permite hacer controles a bajo nivel del procesador.
Cada tipo de ordering tiene diferentes garantías a nivel CPU. Refiere a cómo se ordenan las instrucciones a nivel procesador.
Ordering es un enum que especifica las garantías de visibilidad y orden de las operaciones atómicas entre hilos. En el contexto de algoritmos no bloqueantes, elegir el nivel de Ordering adecuado es clave para asegurar corrección (sin data races) y optimizar rendimiento (minimizando barreras de memoria).
Los órdenes son los siguientes:
-
Sequentially Consistent (
SeqCst): más restrictivo, pero es el más lento. Debe funcionar para TODOS LOS CASOS.- Todas las operaciones atómicas con
SeqCstaparecen en un único orden global, simplificando el razonamiento, pero teniendo como trade-off un mayor costo en barreras de memoria.- Tiene que poner barreras de memoria, justamente para asegurar la consistencia.
- Si se declara un acceso como
SeqCst, ese acceso se queda anclado ahí. - No se pueden reordenar las operaciones de lectura y escritura.
Javalo usa por defecto.
- Todas las operaciones atómicas con
-
AcqRel: combinación de Acquire y Release- Combina Acquire y Release en una operación de lectura-modificación-escritura (por ejemplo, fetch_add), ideal para estructuras de lock-free donde una sola operación hace ambas cosas.
-
Acquire: más restrictivo queRelease, pero menos queAcqRel- Asegura que ninguna lectura/escritura posterior al “load” pueda reordenarse antes de él. Se sincroniza con un
Releasecorrespondiente para “ver” los efectos previos alstore. - Como se usa en conjunto con
Release, lo que se busca (o al menos su caso de uso inicialmente intencionado) es "adquirir y liberar locks".- Lo que intentan ambos orderings es que las secciones críticas del programa no se solapen.
- Todos los accesos posteriores a un
Acquirese van a ejecutar después de este. - No hay ninguna garantía de que se las operaciones anteriores no se reordenen para ejecutarse después.
- El caso de uso de estos 2 en conjunto es bastante simple:
- Adquiero el "lock" al comenzar una sección crítica con
Acquirey cuando termino lo libero usandoRelease(normalmente usando la operación atómicastore).
- Adquiero el "lock" al comenzar una sección crítica con
- Asegura que ninguna lectura/escritura posterior al “load” pueda reordenarse antes de él. Se sincroniza con un
-
Release: más restrictivo queRelaxed, pero menos queAcquire- Garantiza que ninguna lectura/escritura previa al “store” pueda reordenarse después de él. Permite publicar cambios en memoria antes de que otro hilo los observe con un
Acquire. - Todos los accesos anteriores a un
Releasese van a ejecutar antes de este. - No hay ninguna garantía de que se las operaciones posteriores no se reordenen para ejecutarse antes.
- Garantiza que ninguna lectura/escritura previa al “store” pueda reordenarse después de él. Permite publicar cambios en memoria antes de que otro hilo los observe con un
-
Relaxed: menos restrictivo- Solo garantiza la atomicidad de la operación: no impone ningún orden relativo con otras lecturas o escrituras. Útil cuando solo importa el valor atómico, no la sincronización con otros datos.
Operaciones típicas
new(val: i32) -> AtomicI32: lo creaload(order: Ordering) -> i32,store(val: i32, order: Ordering): load lo lee, store le graba un nuevo valorcompare_exchange(expected: i32, new: i32, ...): si encuentra el valor, cambia por el valor del new y devuelve el valor viejo.fetch_add(val: i32, order: Ordering) -> i32,fetch_sub(val: i32, order: Ordering) -> i32: suman y restan, respectivamentefetch_update<F>(set_order: Ordering, fetch_order: Ordering, lambda: F): exactamente igual algetAndUpdatede Java.- Le paso un lambda a aplicar sobre el valor almacenado.
Estructuras de Datos No Bloqueantes
Stack
class Stack<E> {
class Node<E>(val item: E, var next: Node<E>? = null)
private var top: Node<E>? = null
fun push(item: E) {
val newHead = Node(item)
newHead.next = top // Me pueden interrumpir acá, y reemplazar el top
top = newHead
}
// fun pop(): E? { ... }
}
Non-Blocking Concurrent Stack
class ConcurrentStack<E> {
class Node<E>(val item: E, var next: Node<E>? = null)
private var top = AtomicReference<Node<E>?>()
fun push(item: E) {
val newHead = Node(item)
var oldHead: Node<E>?
do {
oldHead = top.get()
newHead.next = oldHead
} while (!top.compareAndSet(oldHead, newHead))
}
fun pop(): E? {
var oldHead: Node<E>? = top.get()
// Siempre que el top sea el mismo que el oldHead, lo reemplazo por el siguiente
while (oldHead != null && !top.compareAndSet(oldHead, oldHead?.next))
oldHead = top.get()
return oldHead?.item
}
}
Queue
class Queue<E> {
class Node<E>(val item: E?, var next: Node<E>? = null)
val dummy = Node<E>(null)
var head = dummy
var tail = dummy
fun enqueue(item: E) {
val newNode = Node(item)
tail.next = newNode
tail = newNode
}
fun dequeue(): E? {
val headNext = head.next ?: return null
head = headNext
return head.item
}
}
Non-Blocking Concurrent Queue
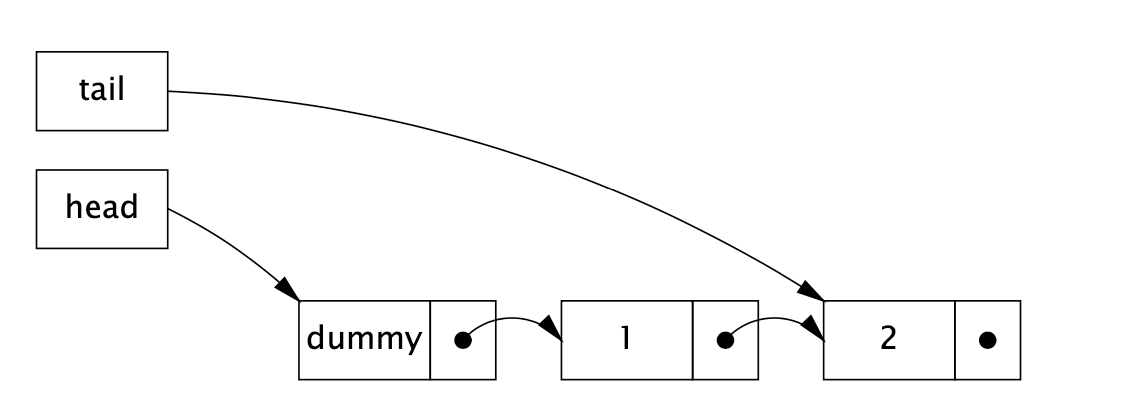 La idea de esta implementación no bloqueante es poder completarle la operación a otro hilo, en caso de que se encuentre en un estado intermedio. Es decir, si tengo la
La idea de esta implementación no bloqueante es poder completarle la operación a otro hilo, en caso de que se encuentre en un estado intermedio. Es decir, si tengo la Queue en el estado de la foto, donde tengo que mover el puntero, otro hilo puede completarme la operación si se da un cambio de contexto .
En el caso del Stack es lo mismo.
import java.util.concurrent.atomic.AtomicReference
class ConcurrentQueue<E> {
class Node<E>(val item: E?, var next: AtomicReference<Node<E>>? = null)
val dummy = Node<E>(null)
val head = AtomicReference(dummy)
val tail = AtomicReference(dummy)
fun enqueue(item: E) {
val newNode = Node(item)
while (true) {
val curTail = tail.get()
val tailNext = curTail.next?.get()
// Check if the tail has not moved, which could've happened given a context switch
if (curTail == tail.get()) {
if (tailNext != null) {
// Queue in intermediate state, advance tail (complete operation)
tail.compareAndSet(curTail, tailNext)
}
// If the next to tail is still the same, update the tail
else if (curTail.next?.compareAndSet(null, newNode) == true) {
tail.compareAndSet(curTail, newNode)
return
}
// Try again
}
}
}
}
Problema ABA
El problema ABA es un problema que ocurre en algoritmos no bloqueantes cuando una variable es leída, luego se modifica y finalmente se vuelve a modificar a su valor original. Esto puede llevar a que un hilo crea que la variable no ha cambiado, cuando en realidad sí lo ha hecho. El valor A cambia a B, y luego vuelve a su valor original A.
No es detectable por operaciones concurrentes, lo cual puede llevar a asunciones incorrectas.
¿Por qué es un problema?
- Las operaciones como
compare-and-swap(CAS) pueden ser "engañadas" para que piensen que no ocurrió ningún tipo de cambio - Esto potencialmente puede causar un comportamiento incorrecto del programa
- Por ejemplo, si poppeo un item de un stack y lo vuelvo a pushear
Soluciones posibles
- Versioning: agregar un contador o un timestamp a la variable, y cada vez que se modifica, se incrementa el
contador.
- ABA se vuelve A1 - B2 - A3.
- En Java se puede usar
AtomicStampedReference, que es una referencia atómica que incluye un "timestamp" o versión.ref.compareAndSet(currentValue, newValue, currentStamp, newStamp);
- En
Rustno puede existir este problema. ¿Por qué?- Por el borrow checker y por la inexistencia del Garbage Collector. No puedo tener una pasada del GC en el medio de la operación.
- Como no hay GC, no puedo limpiar "memoria vieja" ni quedarme apuntando a memoria inexistente.
Pros y Contras de los Algoritmos No Bloqueantes
| Aspecto | Pros | Contras |
|---|---|---|
| Rendimiento | Alto en baja contención. | Puede degradarse en alta contención. |
| Escalabilidad | Mejorada debido a la ausencia de bloqueos. | Limitada por la contención y el costo de reintentos. |
| Interbloqueo | Evitado por completo. | Pueden ocurrir livelocks. |
| Simplicidad | Directo para operaciones simples. | Las operaciones complejas son difíciles de diseñar. |
| Sobrecarga del Sistema | Menor, sin cambios de contexto. | Aumentada por espera activa en contención. |
| Recuperación | Sin estados inconsistentes en fallos de hilos. | Recuperación compleja para mantener la consistencia. |
| Equidad (fairness) | No inherente; puede causar starvation. | Difícil de garantizar la equidad. |
| Modelo de Memoria | Puede ser eficiente con CPUs modernas. | Requiere un entendimiento profundo para evitar problemas. |
Alta contención es cuando múltiples threads frecuentemente intentan acceder y modificar el mismo recurso compartido al mismo tiempo.
Programación Asíncrona
Ejemplo: pedir un café
Aclaración: Cada cajero tiene una máquina de café
- El cliente 1 le pide al cajero un café.
- El cajero hace el café
- El cajero le da el café al cliente 1
- Luego viene el cliente 2 y repite la secuencia
De manera síncrona
Consideraciones
- Mientras se está haciendo el café, el cajero se queda esperando, no puede hacer nada más en ese "tiempo muerto".
- El cliente 2 no es atendido por nadie, ni siquiera se encola el pedido de café mientras el café del cliente 1 se está haciendo.
Manera síncrona con 2 vendedores de café
- Existe un cajero por cliente, entonces se resuelve, pero es más caro (?)
De manera asíncrona

- Se manejan de mejor manera los tiempos "muertos".
- Una vez se pide el café, se manda a hacer, y se pueden seguir recibiendo pedidos.
- Una vez termine el primer café, se lo da al primer cliente, y luego se manda a hacer el segundo
- Esto ahorra 1 cajero y 1 máquina de café, haciéndolo prácticamente en el mismo tiempo que con 2.
Ejecución Asíncrona
- Es la ejecución de una operación de cómputo en otra unidad de cómputo
- No se espera "activamente" a que dicha operación termine, sino que se "manda a hacer en el background"
- Se usan los recursos de manera más eficiente
¿Qué pasa si una función depende del resultado de otra?
fun coffeeBreak() {
val coffee = makeCoffee()
drink(coffee)
chatWithColleagues()
}
fun makeCoffee(): Coffee {
println("Making Coffee")
// Work for some time
return Coffee()
}
fun drink(coffee: Coffee) { ... }
Solución usando Callbacks
fun coffeeBreak() {
// MakeCoffee recibe un lambda para interpretar que no hace falta quedarse esperando a que termine
makeCoffee { coffee ->
drink(coffee)
}
chatWithColleagues()
}
fun makeCoffee(coffeeDone: (Coffee) -> Unit) {
println("Making Coffee")
// Work for some time
val coffee = Coffee()
coffeeDone(coffee)
}
fun drink(coffee: Coffee) { }
makeCoffee()es lanzable en otro thread, tranquilamente.
De Sync hacia Async
Para transformar una función de sync a async (o al menos su firma), se debe:
- No devolver un valor
- Tomar como parámetro una continuación que defina qué hacer una vez devuelto el valor computado.
- Esta continuación en definitiva termina siendo un lambda
fun program(a: A): B {
// Do Something
return B()
}
Se lo transforma en CSP (Continuous Passing Style)
fun asyncProgram(a: A, c: (B) -> Unit) {
// Do Something
c(B())
}
Callback Hell
¿Qué sucede si otro programa depende de que el coffee break haya terminado?
Por ejemplo, una conferencia incluye un coffee break en el medio:
fun coffeeBreak(breakDone: ()->Unit)
fun conference() {
presentation { p1 ->
coffeeBreak {
presentation { p2 ->
endConference(p1, p2)
}
}
}
}
Esto se vuelve ilegible, en definitiva. Escala muy poco. También se lo llama "The doom pyramid"
Futures
Es análogo al Promise de JS/TS. Es una "promesa" o un registro de que se llamó a una función asíncrona, por así decirlo.
Este Future va a devolver un valor en algún momento (cuando quiera usar el valor).
Se propaga "para arriba" en la jerarquía de llamados el cuándo espero por el valor.
Es decir, si yo me quedo esperando por un valor asíncrono (por un Promise), la función donde espero por dicho valor se vuelve asíncrona.
En el caso del ejemplo del café, se hace cuando quiera tomar el café, por ejemplo.
Se intenta pasar de esto:
fun program(a: A): B {}
// CSP
fun program(a: A, k: (B) -> Unit) {}
A esto:
fun program(a: A): Future<B> {}
Currying
Esencialmente, pasamos de esto:
fun program(a: A, k: (B) -> Unit) : Unit {}
- Tomamos un callback como parámetro y lo ejecutamos
A esto:
fun program(a: A): ((B) -> Unit) -> Unit {}
- Devolvemos una función que toma una función que devuelve un
Unit, que termina devolviendo unUnit
Usando Currying (como en Haskell)
add :: Num a => a -> a -> a
add x y = x + y
-- El tipo de `add 10` va a ser:
add 10 :: Num a => a -> a
- En Haskell yo me puedo guardar una función en una variable con un parámetro con un valor "por default", e invocarla en otro lado. Es decir, "invocarla parcialmente".
- Justamente eso es Currying.
Ejemplo del Café usando Future
fun makeCoffeeFuture(): Future<String> {
return CompletableFuture.supplyAsync {
println("Making Coffee")
sleep(2000)
"coffee ${coffeeNumber.incrementAndGet()}"
}
}
// Función principal
fun futureCoffeeBreak() {
val f: Future<String> = makeCoffeeFuture() // Mando a hacer el café
chatWithColleagues() // Me pongo a charlar con mis amigos, o a hacer otra cosa
drink(f.get()) // Me tomo el café una vez listo
}
Future.get()espera a que el valor esté listo para usar, devolviéndolo.- Nótese que
coffeeNumberes unAtomicInteger, justamente para mantenernos en el contexto concurrente.
De manera non-blocking con Futures
import java.util.concurrent.CompletableFuture
fun futureCoffeeBreak() {
val f: CompletableFuture<String> = makeCoffeeFuture()
f.thenAccept { coffee ->
drink(coffee)
}
chatWithColleagues()
}
Manejar errores con Futures
fun futureCoffeeBreak() {
val f: CompletableFuture<String> = makeCoffeeFuture()
f.thenAccept { coffee ->
drink(coffee)
}
.handle { r, exception ->
println("Failed with $exception")
}
chatWithColleagues()
}
Combinando Futures
fun futureCoffeeBreakBlended() {
val f1 = makeCoffeeFuture()
val f2 = makeCoffeeFuture()
val combinedFuture = f1.thenCombine(f2) { result1, result2 ->
"$result1 blended with $result2"
}
combinedFuture.thenAccept { c ->
drink(c)
}
chatWithColleagues()
}
En definitiva, los Futures son Monads
Cabe recordar que un Monad en Haskell es una interfaz para wrappear valores en un contexto, y operar con los valores internos del contexto.
Recordar el tipo Maybe a = Just a | Nothing .
blendedCoffee =
do
coffee1 <- makeCoffeeFuture
coffee2 <- makeCoffeeFuture
return coffee1 ++ " Blended With " ++ coffee2
- Esto es exactamente igual al
Future<T>.thenAccept(Future<T>)
Programación Asíncrona - Continuación
En JavaScript se los llama Promises
let coffeeNumber = 0;
function makeCoffeePromise(): Promise<string> {
return new Promise((resolve) => {
console.log("Making Coffee");
setTimeout(() => { // Equivalente al sleep(2000)
coffeeNumber += 1;
// Al terminar una promesa se llama a este método para devolver un valor
resolve(`coffee ${coffeeNumber}`);
}, 2000);
});
}
function coffeeBreak() {
const f: Promise<string> = makeCoffeePromise();
f.then(coffee => {
drink(coffee);
})
chatWithColleagues();
}
Syntax Sugar para el Async/Await
async function coffeeBreak(): Promise<void> {
const f: Promise<string> = makeCoffeePromise();
chatWithColleagues();
const coffee = await f;
// The code below will be executed when the promised is fullfilled
drink(coffee);
// Promised is propagated!
}
JavaScript es Single-Threaded
- Originado en el browser:
javascriptfue diseñado para manipular el DOM en navegadores web. - El modelo single-threaded previene conflictos e inconsistencias.
- Event Loop:
javascriptopera sobre un modelo basado en eventos. El bucle de eventos verifica tareas como entradas de usuario, solicitudes de red y temporizadores. - Asegura la capacidad de respuesta procesando un evento a la vez.
- Como no puedo levantar threads en el Browser, en JS se tiene que pensar la programación de manera asíncrona
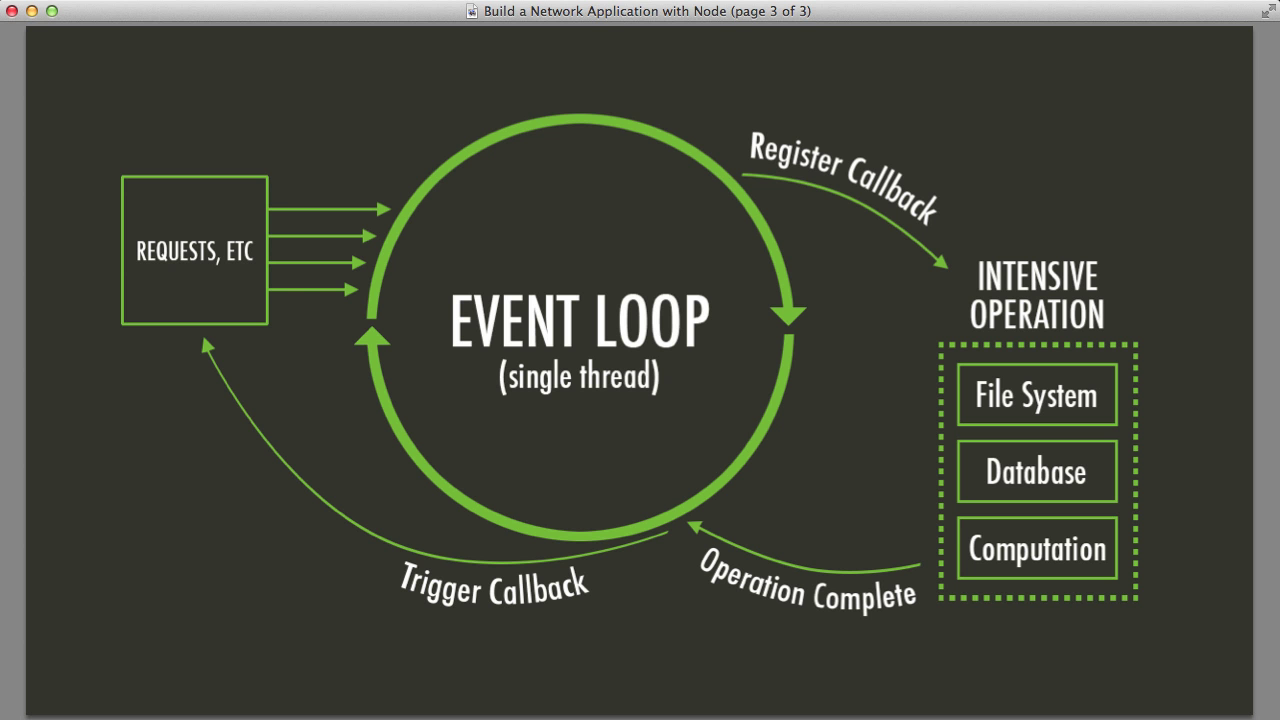
Corutinas
- Subrutinas vs. Corutinas
- Las funciones (o llamados a estas) que conocemos en definitiva son subrutinas
- Subrutinas: 1 entrada, 1 salida
- Corutinas: N puntos de entrada, puede pausarse y reanudarse
- Ceder ejecución
- Las corutinas pueden cederle el control de vuelta a los "callers", que son quienes la invocan
- Reanudan desde el punto donde las pausaron
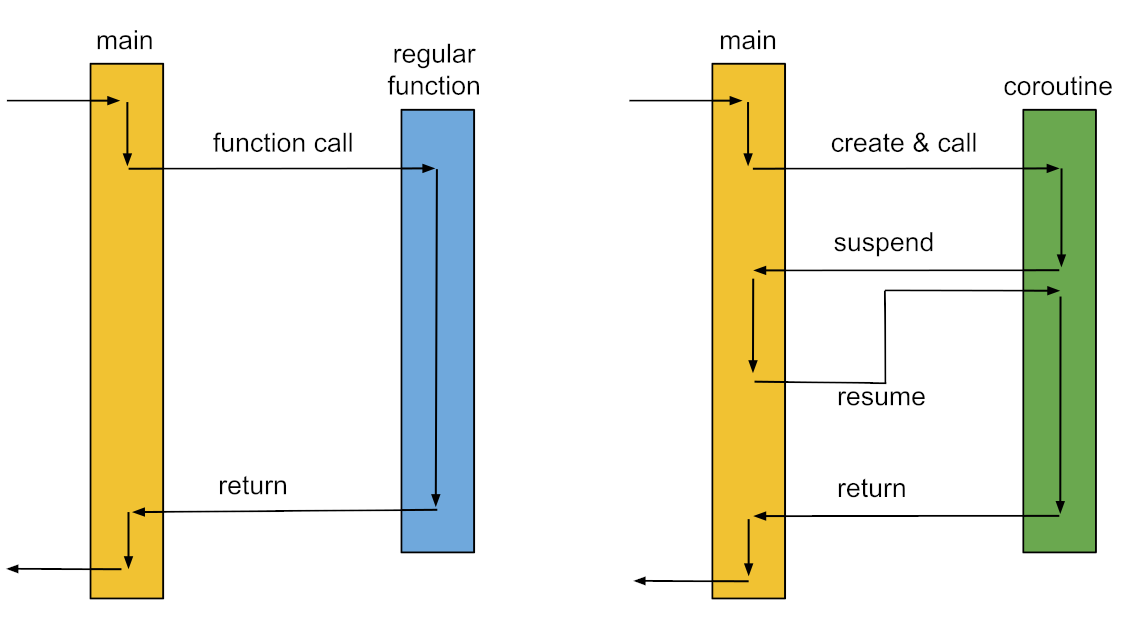
Ejemplo del café con corutinas
suspend fun makeCoffee(): String {
println("Making Coffee")
delay(2000) // Using delay from kotlinx.coroutines instead of Thread.sleep
return "coffee ${coffeeNumber.incrementAndGet()}"
}
fun coffeeBreakWithCoroutines() = runBlocking {
// Los launch sólo pueden invocarse dentro de una corutina
// `runBlocking` dispara una corutina "bloqueante",
// que bloquea el thread en el que se ejecuta hasta que termine la operación
launch {
val coffee = makeCoffee()
drink(coffee)
}
chatWithColleagues()
}
suspendindica que es una función que se puede suspender, ergo, es unacoroutine- Una corutina puede llamar otra dentro suyo
- Por adentro pueden alocarlas distintos threads
- Si la aloca el mismo thread, el flujo se sigue de la siguiente manera:
- Va al
Launch, empieza la corutina - Empieza a ejecutar
- Hace un yield en el delay de
makeCoffee()e invocachatWithColleagues() - Vuelve a
makeCoffee(), devuelve el valor, y ejecuta eldrink(coffee)de lamain routine
- Va al
runBlockinghace que la función se ejecute en su totalidad- En una corutina se puede ceder el control usando
returnoyield.returnes implícito,yieldes explícito
Las corutinas están pensadas para que, en un mismo hilo, yo pueda tener una ejecución paralela que se realiza con un interleaving.
Es una forma colaborativa de tener concurrencia, similar a los virtual threads.
En runtime (en el caso particular de Kotlin) se permite tener un dispatcher, al que se le pueden alocar a varios threads.
El dispatcher te permite que una corutina no necesariamente se quede esperando.
Beneficios
- Código más simple
- Código asíncrono que parece síncrono
- Más fácil de leer y mantener
- Concurrencia
- Se pueden manejar múltiples tareas de manera concurrente
- Evita la complejidad de threads
- Muy liviano
Concurrencia liviana
fun main() = runBlocking {
for (i in 0..50_000) { // ejecuto la misma corutina 50.000 veces
launch {
println("Hello $i!")
delay(5000L)
}
}
}
Si no estuviera el launch, tardaría aproximadamente 250.000 segundos
Como existe el launch, tarda un poquito más de 5 segundos (por lo que tarda en imprimir, también) por el cambio entre las rutinas, ya que hace el "salto" justo antes del delay.
Se interrumpe y salta a la siguiente corutina justo antes del llamado al delay.
Secuencias (colecciones Lazy)
No tiene que ver de manera directa con concurrencia, pero es la forma más pura de escribir una corutina.
El yield está explícito.
val fibonacciSeq: Sequence<Int> = sequence {
yield(1)
yield(1)
var a = 1;
var b = 1
while (true) {
val result = a + b
yield(result)
a = b; b = result
}
}
fun main() = fibonacciSeq.take(10).forEach { print("$it ") }
sequenceinvoca una lambda y la irá llamando a medida que se lo pida.- Producen elementos a pedido (lazy)
- Esa lambda es una corutina, en definitiva.
- Puedo interrumpir la secuencia usando
seq.take(N).
- Si no se usa con
sequence, se debería armar usando unIterator yieldfunciona parecido areturnpero no finaliza la corutina. Simplemente la interrumpe.- Cuando se vuelve a llamar la corutina, sigue desde el punto siguiente al
yield.
- Cuando se vuelve a llamar la corutina, sigue desde el punto siguiente al
Ejecución paralela vs. secuencial
suspend fun doSomethingUsefulOne(): Int {
delay(1000L); return 13
}
suspend fun doSomethingUsefulTwo(): Int {
delay(1000L); return 29
}
fun main() = runBlocking {
val time = measureTimeMillis {
val one = doSomethingUsefulOne()
val two = doSomethingUsefulTwo()
println("The answer is ${one + two}")
}
println("Completed in $time ms")
}
Como estoy pidiendo un resultado (la suma de ambos resultados de las corutinas), se ejecutará todo secuencial
Paralela
fun main() = runBlocking {
val time = measureTimeMillis {
val one = async { doSomethingUsefulOne() }
val two = async { doSomethingUsefulTwo() }
println("The answer is ${one.await() + two.await()}")
}
println("Completed in $time ms")
}
Clavarle el async fuerza que se te vaya una de las 2 corutinas a otro thread ya que, justamente, crea una corutina.
Es "paralelo" porque los procesos se hacen en paralelo, pero termina siendo una ejecución secuencial del main porque
tenés que esperar los resultados (dados los .await())
Threads vs. Fibers vs. Corutinas
| Concepto | Estado | Ejecutado por | Unidad de suspensión |
|---|---|---|---|
| Hilo (Thread a nivel S.O) | Stack de modo usuario + Stack de modo kernel + contexto | Scheduler del sistema operativo | Hilo completo; la CPU queda libre para ejecutar otros hilos |
| Fiber (User-Mode-Thread, Virtual Thread) | Stack de modo usuario + contexto | Algún hilo | Fiber; el hilo subyacente queda libre para ejecutar otras tareas |
| Corutina | Variables locales + contexto | Algún hilo o fiber | Corutina; el hilo o fiber subyacente queda libre para ejecutar otras corutinas o tareas |
Lo único que la corutina precisa mantener como estado son las variables que está utilizando, que son las propias.
Actors
Lo mejor para actores es Erlang, pero vemos todo en Scala con una librería que se llama Akka por cuestiones de simplicidad
Sincronización tradicional
Varios threads se pisan entre sí. Esto se resuelve:
- Demarcando regiones de código con semánticas para "no molestar"
- Asegurando que el acceso a estado compartido sea protegido
En Scala todos los objetos tienen un lock: synchronized {...}
class BankAccount {
private var balance = 0
def deposit(amount: Int): Unit = synchronized {
if (amount > 0) balance = balance + amount
}
def withdraw(amount: Int): Int = synchronized {
if (0 < amount & amount <= balance) {
balance = balance - amount
balance
} else throw new Error("insufficient funds")
}
}
Qué es un Actor?
Lo que pretende el modelo de actores es pensar las interacciones de un sistema como personas interactuando entre sí. Lo modela como personas que envían mensajes entre sí.
Un actor es:
- Un objeto con identidad
- Que tiene comportamiento
- Y solo interactúa usando pasaje de mensajes asincrónico
Es OOP + Mensajes, en definitiva. Forzado dentro de un sistema donde todo tiene que seguir este estándar.
Actor trait
// Se define un type alias llamado 'Receive'
/* Representa una función que maneja los mensajes que se le envían a un Actor
- Es una PartialFunction, lo que significa que puede no manejar cualquier posible input
- Toma un mensaje de cualquier tipo, y no devuelve nada ('Unit')
*/
type Receive = PartialFunction[Any, Unit]
Receive es esencialmente una función que recibe cualquier parámetro y no devuelve nada.
¿Por qué PartialFunction?
Si las funciones matemáticas están bien definidas, deberían tener dominio para todos los reales. Si no, tienen "agujeros" en el dominio.
Trasladado a Scala y al contexto de Actors, que sea una función parcial quiere decir que hay valores que no soporta. Esto le sirve al lenguaje para hacer algún tipo de chequeo.
// Se define un trait llamado Actor
trait Actor {
// Este método abstracto DEBE ser implementado por el Actor en cuestión
// Define la lógica con la que se reciben los mensajes (qué se hace cuando se recibe un mensaje)
def receive: Receive
}
- Los
traitsen Scala son equivalentes a las interfaces de Java, o a lostraits(justamente) de Rust receivees un lambda.
Un Actor Simple
// La clase 'Counter' extiende el trait 'Actor' e implementa el método 'receive'
class Counter extends Actor {
// Variable mutable (contador actual)
var count = 0
// El método 'receive' define cómo el actor maneja los mensajes que le llegan
def receive = {
// Si el mensaje es el string "incr", incrementa el contador
case "incr" => count += 1
// El resto de mensajes se ignoran, porque la PartialFunction no define un caso para estos.
// Si se quiere definir un caso default, se usa el underscore (_)
}
}
Exponiendo el estado
class Counter extends Actor {
var count = 0
// Añadir el mensaje para get
def receive = {
case "incr" => count += 1
case ("get", customer: ActorRef) => customer ! count
}
}
!es el operador para mandar mensajes enAkkaAkkaes la librería deScalapara actores
customeres unActorRef- get le manda el count a un actor que puede recibir un entero (
int) en su métodoreceive
- get le manda el count a un actor que puede recibir un entero (
Ejemplo para apoyar lo anterior
// Es un actor simplón que recibe el contador y lo imprime
class Printer extends Actor {
def receive = {
// Que el nombre del parámetro sea el mismo en un actor y otro es casualidad
// Es buena práctica pero no es necesario
case count: Int => println("Printer received count: " + $count)
}
}
Uso:
// Inicializar el sistema de actores (posteriormente se ve cómo)
// Supongamos que counter y printer ya está inicializados anteriormente
counter ! "incr"
counter ! "incr"
counter ! "incr"
// Se le pide al contador que envíe su valor actual al printer
counter ! ("get", printer)
¿Cómo se mandan los mensajes?
trait Actor {
// 'self' es una referencia implícita a su propia instancia de actor
// Le permite al actor referirse a su propia dirección sin pasarla de manera explícita
implicit val self: ActorRef
// 'sender' nos da acceso a quien envía el mensaje que actualmente está siendo procesado
// Esto es útil para responder mensajes - se puede hacer `sender ! reply`
def sender: ActorRef
// ...
}
Qué es un ActorRef?
abstract class ActorRef {
// El "bang" o ! es la manera principal de enviarle un mensaje a otro actor
// - 'msg: Any': se puede mandar cualquier tipo de mensaje
// - 'implicit sender': el sender se pasa de manera implícita, de tal manera que el receptor sabe quién lo mandó
def !(msg: Any)(implicit sender: ActorRef = Actor.noSender): Unit
// `tell` es un alias para el !
// Hace que el llamado sea más explícito al pasar tanto el mensaje como el remitente
def tell(msg: Any, sender: ActorRef) = this.!(msg)(sender)
}
- En definitiva, un
ActorRefes una referencia utilizable hacia unActor- Se suelen pensar como la "dirección de mail" del actor en cuestión
- Justamente como el sender está implícito, si no le paso nada me lo mando a mí mismo
implicites syntax sugar de Scala
Usando el Sender
class Counter extends Actor {
var count = 0
def receive = {
case "incr" => count += 1
case "get" => sender ! count
}
}
Un ejemplo para verlo de afuera sería:
class Multiplier extends Actor {
def receive = {
case x: Int => if (x < 10) self ! (x * 2)
case ("ask", customer: ActorRef) => customer ! "get"
}
}
// Suponer multiplier ya inicializado
counter ! "incr"
counter ! "incr"
multiplier ! ("ask", counter) // --> esto va a multiplicar por 2 recursivamente de manera infinita el valor de counter
// El flujo va a ser multiplier ask => counter get => le mando count al multiplier => Multiplier se llama a sí mismo recursivamente hasta que sea mayor a 10
Nota: este ejemplo me lo crafteé yo
Interactuando con el Printer
class Printer extends Actor {
def receive = {
// Acá muestra que cuando le llega un mensaje cualquiera lo imprime
// y después le manda al sender un mensaje con un re texto
case count: Int =>
// Imprimir el count que le llegó
println(s"[${self.path.name}] received count: $count")
// Le mando un ACK a quien me lo envió
// `sender` me da acceso a la referencia de quien sea que me mandó el mensaje en primer lugar
sender ! s"Acknowledged count $count from ${self.path.name}"
}
}
class CounterClient(printer: ActorRef) extends Actor {
def receive = {
// Este actor recibe el ack del Printer
case ack: String => println(s"[${self.path.name}] got reply: $ack")
}
// Este método se ejecuta on init del objeto
override def preStart(): Unit = {
// envía un número al printer usando '!' (asynchronous fire-and-forget)
// 'self' se va a usar implícitamente como sender
// Esta instancia de CounterClient va a ser el sender la primera vez
printer ! 42
// Le mando otro número de manera explícita usando 'tell' y 'self'
printer.tell(99, self)
}
}
- En un programa estándar con estos 2 objetos instanciados:
- se le manda al printer un 42
- luego se le manda un 99
- en ambos casos con el CounterClient como Sender
Actor Context
En el modelo de los actores, el contexto es el ambiente donde el actor está corriendo. Dentro de lo que puede hacer, le puedo pedir al contexto:
- Crear otros actores
- Cambiar su comportamiento de manera dinámica
- Acceder a referencias de sí mismo y de los remitentes
- "Frenarse" a sí mismo o a otros actores
El actor describe el comportamiento, la ejecución la realiza su ActorContext
En código
trait ActorContext {
// Me permite actualizarle el receive al actor actual
def become(behavior: Receive, discardOld: Boolean = true): Unit
// Vuelve para atrás al último comportamiento guardado en caso de que
// discardOld era `false` en el llamado del become
def unbecome(): Unit
}
- Otros métodos útiles del contexto pueden ser:
actorOf(...)para instanciar actores hijosstop(...)para frenar un actorself,sender,parent,children
Ejemplo
class ToggleActor extends Actor {
def on: Receive = {
case "switch" =>
println("Turning off...")
context.become(off)
}
def off: Receive = {
case "switch" =>
println("Turning on...")
context.become(on)
}
// Este es el comportamiento inicial, arranca prendido
def receive = on
}
Functional Counter
Se puede definir a la clase Counter de manera funcional (sin variables mutables):
class Counter extends Actor {
def counter(n: Int): Receive = {
case "incr" => context.become(counter(n + 1))
case "get" => sender ! n
}
def receive = counter(0)
}
- Se crea un lambda con un parámetro preseteado
- En el fondo guarda el valor del parámetro en la definición del lambda
- Cuando se instancia el Counter, n = 0
Crear y detener actores
Definiendo el trait de ActorContext...
trait ActorContext {
// Se spawnea un actor hijo del actor actual
// - 'p' : es un objeto `Props`, define el tipo de actor y los parámetros de su constructor
// - 'name': es un nombre único para este nuevo actor dentro del contexto actual
def actorOf(p: Props, name: String): ActorRef
// Se frena o termina el actor
def stop(a: ActorRef): Unit
}
Aplicación completa de actores
class CounterMain extends Actor {
// Create an instance of the Counter actor as a child of this actor
val counter: ActorRef = context.actorOf(Props[Counter], "counter")
// Send some increment messages to the counter
counter ! "incr"
counter ! "incr"
counter ! "incr"
// Ask the counter to send its current value back (reply goes to this actor)
counter ! "get"
// This actor handles the reply from the counter
def receive: Receive = {
case count: Int =>
println(s"Count was $count") // Print the count
context.stop(self) // Stop this actor (ends the app)
}
}
El main sobre el que corre:
object CounterMainApp extends App {
// Create the actor system
val system = ActorSystem("CounterSystem")
// Create the main actor that orchestrates everything
system.actorOf(Props[CounterMain], "main")
// The system will shut down after the CounterMain actor stops (not shown here)
// For a clean shutdown, you could use CoordinatedShutdown or watch termination manually
}
¿Qué es el modelo del que venimos hablando?
Siempre que un actor reciba un mensaje puede hacer cualquier combinación de las siguientes acciones:
- Crear mensajes: comunicarse con otros actores de manera asíncrona
- Crear actores (hijos de sí mismo): crear actores hijos para delegar trabajo o estructurar el sistema de manera jerárquica
- Cambiar su comportamiento para próximos mensajes de manera dinámica
Los actores encapsulan tanto estado como comportamiento, permitiendo concurrencia sin locks y segura al reaccionar a los mensajes.
Encapsulación de los Actores
No tienen getters ni setters, se debe manejar su estado a través de mensajes
Están aislados: no se puede acceder al estado ni a su comportamiento de manera directa, sólamente interactuando desde el
lado de otro actor (via pasaje de mensajes usando direcciones conocidas, sus ActorRef)
- Cada actor conoce su referencia (
self) - Crear un actor devuelve su propia referencia.
- Las referencias (o direcciones) se pueden compartir y pasar entre mensajes (ej: usando
sender)
Este modelo fuerza aislamiento y previene problemas de memoria compartida como condiciones de carrera
Orden de evaluación de los Actores
-
Cada actor dentro de sí mismo es single-threaded, con lo cual los mensajes van llegando secuencialmente
- Llamar a
context.becomecambia su comportamiento frente al próximo mensaje - Cada mensaje es atómico, ya que no existe el interleaving entre actores
- Llamar a
-
Los actores procesan un mensaje a la vez
- No hay overlap entre manejadores de mensajes
- Los cambios de comportamiento aplican al próximo mensaje
- La atomicidad asegura actualizaciones seguras del estado local
Es muy parecido al
synchronizedde Java, solo que sin bloqueo; en su lugar se encolan los mensajes.
Trade-Offs
- Te atás al asincronismo, no tenés respuestas inmediatas
- No existe memoria compartida (esto es importante)
- Cada actor tiene sus propias variables y espacios de memoria alocados
- Solo se comparte memoria a través de mensajes
- Añade una capa de complejidad importante
- Es más difícil de debuggear
Esto lo anoté en base a lo que me dijeron los profes
Actores - Parte II
En qué beneficia hacer Garbage Collections atómicos, chiquitos y periódicos contra una pasada grande?
- Dependiendo de si las variables se alocan en el Heap o en el Stack (en el caso de la barrida enorme):
- Si se alocan en el Stack, todo pelota, no pasa natalia
- Si se alocan en el Heap, hay que revisar (como si fuese un grafo, porque justamente se aloca un puntero a ese
elemento), el cual puede terminar teniendo más referencias, te comés el garrón de revisar toda la memoria
- Justamente como tenés que revisar toda la memoria en estos casos, se ralentiza el programa
- Traducido a un programa interactivo o In Real Time, ves la ruedita cargando, o se te caga la performance, en definitiva
En este sentido, como el Garbage Collection en el modelo de Actores se hace por actor, se cae en el caso más optimizado, o mejor dicho, dejás de tener todas las complicaciones que tiene el primer caso.
Bank Account - Revisitado con actores
object BankAccount {
case class Deposit(amount: BigInt)
case class Withdraw(amount: BigInt)
case object Done
case object Failed
}
- Acá no estamos definiendo un actor, sino un objeto/clase
- Las
case classesson clases que se pueden declarar de manera corta, como si fuese un enum- Son análogos a los
RecordsdeJava
- Son análogos a los
class BankAccount extends Actor {
var balance: BigInt = BigInt(0)
def receive: Receive = {
case Deposit(amount) =>
balance += amount
sender ! Done
case Withdraw(amount) if amount <= balance =>
balance -= amount
sender ! Done
case _ => sender ! Failed
}
}
- El pattern matching se hace por el tipo de objeto, en este caso
- El if en el caso del
Withdrawhace que falle (o lo deriva al caso default, mejor dicho) siamountes mayor abalance
Colaboración de actores
- La idea es imaginarse cada actor como una persona
- O cada acción o actividad como actores
Dependiendo del caso, usamos un approach u otro
Puedo modelar un actor encargado de hacer las transferencias bancarias, que interactúe entre cuentas bancarias.
Es decir, uso un actor intermedio
object WireTransfer {
case class Transfer(from: BankAccount, to: BankAccount, amount: BigInt)
case object Done
case object Failed
}
class WireTransfer extends Actor {
def receive: Receive = {
case Transfer(from, to, amount) =>
from ! BankAccount.Withdraw(amount)
context.become(awaitWithdraw(to, amount, sender))
}
def awaitWithdraw(to: ActorRef, amount: BigInt, client: ActorRef): Receive = {
case BankAccount.Done =>
to ! Deposit(amount)
context.become(awaitDeposit(client))
case BankAccount.Failed =>
client ! Failed
context.stop(self)
}
def awaitDeposit(client: ActorRef): Receive = {
case BankAccount.Done =>
client ! Done
context.stop(self)
case BankAccount.Failed => // Este caso lo escribí yo, que dijo Emilio que faltaba en el slide
client ! Failed
context.stop(self)
}
}
- No puedo confirmar si la transferencia salió bien o no hasta que efectivamente me llegó el Withdraw de la primera cuenta
- Justamente, me quedo esperando el Withdraw, y una vez me llegó lo mando a la cuenta de destino
- Es decir, lo deposito al destinatario.
- Si el depósito sale bien, lo propago para arriba y freno el actor, o lo elimino, justamente para que sea atómico todo.
- Si falló hago 2 cosas:
- Propago el fallo
- Freno al actor (esto en realidad se puede resolver de otra manera)
- El depósito en principio no debería fallar, porque no depende de si tenés saldo o no
- Pero se modela (por las dudas?)
Garantías de entrega de mensajes
- Si no se piden explícitamente, las garantías de entrega son más bajas
- "Todo se puede ir al diablo en cualquier momento" a.k.a. "Let it crash"
- La idea es que pienses que, como todo puede fallar, te asegures de que dejás el sistema en un estado consistente
- La entrega del mensaje requiere disponibilidad eventual del canal y del receptor
Garantías
Dependiendo del caso se implementa uno u otro protocolo, y un manejo de estados diferentes.
- at-most-once: enviar el mensaje lo entrega 0 o 1 veces
- Puede no llegar
- at-least-once: enviar el mensaje entrega
1 - Nveces el mensaje- Llega una o más veces
- exactly-once: procesar sólo la primera recepción entrega el mensaje exactamente 1 vez
- Este approach es muchísimo más burocrático
- Es más caro en recursos y en implementación
- Tenés que:
- Recibir el mensaje efectivamente
- Mandar un
ACKpara notificarle al otro que recibiste el mensaje - Que el otro te mande un
ACKpara notificarte que recibió elACK
Mensajería confiable
Los mensajes soportan confiabilidad:
- Todos los mensajes se pueden persistir
- Pueden incluir correlation IDs únicos
- Se puede reintentar hasta que la entrega sea exitosa
La confiabilidad solo puede ser asegurada por acknowledgement a nivel lógica de negocio
En el caso de la transferencia...
Para volverla confiable habría que:
- Registrar actividades del
WireTransfera almacenamiento persistente - Hacer que cada transferencia tenga un ID único
- Añadirle un ID al Withdraw y al Deposit
- Almacenar IDs de acciones completadas en la
BankAccount
Orden de mensajes
Si un actor manda varios mensajes al mismo destinatario, no van a llegar desordenados (esto es específico de Akka)
Diseñando un modelo de actores
- Imagínate darle una tarea a un grupo de personas y dividirla en partes
- Considerá que el grupo puede ser muy grande
- Empezá a pensar como las personas asignadas a las diferentes tareas van a comunicarse entre sí
- Considerá que cada "persona" puede ser fácilmente reemplazable
- Dibujá un diagrama de cómo se va a dividir la tarea, incluyendo líneas de comunicación
Los problemas de escalabilidad de este tipo de diseños se dan si se quiere hacer un Actor "superpoderoso",
o pensando que hay un actor irreemplazable
En un sistema de actores bien diseñado, el grafo no debería ser muy complejo. Si tengo muchas vueltas para atrás estoy haciendo algo mal
En el caso de las transferencias, se nos complejiza por las vueltas para atrás, porque es un problema transaccional con el que hay que tener cuidado
Let It Crash
Si uno quiere hacer un diseño razonable con actores, tiene que pensar por este lado
Abrazar el fallo antes que prevenirlo (?)
- Se esperan errores en sistemas distribuidos
- La Programación Defensiva lleva a complejidad y rigidez
- El modelo de actores aísla fallas: los actores crashean y restartean sin afectar otros
En Erlang/Elixir: "fail fast, recover quickly"
Por qué funca Let It Crash?
- Cada actor está aislado: un crasheo afecta a un único actor
- Si falla un actor, su supervisor puede reiniciarlo o manejarlo
- Cuando se creaba un actor, el de arriba era "responsable" por los de abajo
- Se crea una jerarquía
- Por ejemplo, en caso del fallo de un hijo, el padre lo puede restartear a manopla
- No se necesita un manejo de errores complejo dentro de cada actor
Árboles de supervisión
Como los actores pueden supervisar a sus hijos:
- Los supervisores detectan fallos y aplican estrategias de reinicio
- Los fallos no propagan el caos, sino que se contienen
- La estructura forma una jerarquía de supervisión (en forma de árbol)
val child = context.actorOf(Props[Worker], "worker")
Los árboles reflejan modularidad y controlan el alcance de la recuperación
Estrategias de supervisión
Las estrategias más comunes incluyen:
Restart: recrear el actor de 0Resume: ignorar el fallo y continuarStop: terminar al actor, eliminarloEscalate: propagar el error hacia arriba
override val supervisorStrategy =
OneForOneStrategy() {
case _: ArithmeticException => Resume
case _: NullPointerException => Restart
case _: Exception => Stop
}
Diseñando en torno a la resiliencia
Tips para diseñar:
- Componer el sistema de actores chiquitos, que puedan crashear tranquilamente
- Asignar supervision claramente: quién es responsable de quién?
- Evitar try-catches complejos: lo mejor es apoyarse en el esquema de supervisión
- La estructura sigue límites en base a los posibles fallos
La resiliencia es una decisión de arquitectura, no un pensamiento posterior
Material de Práctica
Aquí encontrarás los ejercicios y material de práctica.
Parciales
Temas a evaluar
- Teoría del principio (introducción a prog concurrente, scheduling, etc.)
- Thread Programming
- Paralelismo
- Exclusión Mutua
- Abstracciones de concurrencia I (Locks, Deadlocks, Livelocks, Semáforos)
- Abstracciones de concurrencia II (CondVars, Monitores, Pasaje de mensajes con Channels)
Notas
- Esta práctica incluye los ejercicios que vimos en clase. También están subidos y resueltos los ejercicios del parcial y del primer recuperatorio.
Ejercicios
Parciales
Link al código fuente de esta sección
Consignas

Resolución
Primer ejercicio - Airport
#![allow(unused)] fn main() { use std::sync::{Condvar, Mutex}; pub struct Runway { id: u32, is_occupied: bool, } impl Runway { pub fn new(id: u32) -> Runway { Runway { id, is_occupied: false, } } } pub struct Plane { id: u32, } impl Plane { pub fn new(id: u32) -> Plane { Plane { id } } } pub struct Airport { runways: Mutex<Vec<Runway>>, can_land: Condvar, } impl Airport { pub fn new(runway_vec: Vec<Runway>) -> Airport { let runways = Mutex::new(runway_vec); let can_land = Condvar::new(); Airport { runways, can_land } } pub fn request_runway(&self) -> u32 { let mut runways = self.runways.lock().unwrap(); while runways.iter().all(|r| r.is_occupied) { runways = self.can_land.wait(runways).unwrap(); } let free_runway: &Runway = runways.iter().find(|r| !r.is_occupied).unwrap(); free_runway.is_occupied = true; free_runway.id } pub fn release_runway(&self, runway_id: u32) { let mut runways = self.runways.lock().unwrap(); let mut occupied_runway = runways.iter().find(|r| r.id == runway_id).unwrap(); *occupied_runway.is_occupied = false; self.can_land.notify_one(); } } }
- Se wrappea el vector de pistas (
Vec<Runway>) en unMutexpara tener control por exclusión sobre las pistas de aterrizaje. - Se le suma una
Condvarpara señalizar que pueden aterrizar que, en conjunto con el mutex sobre las pistas, forma unMonitor.
Segundo ejercicio - Priority Landing
Supongamos que queremos que algunos aviones tengan una cierta prioridad de aterrizaje. La idea es que cuando una pista se libere, sólo se le notifica al avión esperando con mayor prioridad.
¿Cómo podemos cambiar la implementación para soportar este comportamiento?
Respuesta:
Lo ideal sería asignarle una Condvar a cada avión, removiendo la del aeropuerto, para así notificarle a los aviones de manera individual. En cuanto a la prioridad, se le asigna un entero que represente esa prioridad (ej: struct Plane { id: u32, can_land: Condvar, priority: i32 })
Además, el aeropuerto tiene que tener una referencia a los aviones en espera (con un Mutex<Vec<Plane>>).
Seguido de esto, necesitamos modificar la firma de request_runway para que tome como argumento un avión. Si todas las pistas están ocupadas, se agrega al avión al vector de aviones en espera, solicitando primero el lock sobre el Mutex de aviones. Además, se queda esperando a su condvar, la cual actúa sobre el mutex de pistas.
Por último, modificamos release_runway para que, al final, busque en el vector de aviones el avión con mayor prioridad y notifique a su condvr, despertando el thread sobre el que se lo usa, y sacándolo del vector.
En "pseudocódigo" sería:
#![allow(unused)] fn main() { fn request_runway(plane: Plane){ let mut runways = self.runways.lock().unwrap(); let mut waiting_planes = self.planes.lock().unwrap(); while runways.iter().all(|r| r.is_occupied) { runways = plane.can_land.wait(runways).unwrap(); if(!waiting_planes.contains(plane)){ waiting_planes.push(plane); } } let free_runway: &Runway = runways.iter().find(|r| !r.is_occupied).unwrap(); free_runway.is_occupied = true; free_runway.id } fn release_runway(&self, runway_id: u32) { let mut runways = self.runways.lock().unwrap(); let mut occupied_runway = runways.iter().find(|r| r.id == runway_id).unwrap(); *occupied_runway.is_occupied = false; let planes = self.planes.lock().unwrap(); planes.sort_by(|p1, p2| p1.priority.cmp(p2.priority)) let waiting_plane = planes.first(); waiting_plane.can_land.notify_one(); planes.remove(waiting_plane); } }
En el caso anterior (punto 1), todo lo que teníamos era una manera de señalización aleatoria, la cual depende de la implementación de la Condvar o del Scheduler del S.O.
Con este approach, podremos notificar a un sólo avión a la vez, y de manera arbitraria siguiendo el esquema de prioridad definido.
Tercer ejercicio - Waiting Time Tracking
Supongamos que queremos asignar la prioridad de aterrizaje a los aviones que más esperaron.
Necesitamos trackear cuánto tiempo espera cada avión. Una resolución de 5 minutos es suficiente.
¿Qué tenemos que modificar de la implementación para lograr esto?
Respuesta:
Tomamos los cambios del punto anterior con las siguientes modificaciones:
- En lugar de usar el método
waitde laCondvar, usamoswait_timeout, con una duración de 5 minutos - Arrancamos con todos los aviones con prioridad 0
- Con cada timeout, sumamos 5 a la prioridad del avión
De esta manera, la prioridad se maneja en función de tiempo de espera
Recuperatorio Primer Parcial 2025
1) Deadlock y livelock (qué son y ejemplos)
2) V o F “Two processes can execute their critical sections simultaneously if they use binary semaphore”
3) Barber Shop
// Each client takes a seat or leaves struct BarberShop { capacity: usize, //... } impl BarberShop{ //... } fn main() { let shop = Arc::new(BarberShop::new(3)); let mut handles = Vec::new(); for i in 0..10 { let shop = Arc::clone(&shop); handles.push(thread::spawn(move || { thread::sleep(Duration::from_millis(i * 100)); if shop.enter(i as usize){ shop.wait_for_turn_and_cut(i as usize); } })); } for h in handles { h.join().unwrap(); } }
4) Manejar mas barbers
5) Manejar clientes VIP
Resolución
Nota: no estuve en este recu, entonces no sé qué consideraciones especiales tuvieron los docentes. Tomen la resolución con pinzas. Si algo no les hace sentido, díganme.
1) Deadlock y livelock (qué son y ejemplos)
Un deadlock es una condición de bloqueo en el contexto de la programación concurrente, la cual consta de 2 o más hilos/procesos esperando por la liberación de recursos de manera mutua, bloqueando completamente la ejecución del programa.
Ejemplo
Tengo 2 personas (p1 y p2) queriendo escribir; en una base de datos:
p1comienza a escribir el recursoA, lockeándolo.p2comienza a escribir el recursoB, lockeándolo.- Previo a finalizar su operación de escritura,
p1quiere leerB. Como está lockeado porp2, no puede avanzar - A su vez,
p2quiere leerA. Como está lockeado porp1, no puede avanzar.
De esta manera, la ejecución del programa se bloquea por completo.
En cuanto al livelock, también es una condición de bloqueo, pero consta de que 2 procesos/hilos se queden esperando por que otro proceso avance / cambie de estado. No se frena la ejecución como tal, pero los procesos quedan cambiando constantemente de estado, sin poder avanzar.
Ejemplo
Tengo un matrimonio (p1 y p2) queriendo comer, pero sólo hay 1 cuchara.
Ambos quieren que el otro coma primero por cuestiones de educación, entonces se produce la siguiente secuencia:
p1ve la cuchara, la quiere agarrar, pero ve ap2que no tiene, y le dice que coma primero.p2ve la cuchara, la quiere agarrar, pero ve ap1que no tiene, y le dice que coma primero.
Esto se repite infinitamente, sin ningún avance.
2) V o F “Two processes can execute their critical sections simultaneously if they use binary semaphore”
Esto es falso. Justamente la sección crítica no se va a poder ejecutar en paralelo si el recurso es lockeado por el otro proceso. Precisamente porque el semáforo binario es análogo a un Mutex.
3) Barber Shop
#![allow(unused)] fn main() { struct BarberShop { capacity: usize, clients: Mutex<VecDeque<usize>>, can_cut: Condvar } impl BarberShop{ fn new(capacity: usize)-> Self{ let clients = Mutex::new(VecDeque::with_capacity(capacity)); let can_cut = Condvar::new(); BarberShop{ capacity, clients, can_cut } } fn enter(&self, client: usize)-> bool{ let mut clients = self.clients.lock().unwrap(); if clients.len() == self.capacity{ return false; } clients.push_back(client); self.can_cut.notify_all(); true } fn wait_for_turn_and_cut(&mut self, client: usize){ let mut clients = self.clients.lock().unwrap(); while *clients.front().unwrap() != client{ clients = self.can_cut.wait(clients).unwrap(); } clients.pop_front(); drop(clients); self.can_cut.notify_all() } } }
4) Manejar más barbers
Para manejar más barberos, se deberían modelar los barberos como recursos de un semáforo.
El BarberShop debería tener un Semaphore(N), con tal de poder asignar un barbero por cliente.
Se debería modificar el wait_for_turn_and_cut, para que trate de adquirir el recurso sobre estos. Además, debería de chequear que haya un barbero disponible en el while, verificando que pueda adquirir un recurso del semáforo.
El uso de la Condvar se mantiene, y cada cliente adquiere un recurso del semáforo, señalizando a todos cuando termina de cortarse. A su vez, al finalizar, libera el recurso del semáforo que adquirió
5) Manejar clientes VIP
Para manejar clientes VIP, además de mantener los cambios anteriores (del punto 4), hay que establecer un esquema de prioridad. Por ejemplo, modelando los clientes como structs (struct Client { id: usize, priority: usize }).
Se debería modificar el wait_for_turn_and_cut para que los ordene según su prioridad (independientemente de si llegaron antes o después, se debe ordenar la VecDeque).
Ejercicios para practicar para el 1er parcial
Link al código fuente de esta sección
En los siguientes ejercicios, se explorarán diversos aspectos de la programación concurrente utilizando Rust.
- La consigna detallará (qué implementar).
- Los resultados o comportamientos esperados se describirán a alto nivel (tests genéricos, sin código específico, o ejemplos de uso).
1. Fundamentos de Concurrencia en Rust
Instrucciones comunes:
- Implementar las soluciones utilizando las primitivas de concurrencia de la librería estándar de Rust (
std::thread,std::sync, etc.). - Prestar atención a la seguridad de hilos (
Send,Sync) y al manejo de datos compartidos. - Considerar el uso de
Mutex,RwLock,Arc, yAtomicssegún sea apropiado.
Ejercicio 1.1: Contador Concurrente y Condiciones de Carrera
Consigna
Implementar un struct Counter que pueda ser compartido y modificado de forma segura por múltiples hilos.
- El
Counterdebe tener un métodonew(initial_value: i32) -> Self. - Debe proveer un método
increment(&self)que aumente su valor interno en 1. - Debe proveer un método
get_value(&self) -> i32que retorne el valor actual.
Se deben considerar dos enfoques o discusiones:
- Analizar por qué una implementación ingenua que intente modificar directamente un
i32compartido entre hilos sin sincronización no es segura o no compilaría fácilmente en Rust sinunsafe. (Referencia:race_conditions.rsmuestra cómo Rust previene esto). - Implementar una versión segura del
Counterutilizandostd::sync::Mutexpara proteger el acceso al valor. - (Opcional) Implementar una versión alternativa utilizando
std::sync::atomic::AtomicI32.
Resultados esperados
- Al lanzar N hilos, donde cada hilo llama al método
increment()M veces sobre una instancia compartida delCounter(protegido conMutexoAtomicI32). - Después de que todos los hilos terminen, el valor final retornado por
get_value()debe serinitial_value + (N * M). - La implementación debe ser segura frente a condiciones de carrera, garantizando que cada incremento se aplique correctamente.
Ejercicio 1.2: Cuenta Bancaria Concurrente
Consigna
Implementar una estructura que simule las operaciones de una cuenta bancaria, permitiendo depósitos, extracciones y consultas de saldo de forma concurrente y segura.
Definir un trait BankAccount:
#![allow(unused)] fn main() { pub trait BankAccount { fn new(initial_balance: f64) -> Self; fn deposit(&self, amount: f64); fn withdraw(&self, amount: f64) -> Result<(), String>; // Retorna Ok o Err con mensaje fn get_balance(&self) -> f64; } }
Proveer dos implementaciones de este trait:
MutexBankAccount: Utilizarstd::sync::Mutex<f64>para gestionar el saldo.RwLockBankAccount: Utilizarstd::sync::RwLock<f64>para gestionar el saldo, permitiendo múltiples lecturas concurrentes.
Resultados esperados
- Múltiples hilos deben poder interactuar concurrentemente con una instancia de
MutexBankAccountoRwLockBankAccount. - Las operaciones de
depositywithdrawdeben modificar el saldo de manera atómica. withdrawdebe retornar unErrsi los fondos son insuficientes, sin modificar el saldo. Si tiene éxito, retornaOk(()).get_balancedebe retornar el saldo actual.- Ejemplo de escenario:
- Cuenta inicia con saldo 0.
- Hilo A deposita 100.
- Hilo B deposita 50.
- Hilo C intenta extraer 200 (debe fallar).
- Hilo D extrae 30.
- Saldo final esperado: 120.
- Todas las operaciones deben reflejarse correctamente sin importar la intercalación de los hilos.
Ejercicio 1.3: Suma Paralela de Elementos de un Vector
Consigna
Implementar una función sum_parallel(nums: &[i32], m: usize) -> i32 que calcule la suma de los elementos de un slice de enteros (&[i32]) de forma paralela.
- El slice
numsdebe ser dividido enmsub-slices (chunks) de tamaño lo más similar posible. - La suma de cada sub-slice debe ser calculada por un hilo (
std::thread) separado. - La función debe esperar a que todos los hilos terminen, recolectar sus sumas parciales y retornar la suma total.
- Considerar el manejo de casos borde, como un vector vacío o
m=0(debe entrar en pánico sim=0omes mayor que el número de elementos de una forma que no tenga sentido, aunque dividir en más chunks que elementos es posible).
Resultados esperados
sum_parallel(&[1, 2, 3, 4, 5], 2)podría dividir el trabajo en[1, 2, 3]y[4, 5], sumarlos en paralelo y retornar15.sum_parallel(&[], m)debe retornar0para cualquierm > 0.- El resultado de
sum_paralleldebe ser idéntico al de una suma secuencial (e.g.,nums.iter().sum()). - La función debe entrar en pánico si
mes 0 (como se muestra enparallel_vector_sum.rs). - Evaluar el rendimiento (conceptualmente) en comparación con una suma secuencial para vectores grandes.
Ejercicio 1.4: Problema del Productor-Consumidor con Buffer Acotado
Consigna
Implementar una estructura BoundedBuffer<T> que sirva como un canal de comunicación de capacidad limitada entre hilos productores y consumidores.
- La
BoundedBuffer<T>debe encapsular los datos compartidos (e.g., unVecDeque<T>para el buffer, su capacidad máxima y tamaño actual) protegidos por unstd::sync::Mutex. - Debe utilizar dos
std::sync::Condvar:not_empty: Para que los hilos consumidores esperen si el buffer está vacío.not_full: Para que los hilos productores esperen si el buffer está lleno.
- Se deben implementar (o se pueden proveer como en
bounded_buffer.rs) structsProduceryConsumerque interactúen con elBoundedBuffer:Producer::produce(&self, item: T): Añade unitemal buffer. Si el buffer está lleno, el productor debe bloquearse (esperar ennot_full). Al producir, notifica a través denot_empty.Consumer::consume(&self) -> T: Extrae unitemdel buffer. Si el buffer está vacío, el consumidor debe bloquearse (esperar ennot_empty). Al consumir, notifica a través denot_full.
Resultados esperados
- Múltiples hilos productores y consumidores pueden operar concurrentemente sobre la misma instancia de
BoundedBuffersin corrupción de datos ni deadlocks. - Los productores se bloquean eficazmente cuando el buffer alcanza su capacidad máxima y se reanudan cuando se libera espacio.
- Los consumidores se bloquean eficazmente cuando el buffer está vacío y se reanudan cuando se añaden nuevos ítems.
- Los ítems producidos son consumidos correctamente (sin pérdidas ni duplicados).
- El uso de
std::thread::sleepdentro deproduce/consume(como en el ejemplo) puede ayudar a visualizar la alternancia y el bloqueo/desbloqueo de los hilos.
Ejercicio 1.5: Implementación de un Buffer Circular Concurrente
Consigna
Desarrollar una estructura ConcurrentCircularBuffer<T> que implemente un buffer circular con semántica de productor-consumidor, seguro para acceso concurrente.
- La estructura interna debe manejar un buffer de tamaño fijo (e.g.,
Vec<Option<T>>) con punterosheadytailpara la lógica circular, y contadores desizeycapacity. - Los datos compartidos (buffer, punteros, contadores) deben estar protegidos por un
std::sync::Mutex. - Se deben emplear dos
std::sync::Condvar(not_emptyynot_full) para la sincronización:- Método
add(&self, item: T): Si el buffer está lleno, el hilo productor debe esperar en laCondvarnot_full. Tras añadir el ítem, debe notificar a un posible consumidor mediantenot_empty.notify_one()(onotify_all()). - Método
remove(&self) -> T: Si el buffer está vacío, el hilo consumidor debe esperar en laCondvarnot_empty. Tras extraer el ítem, debe notificar a un posible productor mediantenot_full.notify_one()(onotify_all()).
- Método
- (Opcional) Considerar la implementación base de un
CircularBuffer<T>no concurrente primero. - Revisar la lógica de notificación: asegurarse de que se notifica a la
Condvarcorrecta (e.g., encircular_buffer.rselremoveoriginal podría tenernot_empty.notify_one()donde debería sernot_full.notify_one()).
Resultados esperados
- El
ConcurrentCircularBufferpermite la interacción segura entre múltiples productores y consumidores. - Se previene el desbordamiento (overflow) y el subdesbordamiento (underflow) del buffer mediante el bloqueo y desbloqueo correcto de los hilos.
- Las
Condvarse utilizan eficazmente para minimizar la espera activa (busy-waiting). - El comportamiento es robusto frente a condiciones de carrera.
Ejercicio 1.6: Cola Concurrente - De Busy-Waiting a Condvar
Consigna
Explorar y mejorar la implementación de una cola (queue) concurrente simple, pasando de un enfoque de espera activa (busy-waiting) a uno más eficiente usando variables de condición (Condvar).
-
Análisis del Busy-Waiting:
- Examinar el código de
queue_behaviour()(presente enqueue.rs), que utiliza unMutex<VecDeque<T>>. - El hilo consumidor intenta extraer elementos en un bucle, adquiriendo el lock repetidamente incluso si la cola está vacía (busy-waiting).
- Identificar las desventajas de este enfoque (principalmente, consumo innecesario de CPU).
- Examinar el código de
-
Implementación con
Condvar:- Modificar o re-implementar la lógica en una función similar a
queue_behaviour_with_condvar(). - Además del
Mutexpara laVecDeque, introducir unastd::sync::Condvar(e.g.,not_empty). - El hilo consumidor, si encuentra la cola vacía, debe esperar en la
Condvar(condvar.wait(lock_guard)). Es crucial que esta espera se realice dentro de un bucle que vuelva a comprobar la condición de la cola tras despertar, para manejar despertares espurios (spurious wakeups). - El hilo productor, después de añadir un elemento a la cola, debe notificar a un consumidor en espera (
condvar.notify_one()).
- Modificar o re-implementar la lógica en una función similar a
Resultados esperados
- Al ejecutar la versión con busy-waiting, se observa un alto uso de CPU por parte del hilo consumidor, especialmente cuando la cola está vacía frecuentemente.
- Al ejecutar la versión con
Condvar, el hilo consumidor debe mostrar un uso de CPU significativamente menor cuando está esperando, ya que el hilo se bloquea en lugar de sondear activamente. - Ambas versiones deben transferir correctamente los ítems del productor al consumidor, pero la versión con
Condvardebe hacerlo de manera mucho más eficiente en términos de recursos del sistema.
Ejercicio 1.7: Comunicación Multi-Productor a Consumidor Único con Canales MPSC
Consigna
Implementar un patrón de concurrencia donde múltiples hilos productores envían datos a un único hilo consumidor utilizando los canales multi-productor, single-consumer (mpsc) de la librería estándar de Rust (std::sync::mpsc).
- Crear un canal
mpsc::channel(). - Lanzar N hilos productores. Cada productor debe:
- Obtener una copia clonada del extremo
Sender<T>del canal. - Enviar uno o más mensajes (e.g., un ID de hilo, un dato calculado, etc.) a través de su
Sender. - Asegurarse de que el
Senderclonado se libere (drop) cuando el productor haya terminado de enviar mensajes para permitir que el canal se cierre eventualmente.
- Obtener una copia clonada del extremo
- El hilo consumidor debe:
- Utilizar el extremo
Receiver<T>del canal. - Recibir mensajes en un bucle. El bucle debe terminar cuando el canal se cierre (es decir, cuando todos los
Senders hayan sido liberados). - Procesar o imprimir cada mensaje recibido.
- Utilizar el extremo
Resultados esperados
- El hilo consumidor recibe todos los mensajes enviados por todos los hilos productores.
- El programa termina correctamente después de que todos los mensajes han sido procesados y el canal se ha cerrado (el
Receiverya no puede obtener más mensajes). - Se puede observar cómo los mensajes de diferentes productores pueden intercalarse al ser recibidos por el consumidor, dependiendo del scheduling de los hilos.
- Este ejercicio demuestra un caso de uso fundamental de los canales
mpscpara la agregación de datos o tareas desde múltiples fuentes.
Ejercicio 1.8: Pipeline de Procesamiento de N Etapas con Canales
Consigna
Construir un pipeline de procesamiento de datos donde un dato inicial atraviesa una secuencia de N etapas de transformación, cada una ejecutándose en un hilo separado y comunicándose con la siguiente mediante canales mpsc.
- Definir una serie de funciones de transformación (e.g.,
fn(T) -> T). - Implementar una estructura o lógica (como la
PipelineyPipelineNodeenchannels.rs) que:- Tome una lista de estas funciones de transformación.
- Para cada función, cree un hilo (una etapa del pipeline).
- Cree un canal
mpscentre cada par de etapas consecutivas (la salida de la etapaies la entrada de la etapai+1). - El primer hilo del pipeline recibe un valor inicial (posiblemente a través de un
Senderinicial). - Cada hilo intermedio recibe un valor de su predecesor, aplica su función de transformación, y envía el resultado a su sucesor.
- El último hilo del pipeline envía su resultado a un
Receiverfinal desde donde se puede obtener el resultado global.
- La función
rundel pipeline debe tomar un valor inicial, enviarlo a la primera etapa, y retornar el valor recibido de la última etapa.
Resultados esperados
- Un valor de entrada es procesado secuencialmente por todas las etapas del pipeline, con cada transformación ocurriendo en un hilo dedicado.
- El resultado final obtenido es el producto de aplicar todas las funciones de transformación en el orden especificado.
- Ejemplo: Si el valor inicial es
Xy las etapas sonf1, f2, f3, el resultado final debe serf3(f2(f1(X))). - El sistema debe manejar la creación, el enlace y el cierre de los canales correctamente. (Considerar cómo se manejan los errores o pánicos en una etapa; el ejemplo en
channels.rsusaexpectyunwrap).
Ejercicio 1.9: El Problema de los Filósofos Cenadores
Consigna
Implementar una simulación del clásico problema de concurrencia de los "Filósofos Cenadores", con el objetivo de evitar deadlocks y permitir que los filósofos coman.
- Habrá N filósofos sentados en una mesa redonda. Entre cada par de filósofos adyacentes hay un tenedor (N tenedores en total).
- Cada filósofo alterna entre dos estados: pensar y comer.
- Para comer, un filósofo necesita adquirir los dos tenedores que tiene a su lado (el izquierdo y el derecho).
- La implementación debe incluir:
- Un struct
Philosopherque represente a un filósofo, con su ID (o posición) y la lógica para pensar y comer. - Un struct
Table(o similar) para representar el estado compartido de los tenedores. Este estado (e.g., unVec<bool>indicando si cada tenedor está disponible) debe ser protegido por unstd::sync::Mutex. - Una
std::sync::Condvarpara que los filósofos puedan esperar de manera eficiente si los tenedores que necesitan no están disponibles.
- Un struct
- Lógica para comer (método
eatdelPhilosopher):- Adquirir el lock del
Mutexde la mesa. - Mientras ambos tenedores necesarios (izquierdo y derecho) no estén disponibles: esperar en la
Condvar(condvar.wait(lock_guard)). La guarda del mutex se libera mientras se espera y se vuelve a adquirir al despertar. - Cuando ambos tenedores estén disponibles (tras despertar y re-evaluar la condición), marcarlos como "en uso".
- Liberar el lock del
Mutexde la mesa (importante: esto permite a otros filósofos intentar tomar tenedores mientras este come). - Simular el tiempo de comida (e.g.,
std::thread::sleep). - Volver a adquirir el lock del
Mutexde la mesa. - Marcar ambos tenedores como "disponibles".
- Notificar a todos los demás filósofos que podrían estar esperando (
condvar.notify_all()). - Liberar el lock del
Mutex.
- Adquirir el lock del
Resultados esperados
- La simulación se ejecuta con N filósofos (e.g., 5) y N tenedores.
- Los filósofos pueden alternar entre pensar y comer sin que el sistema entre en deadlock (donde ningún filósofo puede progresar).
- Se demuestra que los filósofos esperan si no pueden obtener ambos tenedores y son notificados cuando los tenedores se liberan.
- (Opcional) Considerar y discutir brevemente otras estrategias para la prevención de deadlocks en este problema (e.g., ordenamiento global de adquisición de tenedores, limitar el número de comensales).
Ejercicio 1.10: Implementación de Merge Sort Paralelo
Consigna
Desarrollar una versión paralela del algoritmo de ordenamiento Merge Sort para un slice de enteros (&[i32]).
- La implementación debe incluir las siguientes partes:
- Una función
merge(first_slice: &[i32], second_slice: &[i32]) -> Vec<i32>: Esta función toma dos slices ya ordenados y los combina en un nuevoVec<i32>que también está ordenado. - (Opcional pero útil como referencia) Una función
sequential_merge_sort(slice: &[i32]) -> Vec<i32>: La implementación recursiva estándar de Merge Sort. - Una función
parallel_merge_sort(slice: &[i32]) -> Vec<i32>: Esta es la versión paralela.- Debe manejar el caso base: si el slice es suficientemente pequeño (e.g., longitud 0 o 1), se retorna directamente o se ordena secuencialmente.
- Para el paso recursivo: dividir el slice en dos mitades.
- Ordenar al menos una de las mitades en un nuevo hilo. Por ejemplo, la primera mitad puede ordenarse en el hilo actual (recursivamente, podría ser secuencial o paralelo dependiendo de la profundidad y un umbral), y la segunda mitad se ordena en un hilo spawnneado (
std::thread::scopees útil aquí). - Esperar a que el hilo (o hilos) terminen y obtener las dos mitades ordenadas.
- Combinar las dos mitades ordenadas usando la función
merge.
- Una función
Resultados esperados
parallel_merge_sortdebe producir un vector correctamente ordenado, idéntico al resultado de un Merge Sort secuencial.- Debe funcionar para diversos casos de prueba: arrays vacíos, de un elemento, ya ordenados, en orden inverso, con elementos duplicados, etc.
- Para arrays de tamaño considerable, la versión
parallel_merge_sortdebería, idealmente, ejecutarse más rápido que una versión puramente secuencial. Esto se puede verificar mediante benchmarking (comparando tiempos de ejecución). - (Para discusión) Considerar el uso de un umbral: si el tamaño del sub-array a ordenar es menor que cierto umbral, cambiar a una versión secuencial para evitar el overhead de crear hilos para tareas muy pequeñas. También, discutir cómo se podría aumentar el grado de paralelismo (e.g., lanzando ambas mitades a hilos separados si el umbral lo permite).
Ejercicio 1.11: Suma de Matrices Secuencial y Paralela
Consigna
Implementar una estructura Matrix para representar matrices de números de punto flotante (f64) y desarrollar métodos para su suma, tanto de forma secuencial como paralela.
- Definir un struct
Matrixque encapsule los datos de la matriz (e.g.,Vec<Vec<f64>>). - Implementar las siguientes funcionalidades para la suma de dos matrices (
selfyother: &Matrix):- Suma Secuencial (
add_sequential):- Debe sumar las dos matrices elemento por elemento y retornar una nueva
Matrixcon el resultado. - La operación asume que ambas matrices tienen las mismas dimensiones. (Considerar añadir una verificación explícita de dimensiones y manejar el error si no coinciden, e.g., retornando un
Result<Matrix, String>o causando unpaniccontrolado).
- Debe sumar las dos matrices elemento por elemento y retornar una nueva
- Suma Paralela (
add_parallel):- Debe realizar la suma de las dos matrices utilizando hilos para paralelizar el cálculo.
- Una estrategia común es asignar a cada hilo el cálculo de una fila completa (o un subconjunto de filas) de la matriz resultante.
std::thread::scopepuede ser útil para gestionar los hilos. - Al igual que la suma secuencial, esta operación asume dimensiones compatibles.
- Suma Secuencial (
- (Opcional) Crear una enumeración
OperationMethod { SEQUENTIAL, PARALLEL }y un método principaladd_matrix(&self, other: &Matrix, method: OperationMethod) -> Matrixque delegue a la implementación correspondiente.
Resultados esperados
- Para dos matrices de entrada dadas, tanto
add_sequentialcomoadd_paralleldeben producir la mismaMatrixresultante. - El código debe manejar correctamente matrices de diversas dimensiones (e.g., cuadradas, rectangulares, 1x1) y con diferentes tipos de valores (positivos, negativos, cero).
- Para matrices de tamaño suficientemente grande, la versión
add_paralleldebería mostrar una mejora en el tiempo de ejecución en comparación conadd_sequential. Esto se puede verificar mediante benchmarking. - Si se implementa la verificación de dimensiones, las operaciones deben fallar de forma predecible (e.g., retornar
Erropanic) cuando se intentan sumar matrices de dimensiones incompatibles. - (Para discusión) Explorar y comparar diferentes granularidades para la paralelización: ¿por fila, por columna, por bloques de elementos? ¿Cuál podría ser más eficiente y por qué?
Temas a evaluar
Notas
- Actores puede entrar de manera práctica
- Hay que saber Scala
- Non-Blocking también (en Rust)
- En ninguno de los 2 se va a hilar muy fino, con que conceptualmente esté bien, todo pelota
Nota: es más difícil escribir el
mainque modelar las clases de los actores. Pídanselo a GPT para ver cómo se hace, es súper específica la sintaxis. Tiene mucho Syntax Sugar
Ejercicios
Parciales
Segundo Parcial 2024

Resolución
1 - NonBlocking Algorithms
Completar el siguiente código para que funcione el pop de una implementación no bloqueante de un Stack concurrente
fun pop(): E {
var oldHead: Node<E>? = top.get()
while (oldHead != null && /* Completar */)
oldHead = top.get()
return oldHead?.item
}
Respuesta:
fun pop(): E {
var oldHead: Node<E>? = top.get()
while (oldHead != null && !top.compareAndSet(oldHead, oldHead?.next))
oldHead = top.get()
return oldHead?.item
}
2 - Garantías de Message Passing en el sistema de actores
Respuesta:
Nota: para estos ejemplos yo voy a ser el remitente y Juan va a ser el receptor en todos los casos
Las 3 garantías que existen son:
At most once: garantiza que el envío de un mensaje se reciba como mucho una vez (0 o 1 veces).- Yo le mando un mensaje a Juan, y puede llegarle una vez como puede no llegarle
- En lo que a espacio adicional refiere, no usa más que el espacio que el mensaje requiere
- No usa identificadores
At least once: garantiza que el envío de un mensaje se reciba al menos una vez (1 a N veces)- Yo le mando un mensaje a Juan, y seguro que una vez le llega, pero puede llegarle más de una vez. Es decir, le mando "Hola", y puede registrar un sólo "Hola" como puede registrar 30.
- En lo que a espacio adicional refiere usa, al menos, el espacio que puede ocupar el mensaje enviado. Puede usar más que eso, dependiendo de las veces que reciba el mensaje.
- No usa identificadores
Exactly once: garantiza que el primer envío de un mensaje se reciba exactamente 1 vez- Yo le mando un mensaje a Juan y le llega una única vez.
- Se usa sólo el espacio que ocupa este mensaje
- Para garantizar esto, se requieren IDs únicos para trackear los mensajes que se intercambian
3 - Ejemplo de Actores
class Fib extends Actor{
def fib(prev: Int, last: Int): Receive = {
case "incr" => context.become(last, prev + last)
case "get" => sender ! (prev + last)
case "boom" => throw new IllegalStateException()
}
def receive = fib(0, 1)
}
a) Qué recibiríamos si mandamos los siguientes mensajes?
fib ! "get"; fib ! "incr"; fib ! "incr"; fib ! "get"; fib ! "incr"; fib ! "get";
La secuencia sería la siguiente:
- Se recibe
1 - No se recibe nada, se incrementa y el actor pasa a ser
fib(1, 1) - No se recibe nada, se incrementa y el actor pasa a ser
fib(1, 2) - Se recibe
3 - No se recibe nada, se incrementa y el actor pasa a ser
fib(2, 3) - Se recibe
5
b) Y si mandamos estos mensajes?
fib ! "incr"; fib ! "incr"; fib ! "incr"; fib ! "boom"; fib ! "get"
La secuencia sería la siguiente (suponiendo que arranca de 0):
- No se recibe nada, se incrementa y el actor pasa a ser
fib(1, 1) - No se recibe nada, se incrementa y el actor pasa a ser
fib(1, 2) - No se recibe nada, se incrementa y el actor pasa a ser
fib(2, 3) - Revienta el actor, y dependiendo de la estrategia de supervisión que tenga su actor padre (o el
ActorSystem) puede:- Morir y no recibir más mensajes, por ejemplo
- Reiniciar su estado (que es lo que hace
Akkapor default) - Planear otra estrategia custom
- Se recibe
1, porque se reinició el estado del actor (está en estadofib(0, 1))
4 - Corutinas
Qué hace? Cómo funciona?
val mystery: Sequence<Int> = sequence {
var result = 1
var n = 1
while (true){
yield(result)
result *= ++n
}
}
- Funciona como una secuencia que va generando el factorial del número que se le pide con
take(n: Int) - Justamente, lo primero que hace es "ceder" (devolver) un
1con elyield - En caso de pedirle más de un elemento (es decir,
n>=2), sigue el siguiente ciclo:- Cede el resultado actual (que para
n=1es 1), y actualiza result multiplicándolo por (n+1), actualizando n con su siguiente valor (n+1) - Entonces, si siempre multiplica por el siguiente de n, eso implica una secuencia factorial:
- Cede el resultado actual (que para
5 - Qué es un Future y qué problemas resuelve?
Un Future es objeto que representa un "registro" de que se llamó a una función asíncrona. Representa el valor eventual que va a devolver esa función asíncrona.
Encapsula el resultado una función que se ejecuta de manera asíncrona, que se puede ejecutar en paralelo y, en algún momento, devolver un valor.
Viene a resolver problemas competentes al contexto de la programación concurrente, tales como:
- Coordinación de concurrencia y bloqueo de hilos: al ser una tarea paralelizable (porque computa un valor de manera asíncrona), otorga una forma adicional de implementar concurrencia. Además, gracias a esto, evita tener que bloquear hilos por esperar a computar un valor (usando
thread.join()oget()).- Sumado a esto, los Futures (como objeto) tienen la funcionalidad de computar varios a la vez y esperar a que todos los resultados se terminen de computar, usando
Future.thenAccept(...)
future1.thenAccept{ (future2) { result1, result2 -> hacerAlgoConLosResultados(result1, result2) } } - Sumado a esto, los Futures (como objeto) tienen la funcionalidad de computar varios a la vez y esperar a que todos los resultados se terminen de computar, usando
- Composición de tareas asíncronas: previo a la existencia del
Future, era necesario componer funciones entre sí, llegando a niveles de indentación y llamados ilegibles, siendo este un problema conocido comocallback hell.- Justamente el
Futurepermite escribir de manera más prolija esos llamados asíncronos a funciones.
- Justamente el
Ejemplo en pseudocódigo (en Kotlin)
Supongamos que nos levantamos a la mañana y nuestra rutina implica:
- Tomar un baño
- Hacer el desayuno (implica un café y 2 tostadas)
- Trabajar
Nota: suponer que tomar un baño y hacer el desayuno toma más o menos el mismo tiempo.
Y obligatoriamente tenemos que comenzar a trabajar luego de hacer ambas anteriores. Si yo quisiera primero tomar un baño y luego desayunar, tengo 2 alternativas:
- Me baño y después me preparo el desayuno
- Dejo el café calentándose en el microondas y las tostadas haciéndose en la tostadora
Intuitivamente el segundo approach parece más eficiente, ¿no?
Eso es porque implementa asincronismo, yo consumo el café una vez me bañé, y no tuve que esperar a que se haga el desayuno luego de haberme bañado porque lo dejé haciendo.
fun morningRoutine(){
// Pongo a hacer el desayuno
// Esto también se puede escribir de la forma:
// `CompletableFuture.supplyAsync { makeBreakfast() }`
CompletableFuture.supplyAsync(() -> makeBreakfast())
.thenAccept(breakfast -> { // Cuando mi desayuno esté listo
// Tomo mi desayuno
haveBreakfast(breakfast)
// Una vez tomé mi desayuno, me pongo a trabajar
work()
})
// Me tomo un baño en paralelo. Cuando mi desayuno esté listo, me lo tomo y arranco a trabajar
takeBath()
}
Segundo Parcial 2025
Primer ejercicio - Non-Blocking Concurrent Stack
Dada la siguiente implementación de un Stack, haz los cambios necesarios para que sea una estructura concurrente no bloqueante:
class Stack<E> {
class Node<E>(val item: E, var next: Node<E>? = null)
private var top: Node<E>? = null
fun push(item: E) {
val newHead = Node(item)
newHead.next = top
top = newHead
}
fun pop(): E? {
val oldHead = top
if (oldHead == null) return null
top.set(oldHead.next)
return oldHead.item
}
}
Nota: puede resolverse tanto en Kotlin como en Rust
Segundo ejercicio - Corutinas
Dada la siguiente corutina, predecir el output:
suspend fun compute(name: String, delayTime: Long): Int {
delay(delayTime)
println("Done with $name")
return name.length
}
fun main(): Unit = runBlocking {
println("Start")
launch {
val launchValue = compute("LaunchTask", 300L)
println("Launch result: $launchValue")
}
val deferred = async {
val result = compute("AsyncTask", 200L)
println("Async result: $result")
result
}
println("Middle")
val final = deferred.await()
println("Final result: $final")
}
Tercer ejercicio - Actores de una subasta
Implementar un sistema de subastas concurrente usando actores en Scala, con la librería Akka. El sistema involucra 3 tipos de actores:
- Auction / Subasta: recibe pujas y registra la más alta.
- Bidder / Pujador : envía pujas cada cierto tiempo
- Organizer / Organizador: empieza la subasta y recibe el resultado
La subasta empieza cuando el Auction recibe un mensaje del tipo StartAuction. Los Bidders envían las pujas (con un ID y una cantidad) por un tiempo específico.
Cuando la subasta termina, se le anuncia el ganador al Organizer.
- Define el protocolo (los mensajes que se intercambian)
- Implementar el comportamiento de cada actor
Código de ejemplo (main del programa)
object ActorSystem extends App {
val system = ActorSystem("AuctionSystem")
val organizer = system.actorOf(Props[Organizer], "organizer")
val auctionDuration = 15.seconds
val auction = system.actorOf(Props(new Auction(auctionDuration)), "auction")
auction ! StartAuction(organizer)
// Bidder A places bids up to 50 for 8 seconds
system.actorOf(Props(new Bidder(auction, "A", 50, 8.seconds)), "bidderA")
// Bidder B places bids up to 100 for 10 seconds
system.actorOf(Props(new Bidder(auction, "B", 100, 10.seconds)), "bidderB")
// Bidder C places bids up to 75 for 6 seconds
system.actorOf(Props(new Bidder(auction, "C", 75, 6.seconds)), "bidderC")
}
Operaciones útiles
// Send a "HELLO" message to itself after some duration
context.system.scheduler.scheduleOnce(duration, self, "HELLO")
// From the first moment the actor is created, after 50 milliseconds it sends itself a Tick message
context.system.scheduler.scheduleWithFixedDelay(Duration.Zero, 50.millis, self, Tick)
// Returns a random number from 0 to max
private val random = new Random()
random.nextInt(max)
Resolución
Primer ejercicio - Non-Blocking Concurrent Stack
Resolución en Kotlin
class NonBlockingStack<E> {
class Node<E>(val item: E, var next: Node<E>? = null)
private var top = AtomicReference<Node<E>?>()
fun push(item: E) {
val newHead = Node(item)
var oldHead: Node<E>?
do {
oldHead = top.get()
newHead.next = oldHead
} while (!top.compareAndSet(oldHead, newHead))
}
fun pop(): E? {
var oldHead: Node<E>? = top.get()
while (oldHead != null && !top.compareAndSet(oldHead, oldHead.next))
oldHead = top.get()
return oldHead?.item
}
}
Resolución en Rust
#![allow(unused)] fn main() { struct NonBlockingStack<T> { head: AtomicPtr<Node<T>>, size: AtomicUsize, } impl<T> NonBlockingStack<T> { pub fn new() -> Self { let dummy = Box::into_raw(Box::new(Node::dummy())); NonBlockingStack { head: AtomicPtr::new(dummy), size: AtomicUsize::new(0), } } fn push(&self, value: T) { let new_node = Box::into_raw(Box::new(Node::new(value))); loop { let head = self.head.load(Ordering::Acquire); unsafe { (*new_node).next.store(head, Ordering::Relaxed) }; if self .head .compare_exchange(head, new_node, Ordering::Release, Ordering::Acquire) .is_ok() { self.size.fetch_add(1, Ordering::Release); break; } } } fn pop(&self) -> Option<T> { loop { let cur_head = self.head.load(Ordering::Acquire); if cur_head.is_null() { return None; } let next_node = unsafe { (*cur_head).next.load(Ordering::Acquire) }; if self .head .compare_exchange(cur_head, next_node, Ordering::AcqRel, Ordering::Acquire) .is_ok() { self.size.fetch_sub(1, Ordering::Release); let old_head_node = unsafe { Box::from_raw(cur_head) }; return old_head_node.item; } } } } struct Node<T> { item: Option<T>, next: AtomicPtr<Node<T>>, } impl<T> Node<T> { fn dummy() -> Self { Node { item: None, next: AtomicPtr::new(null_mut()), } } fn new(item: T) -> Self { Node { item: Some(item), next: AtomicPtr::new(null_mut()), } } } }
Segundo ejercicio - Corutinas
El output va a ser el siguiente:
Start
Middle
Done with AsyncTask
Async result: 9
Final result: 9
Done with LaunchTask
Launch result: 10
¿Por qué?
El programa inicia printeando "Start". Luego, al llegar al launch (el cual es un scope de corutina que no devuelve ningún valor), entra a la función compute, ve que hay un delay y le cede el control a la corutina principal (la función main).
Acto seguido, vemos la inicialización de la corutina async, que también tiene un delay dado que llama a compute dentro suyo, por lo que también cede el control a la corutina principal.
Lo siguiente que se va a ejecutar es el print("Middle").
Luego, se queda esperando por el valor que devuelve el deferred, por lo que se ejecutará el print dentro de su llamado a compute (Done with AsyncTask), y luego se printeará el Async Result: 9.
Lo siguiente que pasará es que se printeará el valor de final result, dado que depende del valor de la tarea asíncrona.
Por último, se ejecutará el print del LaunchTask por volver a cederle el control al launch, seguido del Launch Result: 10.
Tercer ejercicio - Actores de una subasta
object AuctionProtocol {
case class Winner(id: String, amount: Int) // Se lo manda al Organizer
case object AnnounceWinner
case class StartAuction(organizer: ActorRef)
}
class Organizer extends Actor {
override def receive: Receive = {
case Winner(id: String, amount: Int) =>
println(s"The winner is $id with the incredible amount of $amount !")
}
}
class Auction(duration: FiniteDuration, organizer: ActorRef) extends Actor {
// Cuando se me termina el tiempo, anuncio el ganador
context.system.scheduler.scheduleOnce(duration, self, AuctionProtocol.AnnounceWinner)
private var currentMaxBid: (String, Int) = ("", 0)
override def receive: Receive = {
case AuctionProtocol.StartAuction(organizer: ActorRef) =>
println(s"The auction has started! It's being organized by ${organizer.toString}")
case BidderProtocol.Bid(id: String, amount: Int) =>
if (currentMaxBid._2 < amount) { // Si es una puja mayor, la actualizo
currentMaxBid = (id, amount)
}
case AuctionProtocol.AnnounceWinner =>
organizer ! Winner(currentMaxBid._1, currentMaxBid._2) // Le mando el ganador al organizador
context.stop(self) // Freno este actor
}
}
class Bidder(auction: ActorRef, id: String, maxBid: Int, duration: FiniteDuration) extends Actor {
// Programo para pujar cada cierto tiempo
context.system.scheduler.scheduleWithFixedDelay(Duration.Zero, 50.millis, self, BidderProtocol.SendBid)
private val random = Random()
private var currentBid: Int = 0
// Tengo que dejar de pujar después de un cierto tiempo
context.system.scheduler.scheduleOnce(duration, self, BidderProtocol.Stop)
override def receive: Receive = {
case BidderProtocol.Stop =>
context.stop(self) // Freno este actor cuando se me termina el tiempo (es decir, cuando dejo de pujar)
case BidderProtocol.SendBid =>
auction ! BidderProtocol.Bid(id, getCurrentMaxBid)
}
private def getCurrentMaxBid: Int = {
val newBid = random.nextInt(maxBid)
if (newBid > currentBid) {
currentBid = newBid
}
currentBid
}
}
object BidderProtocol {
case object SendBid
case class Bid(id: String, amount: Int)
case object Stop
}
Ejercicios para practicar para el 2do parcial
Link al código fuente de esta sección
En los siguientes ejercicios, se tendrán:
- La consigna (qué implementar).
- Resultados o comportamientos esperados a alto nivel (tests genéricos, sin código específico).
1. Programación Asíncrona (Kotlin + Corutinas)
Instrucciones comunes:
- Todos los ejercicios deben resolverse usando corutinas de Kotlin (
suspend fun,launch,async,flow, etc.). - No es necesario usar librerías adicionales: basta con
kotlinx.coroutines. - Al proponer resultados esperados, se asume que habrá alguna manera de comprobar (por ejemplo, listas de logs, contadores, resultados de funciones, o estados finales).
Ejercicio 1.1: Descarga paralela y combinación de datos
Consigna
Implementar una función suspend fun fetchDataFromSources(): List<String> que simultáneamente lance tres corutinas que
"simulen" descargar datos de tres fuentes externas diferentes (por ejemplo, retrasos de 1 seg, 2 seg y 3 seg). Cada
descarga retorna una List<String> propia. Cuando todas las descargas terminen, hay que combinar sus listas en una sola
lista ordenada alfabéticamente y retornarla.
Resultados esperados
- Si las tres descargas simulan devolver
["A","B"],["C"]y["D","E"](en distintos tiempos), la función debería retornar["A","B","C","D","E"]. - El tiempo total de ejecución de
fetchDataFromSources()debe rondar el máximo de los tres delays (≈ 3 seg), no la suma (≈ 6 seg). - Si alguna descarga lanza una excepción,
fetchDataFromSources()debe cancelarlas a todas y propagar un único error (CancellationException).
Ejercicio 1.2: Timeout y fallback
Consigna
Crear una función suspend fun getUserProfile(userId: Int): String que intente obtener el perfil de un usuario desde un
"servicio remoto simulado" (delay de 5 seg), pero si supera un timeout de 2 seg, se cancele dicha llamada y retorne un
perfil por defecto (por ejemplo, "Usuario por defecto"). Usar withTimeout o withTimeoutOrNull según convenga.
Resultados esperados
- Si la llamada al servicio remoto dura 5 seg,
getUserProfiledebe terminar alrededor de 2 seg y devolver"Usuario por defecto". - Si en algún caso se reduce el delay simulado a 1 seg, la función debe devolver el perfil real (por ejemplo
"Perfil de 42") en ≈ 1 seg. - No debe quedar ninguna corutina "colgada" después de que expire el timeout.
Ejercicio 1.3: Flujo de eventos y back-pressure
Consigna
Definir un Flow<Int> que emita un número creciente cada 100 ms (i.e. 0,1,2,…). Consumirlo en otra corutina que
procese cada número con un delay de 300 ms (simulando trabajo pesado). Gestionar correctamente la suscripción para que,
si el consumidor no da abasto, el emisor se suspenda (no pierda valores y no agote memoria). Usar buffer(),
conflate() o collectLatest() según el comportamiento deseado. Documentar brevemente qué estrategia de back-pressure
se eligió.
Resultados esperados
- Si se usa
buffer(capacity = 1)y el consumidor demora 300 ms, el emisor enchufa hasta 1 valor en el buffer y luego se suspende. Nunca se pierden valores, pero la tasa del consumidor marca el ritmo. - Si se usa
conflate(), el consumidor obtiene solo el último valor generado mientras estaba ocupado (p. ej., del 0 al 3 en buffer, llega el 3). - Mostrar en consola los valores que el consumidor realmente procesa y la hora (timestamp) para verificar que no se acumulan más de lo esperado.
Ejercicio 1.4: Cancelling child jobs al fallar uno
Consigna
Implementar una función suspend fun processOrders(orderIds: List<Int>): List<String> que, para cada orderId, lance
una corutina hija (con async) que simule "procesar" el pedido (delay aleatorio entre 100 ms y 500 ms) y devuelva
"Order #<id> processed". Si alguno de esos async falla (lanza excepción), se debe cancelar toda la ventana de
procesamiento y propagar un error que incluya el orderId que falló. Usar un scope apropiado para que la cancelación se
propague a todos los hijos.
Resultados esperados
- Si la lista es
[1,2,3]y solo el procesamiento deorderId = 2lanzaRuntimeException("Error en #2"), la función debe lanzarCancellationExceptionoRuntimeException("Error en #2")y ninguno de los otros pedidos completos debe continuar después de la falla. - En caso exitoso (ej.
[1, 2]todos terminan sin excepción), retorna una lista de strings:["Order #1 processed", "Order #2 processed"], con longitud igual al número de elementos.
Ejercicio 1.5: Integración con canal y productor-consumidor
Consigna
Crear un Channel<Int> con capacidad 10 que actúe como buffer circular. En una corutina "productor" (launch), emite
números del 1 al 100 con un delay de 50 ms entre cada emisión. En otra corutina "consumidor" (launch), recibe de ese
canal y procesa cada número con un delay de 200 ms (simulando trabajo). Finalmente, cuando el productor haya cerrado el
canal, el consumidor debe terminar y reportar en consola el total de números procesados.
Resultados esperados
-
El productor emite 100 enteros y luego cierra el canal.
-
El consumidor procesa exactamente 100 enteros (impresión en consola de cada uno o simplemente un contador).
-
Debido a que el consumidor tarda 200 ms y el productor solo 50 ms, el canal mantendrá hasta 10 elementos "pendientes" y luego el productor se suspenderá cuando esté full.
-
Tiempo total aproximado:
- El productor terminará antes de 5 seg (100 × 50 ms = 5 000 ms).
- El consumidor tardará ~ 100 × 200 ms = 20 000 ms.
-
Finalmente imprimir:
"Consumo finalizado: 100 elementos procesados".
2. Algoritmos No Bloqueantes (Rust)
Instrucciones comunes:
- Implementar exclusivamente con la librería estándar de Rust (
std::sync::atomic,std::thread, etc.). - No usar mutex ni bloqueos de sistema; usar operaciones atómicas (
AtomicPtr,AtomicUsize,CompareAndSwap, etc.). - Indicar claramente qué estructuras atómicas se usan y en qué orden.
- Para cada ejercicio basta con describir la API pública, el comportamiento deseado y cómo verificarlo con pruebas genéricas (p.ej. lanzar muchas hebras y comprobar invariantes).
Ejercicio 2.1: Pila no bloqueante (Lock-free Stack)
Consigna
Implementar una pila (struct NonBlockingStack<T>) con los siguientes métodos:
#![allow(unused)] fn main() { impl<T> NonBlockingStack<T> { pub fn new() -> Self { /* … */ } pub fn push(&self, value: T){} pub fn pop(&self) -> Option<T>{/*...*/} } }
- Cada nodo se guarda en un
Box<Node<T>>y se enlaza mediante unAtomicPtr<Node<T>>apuntando a la cabeza. - El método
pushdebe crear un nuevo nodo, leer la cabeza actual y usarcompare_exchangepara insertarlo. - El método
popdebe leer la cabeza, tomar el valor si no es nulo, y hacercompare_exchangepara avanzar la cabeza. Luego retorna elTcontenido. - Asegurarse de hacer
Box::from_rawsólo cuando elpoptenga éxito, para evitar fugas de memoria.
Resultados esperados
- Generar 8 hilos (threads) que hagan cada uno 1 000 inserciones (
push(i)) seguidas de 1 000 extracciones (pop()), todo en paralelo. - Después de unificar (join) los hilos, la pila debe estar vacía (
pop()retornaNone). - Contar cuántos valores distintos se obtuvieron al hacer
pop. Debe coincidir exactamente con el total de inserciones (8 × 1 000 = 8 000). - No debe haber pánico por doble liberación ni memory leak: ejecutar con
cargo miri(ocargo valgrind) para validar.
Ejercicio 2.2: Cola no bloqueante unidireccional (MPSC Queue)
Consigna
Crear una cola de un solo productor y múltiples consumidores (struct MpscQueue<T>) con API:
#![allow(unused)] fn main() { impl<T> MpscQueue<T> { pub fn new() -> Self { /* … */ } pub fn enqueue(&self, value: T); // sólo un hilo (producer) llama a esto pub fn dequeue(&self) -> Option<T>; // varios hilos (consumers) llaman a esto } }
- Internamente, usar un puntero atómico a un nodo "dummy" como cabeza y otro como cola (Michael & Scott queue simplificada).
enqueuees sólo llamado desde un hilo "productor" y hacecompare_exchangepara insertar al final.dequeuepodrá ser invocado concurrentemente desde N hilos, avanzando la cabeza.- Cuidar la operación atómica sobre el tamaño (opcional) con un
AtomicUsizeque incremente enenqueuey decremente endequeue.
Resultados esperados
- En un test, lanzar 1 hilo productor que encola 50 000 enteros (0..50 000).
- Lanzar 4 hilos consumidores que, en loop, hagan
dequeue()y acumulen los valores en un vector local hasta que el queue devuelvaNoney el productor haya terminado. - Al final, reunir (merge) los resultados y comprobar que aparecen exactamente todos los números del 0 al 49 999, sin duplicados ni faltantes.
- Verificar que el tamaño reportado internamente (si se implementa
len()) se acerca a cero cuando el procesado finaliza.
Ejercicio 2.3: Contador atómico con escalonamiento exponencial
Consigna
Implementar un contador (struct BackoffCounter) que use un AtomicUsize internamente para incrementos concurrentes
desde N hilos. Para reducir la contención, tras cada "fallo" en el compare_exchange, el hilo hará un backoff
exponencial: al principio dormir 1 µs, luego 2 µs, 4 µs, hasta un tope (p. ej., 128 µs). La interfaz pública:
#![allow(unused)] fn main() { impl BackoffCounter { pub fn new(initial: usize) -> Self { /* … */ } pub fn increment(&self); pub fn get(&self) -> usize; } }
- En
increment, el hilo lee el valor actual, calculaval + 1y usacompare_exchange_weak. Si falla, duerme el tiempo de backoff actual (doblándolo) y reintenta, hasta tenedortope. get()carga el valor actual conOrdering::Acquire.
Resultados esperados
- Lanzar 16 hilos, cada uno hace 10 000 llamadas a
increment(). - Al unir todos, el valor final de
get()debe ser 16 × 10 000 = 160 000. - Medir (aprox.) el tiempo de ejecución con vs. sin backoff (es suficiente un print de "tiempo sin backoff: X ms", "tiempo con backoff: Y ms") para comprobar la mejora de contención cuando hay más hilos.
- Asegurarse de que nunca se quede "en bucle infinito", es decir, tras llegar al tope de backoff se vuelve a intentar indefinidamente, pero con un máximo de 128 µs entre reintentos.
Ejercicio 2.4: Tabla hash concurrente lock-free (Lock-free HashMap)
Consigna
Diseñar una tabla hash concurrente muy simplificada (struct LockFreeHashMap<K, V>) que soporte insert(key, value),
get(&key) -> Option<V>, y remove(&key) -> Option<V>. Debe basarse en:
- Un vector fijo de "celdas" tamaño M (e.g. M=64), donde cada celda es un puntero atómico a una lista enlazada
lock-free de pares
(K, V). - Cada lista se implementa como un stack "lock-free" con
AtomicPtr<Node>, similar al Ejercicio 2.1. - Para
insert, se calculahash = hash(key) % M, luego se hace push de(K,V)en la lista correspondiente. Si ya existe el key, se puede decidir: a) rechazar, o b) insertar duplicado. - Para
get, se lee la lista en modo "snapshot": se recorre sin bloquear la lista. - Para
remove, se marca el nodo "lógicamente eliminado" (opcional) o bien se hace "lazy deletion" dejando que otro thread lo retire al inspeccionar la lista.
La parte complicada es coordinar las listas lock-free sin mutex:
- El énfasis está en la API y en demostrar que concurrentemente varias hebras pueden hacer
insert/get/removesin panics ni corrupciones de memoria.
Resultados esperados
-
Escribir un test con 8 hilos durante 2 segundos. Cada hilo hace, al azar:
insert(random_key, random_value)get(random_key)remove(random_key)
-
Al terminar, imprimir cuántas claves únicas quedaron en la tabla.
-
Verificar, tras el test, que todos los nodos removidos fueron liberados (usar
cargo miripara chequear leaks). -
Comprobar también que nunca se obtiene un valor "corrupto" para ninguna clave (p.ej. comparar con un mapa secuencial simulado como oracle).
3. Actores (Scala + Akka)
Instrucciones comunes:
- Usar Scala 2.13+ y la librería Akka (versión 2.6 o superior).
- Definir actores extendiendo
akka.actor.Actoro usandoAbstractBehavior(Akka Typed), según prefieras. - Cada ejercicio debe incluir la descripción de los mensajes ("case class" o "case object") y la lógica interna de los actores (stateful o stateless).
- Los tests esperados deben formularse de manera genérica: enviar mensajes y verificar estados finales o respuestas.
Ejercicio 3.1: Chat Room con actores
Consigna Implementar un sistema de chat muy simple:
-
UserActor: representa a cada usuario conectado. Recibe mensajes tipo
Message(from: String, text: String)y los imprime o guarda en su estado local. También puede recibirJoinRoom(roomRef: ActorRef)yLeaveRoom(roomRef: ActorRef). -
RoomActor: maneja la sala.
-
Mensajes que acepta:
Join(userName: String, userRef: ActorRef)Leave(userName: String)Broadcast(sender: String, text: String)
-
Internamente mantiene un
Set[(String, ActorRef)]de usuarios en línea. -
Al recibir
Join, añade el par(userName, userRef). -
Al recibir
Leave, elimina al usuario. -
Al recibir
Broadcast(sender, text), envía a todos los usuarios (menos al propiosender) un mensajeMessage(sender, text).
-
Resultados esperados (tests de alto nivel)
-
Crear un
RoomActory 3UserActor(Alice, Bob, Carol). -
Hacer que Alice y Bob se unan (
Join) primero, luego Carol. -
Enviar desde Alice a la sala
Broadcast("Alice", "Hola!").- Bob y Carol deberían recibir
Message("Alice", "Hola!"). - Alice no debe recibir su propio mensaje.
- Bob y Carol deberían recibir
-
Hacer que Bob salga (
Leave) y luego Alice vuelva aBroadcast("Alice", "¿Dónde está Bob?").- Solo Carol debe recibir ese mensaje.
-
Al final, cada
UserActordebe tener registrada una lista de mensajes recibidos que concuerde con lo anterior.
Ejercicio 3.2: Supervisión y reinicio de actores hijos
Consigna Construir dos actores:
-
WorkerActor: cada vez que reciba un mensaje
DoWork(n: Int), sin < 0lanza unRuntimeException("n negativo"); en otro caso, "procesa" imprimendoTrabajando con ny devuelveDone(n*2)al remitente. -
SupervisorActor: al iniciarse, crea un hijo
WorkerActory envía mensajesDoWorkal hijo. Debe usar unOneForOneStrategyque, si el hijo falla porRuntimeException, lo reinicie automáticamente.-
Mensajes que procesa:
StartWork(values: List[Int], replyTo: ActorRef)— itera sobre la lista y envía cadaDoWork(v)al hijo.Done(result: Int)— cuando recibe esta respuesta del hijo, acumula resultados en su estado.GetResults(replyTo: ActorRef)— envía alreplyTola lista de resultados acumulados.
-
Resultados esperados (tests de alto nivel)
-
Enviar a
SupervisorActorunStartWork(List(1, -1, 2), testProbeRef).DoWork(1)→ hijo respondeDone(2).DoWork(-1)→ hijo lanzaRuntimeException, se reinicia, no envíaDone.DoWork(2)→ hijo (estado limpio) respondeDone(4).
-
Al final, hacer
GetResults(testProbeRef). El supervisor debe devolver la lista[2, 4](es decir, se ignora el-1que causó la excepción). -
Verificar que el hijo fue reiniciado exactamente una vez (usar un contador en el Supervisor o testProbe que observe el ciclo de vida del hijo).
Ejercicio 3.3: Router de balanceo de carga (RoundRobinPool)
Consigna
Implementar un grupo de 5 actores trabajadores (“workers”) que resuelven operaciones simples (por ejemplo, cuadrados de
enteros). Usar un Router de tipo RoundRobinPool(5) para distribuir las solicitudes.
-
WorkerActor:
- Mensaje recibido:
ComputeSquare(n: Int, replyTo: ActorRef)→ responde conResult(n, n*n)alreplyTo.
- Mensaje recibido:
-
ClientActor:
- Al recibir
Start(numbers: List[Int], routerRef: ActorRef, replyTo: ActorRef), envía arouterRefunComputeSquarepara cada número de la lista. - Recibe múltiples
Result(n, square)y los acumula en unMap[Int,Int]en su estado. Cuando reciba tantos resultados como números envió, envíaAllResults(Map)areplyTo.
- Al recibir
Resultados esperados (tests de alto nivel)
- Crear un
RouterconRoundRobinPool(5)(Props[WorkerActor]). - Crear un
ClientActory enviarleStart(List(2,3,4,5), routerRef, testProbeRef). - El
ClientActorenvía 4 mensajesComputeSquareen secuencia: 2→worker1, 3→worker2, 4→worker3, 5→worker4 (round robin). - Usar un
TestProbecomoreplyTo. Al final, debe recibir un solo mensajeAllResults(Map(2→4,3→9,4→16,5→25)). - Opción adicional: verificar que cada
WorkerActorhaya procesado al menos un mensaje (con un contador interno oTestProbeen cada worker).
Ejercicio 3.4: Actores con estado y temporizadores (Periodic Ticker)
Consigna Crear un actor llamado TickerActor que cada cierto intervalo envíe un mensaje a sí mismo y, en cada tick, imprima la hora actual o incremente un contador interno.
-
Mensajes:
StartTick(interval: FiniteDuration)— arranca un ticker interno que cadaintervalenvía al propio actorTick.Tick(interno) — al recibirlo, incrementa un contadorcounty emite a todos los "suscriptores" (otros actores en una lista) un mensajeTicked(count).Subscribe(subscriberRef: ActorRef)— agregasubscriberRefa la lista de suscriptores.GetCount(replyTo: ActorRef)— responde con el valor actual decount.
Resultados esperados (tests de alto nivel)
- Crear
TickerActor, luego dos actores "listener" que se suscriben (Subscribe) antes de arrancar. - Enviar
StartTick(200.millis)aTickerActor. - Esperar 1 seg en el test. Los listeners deben recibir aproximadamente 5 mensajes
Ticked(1),Ticked(2), … hastaTicked(5). - Al enviar
GetCount(testProbeRef)alTickerActordespués de 1 seg, debe responder con (Count(5)). - Luego enviar
Subscribea un tercer listener y observar que, a partir de ese momento, el tercero también recibaTicked(6),Ticked(7), ….
Ejercicio 3.5: Persistencia simplificada (Stateful Actor con snapshots)
Consigna Simular un actor que mantiene un contador persistente en memoria (sin usar Akka Persistence); grabar periódicamente su estado a disco como "snapshot" (por ejemplo, serializando a un archivo local). A grandes rasgos:
-
PersistentCounterActor:
-
Mensajes:
Increment→ incrementa uncount: Inten memoria.GetValue(replyTo: ActorRef)→ envíaValue(count)alreplyTo.Snapshot→ cuando lo recibe, fuerza a serializar el valor decounta un archivo (p.ej./tmp/counter.snapshot).Recover→ lee el archivo/tmp/counter.snapshot(si existe) y recargacountcon ese valor.
-
-
Al arrancar, el actor recibe
Recoverautomáticamente (enpreStart). -
Cada 10 mensajes
Increment, el actor se envía a sí mismo unSnapshotpara persistir.
Resultados esperados (tests de alto nivel)
- Inicializar sin fichero de snapshot. Enviar 5×
Increment. LuegoGetValue(testProbe): debe responderValue(5). No hay snapshot todavía. - Enviar 5× más
Increment(total 10) → automáticamente el actor haceSnapshot(genera/tmp/counter.snapshotcon "10"). - Parar (detener) el actor, reiniciarlo y verificar que en
Recoverlea "10" →countarranca en 10. - Enviar 3×
Incrementy al hacerGetValue, debe darValue(13). - Borrar manualmente el archivo, reiniciar actor → en
Recoverno encuentra snapshot, arranca en0.
Parciales UBA
En esta sección voy a resolver algunos parciales de la materia de Técnicas de Programación Concurrente I de la Universidad de Buenos Aires, de la cátedra de Deymonnaz.
Link a la página de la materia
¿Por qué?
- El material y los contenidos son muy parecidos.
- Salvo por algunos contenidos:
- Ellos ven Redes de Petri mientras que nosotros no.
- Nosotros vemos Algoritmos No Bloqueantes y ellos no.
- Ellos ven Actores en Rust y usando la librería
tokio, mientras que nosotros lo vemos en Scala con Akka.
- Salvo por algunos contenidos:
- Ambas materias se dan en
Rustmayoritariamente. - No tenemos tantos parciales viejos como para practicar, así que capaz estos nos sirven.
Aclaraciones
- Los temas que no vimos en esta materia no los voy a incluir (ej: Redes de Petri, CUDA, Sockets).
- Como claramente no la cursé, probablemente hayan cosas que están mal, así que si ven algo que les haga ruido, avísenme.
- Todo lo relacionado a Actores lo voy a hacer en
ScalaconAkka.
Parciales
Parcial 1C 2024
Enunciado
1. Revisando el diseño aplicado en algunos proyectos, se encontró el uso de las siguientes herramientas para resolver problemas de concurrencia. Para cada uno de los problemas enuncie ventajas o desventajas de utilizar la solución propuesta y menciona cual utilizaría usted:
- Renderizado de videos 3D en alta resolución, utilizando programación asincrónica.
- Aplicación que arma una nube de palabras a partir de la API de Twitter, utilizando barriers y mutex.
- Una aplicación para realizar una votación en vivo para un concurso de televisión, optimizada con Vectorización.
2. Programación asincrónica. Elija verdadero o falso y explique brevemente por qué:
- El encargado de hacer poll es el thread principal del programa.
- El método poll es llamado únicamente cuando la función puede progresar.
- El modelo piñata es colaborativo.
- La operación asincrónica inicia cuando se llama a un método declarado con async.
3. Para cada uno de los siguientes fragmentos de código indique si es o no es un busy wait. Justifique en cada caso
Nota:
mineralybatteries_producedson locks.
#![allow(unused)] fn main() { for _ in 0..MINERS { let lithium = Arc::clone(&mineral); thread::spawn(move || loop { let mined = rand::thread_rng().gen(); let random_result: f64 = rand::thread_rng().gen(); *lithium.write().expect("failed to mine") += mined; thread::sleep(Duration::from_millis((5000 as f64 * random_result) as u64)); }) } }
#![allow(unused)] fn main() { for _ in 0 ..MINERS { let lithium = Arc::clone(&mineral); let batteries_produced = Arc::clone(&resources); thread::spawn(move || loop { let mut lithium = lithium.write().expect("failed"); if lithium >= 100 { lithium -= 100 ; batteries_produced.write().expect("failed to produce") += 1 } thread::sleep(Duration::from_millis( 500 )); }); } }
4. Dada la siguiente estructura, nombre si conoce una estructura de sincronización con el mismo comportamiento. Indique posibles errores en la implementación.
#![allow(unused)] fn main() { pub struct SynchronizationStruct { mutex: Mutex<i32>, cond_var: Condvar, } impl SynchronizationStruct { pub fn new(size: u16) -> SynchronizationStruct { SynchronizationStruct { mutex: Mutex::new(size), cond_var: Condvar::new(), } } pub fn function_1(&self) { let mut amount = self.mutex.lock().unwrap(); if *amount <= 0 { amount = self.cond_var.wait(amount).unwrap(); } *amount -= 1; } pub fn function_2(&self) { let mut amount = self.mutex.lock().unwrap(); *amount += 1; self.cond_var.notify_all(); } } }
5. Dados la siguiente red de Petri y fragmento de código, indique el nombre del problema que modelan. Indique si la implementación es correcta o describa cómo mejorarla.

fn main() { let sem = Arc::new(Semaphore::new(0)); let buffer = Arc::new(Mutex::new(Vec::with_capacity(N))); let sem_cloned = Arc::clone(&sem); let buf_cloned = Arc::clone(&buffer); let t1 = thread::spawn(move || { loop { // heavy computation let random_result: f64 = rand::thread_rng().gen(); thread::sleep(Duration::from_millis((500 as f64 * random_result) as u64)); buf_cloned.lock().expect("").push(random_result); sem_cloned.release() } }); let sem_cloned = Arc::clone(&sem); let buf_cloned = Arc::clone(&buffer); let t2 = thread::spawn(move || { loop { sem_cloned.acquire(); println!("{}", buf_cloned.lock().expect("").pop()); } }); t1.join().unwrap(); t2.join().unwrap(); }
Resolución
Primer ejercicio
Renderizado de videos 3D en alta resolución, usando asincronismo
La realidad es que no es la mejor opción, dado que el asincronismo es útil para tareas livianas. Como esto es una tarea de I/O bastante pesada, lo que más nos convendría es vectorización, que es el nombre formal para la transformación de tareas secuenciales a concurrentes que vimos en clase. (Ej: lo de partir el arreglo del merge sort y levantar un thread por cada mitad. Eso es vectorización)
Aplicación que arma una nube de palabras a partir de la API de Twitter, utilizando barriers y mutex
No tiene sentido usar barriers porque forzaría a mostrar todas las palabras al mismo tiempo, tampoco tiene sentido usar el mutex porque implicaría que solo una persona a la vez puede generar una palabra.
Lo mejor sería usar asincronismo, dado que son tareas livianas.
Una aplicación para realizar una votación en vivo para un concurso de televisión, optimizada con Vectorización
La vectorización no resuelve problemas de concurrencia, sino que acelera cálculos numéricos. Como la sección crítica del programa (en este caso) es la efectuación del voto, necesitamos usar cualquier approach relacionado al modelo de estado mutable compartido.
Por ejemplo, convendría usar monitores.
Segundo ejercicio
No lo voy a resolver porque es demasiado puntual de la librería de tokio.
Tercer ejercicio
- No es un busy wait, dado que trata de adquirir el lock para intentar escribir e inmediatamente duerme el thread, independientemente del resultado de la operación de escritura.
- Es un busy wait porque:
- Pregunta por el valor del litio antes de poder operar.
- Deja el thread bloqueado hasta que el recurso esté disponible y no hace nada en el mientras.
Cuarto ejercicio
Esta estructura es exactamente igual a un semáforo. function_1 es un down (adquisición de uno de los recursos del semáforo), y function_2 es un up (liberación de recurso)
Los errores que veo son:
- En
function_1el chequeo es unif, no unwhile. Esto permite que haya un cambio de contexto en el medio, y habilita a condiciones de carrera.- Además, la condición es incorrecta: si se despierta el hilo cuando
amountes 0, puedo llegar a tener un amount negativo (es decir, puedo tener recursos negativos).
- Además, la condición es incorrecta: si se despierta el hilo cuando
- En
function_2se llama anotify_all(). No tiene sentido despertar a absolutamente todos los threads para luego volverlos a poner en espera, cuando sólo uno va a adquirir el recurso. Invita a competencia por el recurso. Se resuelve simplemente cambiandonotify_all()pornotify_one()
Quinto ejercicio
Es una red de petri, no lo voy a hacer.
Parcial 2C 2024
Enunciado
1. Para cada uno de los siguientes fragmentos de código indique si es o no es un busy wait. Justifique en cada caso. 1.
#![allow(unused)] fn main() { fn busy_wait_1() { loop { match TcpStream::connect("127.0.0.1:8080") { Ok(mut stream) => { stream.write_all(message.as_bytes()).expect("Error") } Err(_) => { let random_result: f64 = rand::thread_rng().gen(); thread::sleep( Duration::from_millis((5000f64 * random_result) as u64) ); } } } } }
#![allow(unused)] fn main() { fn busy_wait_2() { let random_result: f64 = rand::thread_rng().gen(); thread::sleep(Duration::from_millis(random_result as u64)) let mut items = self.pending_acks.lock().unwrap(); let now = Instant::now(); let mut i = 0; while i < items.len() { if items[i].expiration <= now { if items[i].item_type == "ACK" { let _ = items.remove(i); drop(items); self.send_result_interfaces(); break; } } else { i += 1 } } } }
#![allow(unused)] fn main() { fn busy_wait_3(){ let copper = Arc::clone(&resource); thread::spawn(move || loop { let mined_amount = rand::thread_rng().gen_range(1..10); *copper.write().expect("failed to mine") += mined_amount; let delay = rand::thread_rng().gen_range(3000..7000); thread::sleep(Duration::from_millis(delay)); }); } }
2. Modelar una Red de Petri para el problema del Lector-Escritor sin preferencia. Luego, modele una solución que contemple preferencia de escritura.
3. Se quiere abrir un restaurante en el barrio de San Telmo. Se espera que los clientes lleguen y sean atendidos por alguno de los mozos de turno, cada uno de los cuales tomará los pedidos de cada mesa, los notificará a la cocina y luego seguirá tomando otros pedidos.
Como la cocina es chica los cocineros pueden entrar a buscar los ingredientes al depósito de a uno a la vez, y buscar entre los distintos alimentos les puede llevar un tiempo variable.
Cuando los cocineros hayan terminado de preparar un pedido deben notificar a los mozos para que lo lleven a la mesa. Además, los mozos deben estar disponibles para cobrarle a los clientes.
Diseñe el sistema utilizando el modelo de actores, y para cada entidad defina cuáles son los estados internos y los mensajes que intercambian.
4. Verdadero o Falso. Justifique:
- a. Procesos, hilos y tareas asincrónicas poseen espacios de memoria independientes.
- b. El scheduler del sistema operativo puede detener una tarea asincrónica puntual y habilitar la ejecución de otra para el mismo proceso.
- c. Tanto los threads, como las tareas asincrónicas disponen de un stack propio.
- d. En un ambiente de ejecución con una única CPU, un conjunto de hilos de procesamiento intensivo tomarán un tiempo de ejecución significativamente menor a un conjunto de tareas asincrónicas que ejecuten el mismo procesamiento.
5. Describa y justifique con qué modelo de concurrencia modelaría la implementación para cada uno de los siguientes casos de uso:
- a. Convertir un conjunto extenso de archivos de .DOC a .PDF
- b. El backend para una aplicación de preguntas & respuestas competitiva al estilo Menti o Kahoot.
- c. Una memoria caché utilizada para reducir la cantidad de requests en un servidor web a una base de datos.
- d. Una API HTTP que ejecuta un modelo de procesamiento de lenguaje natural para clasificar el sentimiento de un mensaje.
Resolución
Primer ejercicio
- Es un busy wait. Si le llega un stream por TCP, le genera una respuesta. Si no, duerme el thread hasta poder volver a intentar. Intenta hasta generar una respuesta,.
- Es un busy wait. Además de que es una implementación ineficiente (porque duerme el thread de manera innecesaria una cantidad de tiempo aleatoria), se queda esperando e iterando indefinidamente por el estado de los ACKs pendientes. Nunca droppea el lock para que otro thread pushee un ACK al arreglo.
- No es un busy wait, no pregunta por el estado del cobre, sino que independientemente del resultado (es decir, si pudo adquirir el lock para ejecutar o no), duerme el thread para no seguir consumiendo recursos.
Segundo ejercicio
Red de Petri, skippeado
Tercer ejercicio
Si quieren háganlo, tengo una idea de cómo hacerlo pero no lo pienso hacer. Es un bodrio.
Cuarto ejercicio
a) Falso. Cada proceso tiene su propio espacio de memoria; los hilos usan y comparten el espacio de memoria de su proceso padre, y las tareas asincrónicas son "hilos más ligeros", por lo que también usan el mismo espacio de memoria.
b) Falso. (La justificación es muy puntual de cómo funcionan las tasks en Rust).
En nuestro caso... Sería verdadera. Esto tiene que ver con el scheduling preventivo, que constaba de que un proceso puede ser interrumpido o terminado en un momento dado por parte del scheduler. Las tareas asíncronas tienen el mismo comportamiento.
c) Falso. Las tasks comparten el stack del proceso/hilo padre.
d) Falso. El cambio de contexto entre hilos es más pesado que el de las tareas.
Quinto ejercicio
- a. Convertir un conjunto extenso de archivos de .DOC a .PDF
- Usaría vectorización, tanto para la cantidad de archivos como por si los archivos son demasiado grandes. Como en el TP de Grep.
- b. El backend para una aplicación de preguntas & respuestas competitiva al estilo Menti o Kahoot.
- Usaría asincronismo, dado que las preguntas y respuestas son rápidas y ligeras. No necesito estar escuchando
 constantemente
constantemente
- Usaría asincronismo, dado que las preguntas y respuestas son rápidas y ligeras. No necesito estar escuchando
- c. Una memoria caché utilizada para reducir la cantidad de requests en un servidor web a una base de datos.
- Usaría un RwLock, o un Monitor, dado que estás accediendo a estado mutable compartido constantemente.
- d. Una API HTTP que ejecuta un modelo de procesamiento de lenguaje natural para clasificar el sentimiento de un mensaje.
- Es una API, necesitás usar asincronismo sí o sí. No hay ninguna API HTTP que no ejecute requests asincrónicas.